文章目录
1. 信息量与熵
信息量:它用来衡量一个事件的不确定性。一个事件发生的概率越大,不确定性越小,则它所携带的信息量就越小。
【数学直观理解】假设 X X X 是一个离散型随机变量,取值集合为 X X X,概率分布函数为 p ( x ) = P ( X = x ) , x ∈ X p(x)=P(X=x),x \in X p(x)=P(X=x),x∈X。
定义事件 X = x 0 X=x_0 X=x0 的信息量为 I ( x 0 ) = − l o g ( p ( x 0 ) ) I(x_0)=-log(p(x_0)) I(x0)=−log(p(x0)),当 p ( x 0 ) = 1 p(x_0)=1 p(x0)=1时,也就是事件发生概率为1,信息量将等于0,也就是说该事件的发生不会导致任何信息量的增加。
熵(信息熵):用来衡量一个系统的混乱程度,量化信息的不确定性。它代表一个系统中信息量的总和,信息量总和越大,表明这个系统的不确定性就越大。
如何度量?对所有可能事件所带来的信息量求期望。
对于随机变量 X X X,其概率分布 P P P 如下所示:

那么该随机变量
X
X
X 的熵值定义如下:
H
(
X
)
=
−
∑
i
=
1
n
p
(
x
i
)
log
p
(
x
i
)
\begin{aligned} H(X)=-\sum_{i=1}^n p(x_i)\log p(x_i) \end{aligned}
H(X)=−i=1∑np(xi)logp(xi)
- 当 p ( x i ) = 0 p(x_i)=0 p(xi)=0时,定义 H ( X ) = 0. ( lim x → 0 + x log x = 0 ) H(X)=0.\ (\lim_{x\to 0+} x \log x = 0) H(X)=0. (limx→0+xlogx=0)
- 熵越大,随机变量的不确定性就越大。 当每个概率都一样,即 p ( x i ) p(x_i) p(xi)都相等时,熵最大为 H ( X ) = log n H(X)=\log n H(X)=logn.
- 0 ≤ H ( P ) ≤ log n 0 \le H(P) \le \log n 0≤H(P)≤logn
【e.g.】 存在三个容器,每一个容器里面都含有两种元素:三角形和圆形,哪一个容器的确定性最高?
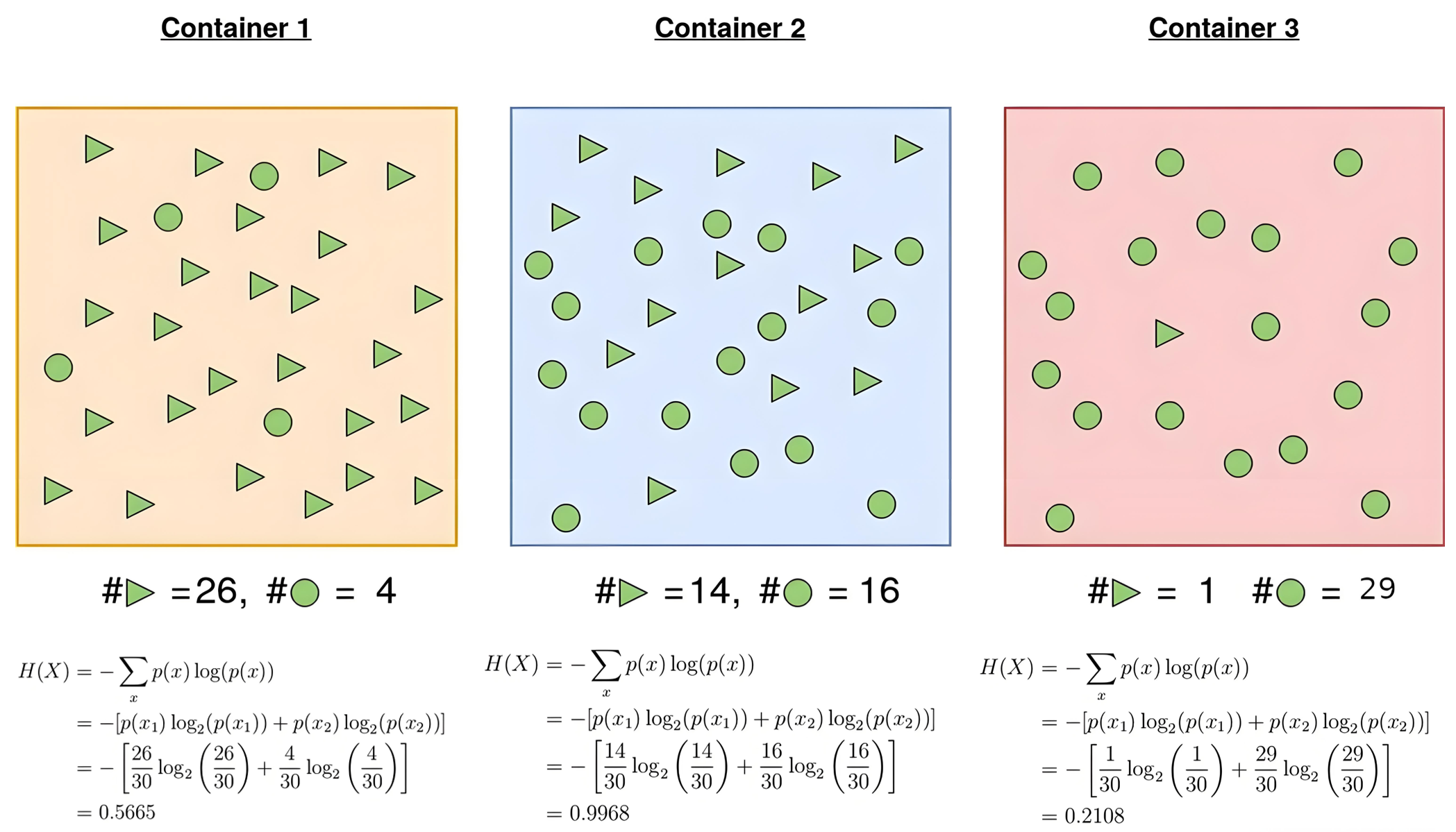
很显然,容器3的熵值最小,确定性最大。这个结果也十分符合常理,容器3中有29个圆形,1个三角形,内部信息是相对稳定的。
2. 交叉熵(Cross-Entropy)
2.1 交叉熵的定义
如果说熵是衡量一个随机变量分布内在不确定性的指标,那 交叉熵就是衡量两个概率分布(真实分布和预测分布)之间差异的指标。
对于给定的 真实分布
P
P
P 和 预测分布
Q
Q
Q,交叉熵 定义为:
H
(
P
,
Q
)
=
−
∑
x
P
(
x
)
log
Q
(
x
)
H(P,Q)=-\sum_x P(x)\log Q(x)
H(P,Q)=−x∑P(x)logQ(x)
【e.g.】 以分类任务为例。如图所示,一张图像经过神经网络处理,softmax函数处理得到概率分布 [0.775, 0.116, 0.039, 0.070] (预测概率分布):
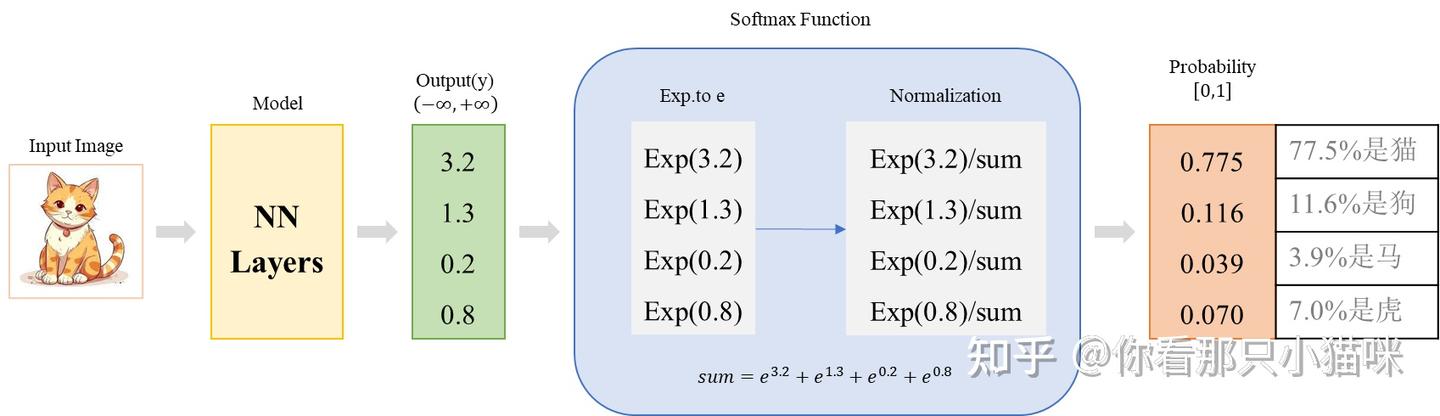
这张图像真实对应的类别向量为 [1, 0, 0, 0] (真实概率分布)。
模型预测的概率分布和真实概率分布之间的差异有多大呢?可以用交叉熵来衡量。
L
C
E
=
−
∑
i
=
1
4
t
i
log
(
p
i
)
=
−
[
1
∗
log
(
0.775
)
+
0
∗
log
(
0.116
)
+
0
∗
log
(
0.039
)
+
0
∗
log
(
0.070
)
]
=
0.3677
\begin{aligned} L_{CE}=&-\sum_{i=1}^4 t_i \log(p_i) \\ &=-[1*\log(0.775)+0*\log(0.116)+0*\log(0.039)+0*\log(0.070)] \\ &=0.3677 \end{aligned}
LCE=−i=1∑4tilog(pi)=−[1∗log(0.775)+0∗log(0.116)+0∗log(0.039)+0∗log(0.070)]=0.3677

这是对于一个样本的交叉熵损失函数值,如果有
N
N
N个样本,则最终的函数值为
N
N
N个样本的损失值 累加求平均:
L
C
E
=
−
1
N
∑
i
=
1
N
∑
k
=
1
K
t
i
k
log
(
p
i
k
)
L_{CE} = -\frac{1}{N}\sum_{i=1}^N\sum_{k=1}^Kt_{ik}\log(p_{ik})
LCE=−N1i=1∑Nk=1∑Ktiklog(pik)
2.2 二分类问题中的交叉熵
对于二分类问题,交叉熵损失函数可以简化为:
L
=
−
[
y
log
y
^
+
(
1
−
y
)
log
(
1
−
y
^
)
]
L=-[y\log \hat y + (1-y)\log (1- \hat y)]
L=−[ylogy^+(1−y)log(1−y^)]
其中, y y y 是真实标签,取值为0或1。 y ^ \hat y y^是模型预测的概率,范围在(0,1)之间。
- 当真实标签 y = 1 y=1 y=1 时, L = − [ log y ^ ] L=-[\log \hat y] L=−[logy^],这表示如果真实标签是正类,我们只关心模型预测正类的概率 y ^ \hat y y^,希望它越接近于1越好。
- 当真实标签 y = 0 y=0 y=0 时, L = − [ log ( 1 − y ^ ) ] L=-[\log(1 - \hat y)] L=−[log(1−y^)],这表示如果真实标签是负类,我们只关心模型预测负类的概率 1 − y ^ 1-\hat y 1−y^,希望它越接近1越好。
2.3 多分类问题中的交叉熵
对于有 K K K 个类别的多分类问题,交叉熵损失函数为:
L = − ∑ i = 1 N ∑ k = 1 K y i k log ( y ^ i k ) L=-\sum_{i=1}^N \sum_{k=1}^Ky_{ik} \log (\hat y_{ik}) L=−i=1∑Nk=1∑Kyiklog(y^ik)
其中, N N N 为样本总数, y i y_i yi是真实的类别分布,使用one-hot编码。 y ^ \hat y y^ 是模型预测的第 i i i 个类别的概率,通常通过softmax函数获得,满足 ∑ i = 1 K y ^ i = 1 \sum_{i=1}^K \hat y_i =1 ∑i=1Ky^i=1.
上一节介绍的例子就是多分类的情况。
3. 交叉熵与KL散度
3.1 KL散度定义
KL散度(Kullback–Leibler Divergence) 又称为 相对熵(Relative entropy),是对两个概率分布间差异的非对称性度量,即表示的是一个概率分布相对于另一个概率分布的差异程度。
设 P ( x ) P(x) P(x), Q ( x ) Q(x) Q(x) 是随机变量 X X X 上的两个概率分布, P ( x ) P(x) P(x) 是真实分布, Q ( x ) Q(x) Q(x) 是拟合分布(预测分布)。
在离散随机变量的情形下,
P
P
P 相对于
Q
Q
Q 的KL散度定义为:
K
L
(
P
∥
Q
)
=
∑
P
(
x
)
log
P
(
x
)
Q
(
x
)
=
−
∑
P
(
x
)
log
Q
(
x
)
+
∑
P
(
x
)
log
P
(
x
)
=
H
(
P
,
Q
)
−
H
(
P
)
\begin{aligned} KL(P \parallel Q)&=\sum P(x) \log \frac{P(x)}{Q(x)} \\ &= - \sum P(x) \log Q(x) + \sum P(x) \log P(x)\\ &= H(P,Q) - H(P) \end{aligned}
KL(P∥Q)=∑P(x)logQ(x)P(x)=−∑P(x)logQ(x)+∑P(x)logP(x)=H(P,Q)−H(P)
KL散度可以表示为交叉熵
H
(
P
,
Q
)
H(P,Q)
H(P,Q) 与真实数据分布的熵
H
(
P
)
H(P)
H(P) 的差。
在分类问题中,最小化KL散度等价于最小化交叉熵损失,因为数据集的熵
H
(
P
)
H(P)
H(P)是个定值,即训练数据的分布是固定的。
在连续随机变量的情形下,
P
P
P 相对于
Q
Q
Q 的KL散度定义为:
K
L
(
P
∥
Q
)
=
∫
P
(
x
)
log
P
(
x
)
Q
(
x
)
d
x
KL(P \parallel Q)= \int P(x) \log \frac{P(x)}{Q(x)} dx
KL(P∥Q)=∫P(x)logQ(x)P(x)dx
通俗来说, P ( x ) P(x) P(x) 是真实分布(true distribution), Q ( x ) Q(x) Q(x) 是一个用于拟合真实分布的近似分布(approximate distribution),通过尝试修改 Q ( x ) Q(x) Q(x) 使得两者之间的 K L ( P ∥ Q ) KL(P \parallel Q) KL(P∥Q)尽可能小,来实现 用 Q ( x ) Q(x) Q(x) 拟合 P ( x ) P(x) P(x).
因此,KL散度并不是对称的,衡量的是如果用分布 Q Q Q 来替代真实分布 P P P,我们会额外损失多少信息。KL散度越大,说明 Q Q Q 和 P P P 之间的差异越大。
3.2 两类KL散度(了解)
在上面这个概率拟合的应用场景下(即确定了真实分布 P ( x ) P(x) P(x)和拟合分布 Q ( x ) Q(x) Q(x)两个角色之后),有前向KL散度和反向KL散度的定义:
- K L ( P ∥ Q ) KL(P \parallel Q) KL(P∥Q) 前向KL散度(forward KL Divergence)
- K L ( Q ∥ P ) KL(Q \parallel P) KL(Q∥P) 反向KL散度(reverse KL Divergence)
需要注意的是,只有确定了概率拟合的应用场景,这样的定义才是有意义的,否则两个公式只是改变符号表示之后的平凡结果。
【e.g.】 假设真实分布 P P P 是混合高斯分布,由两个高斯分布的分量组成。
\quad\quad\quad
希望用普通的高斯分布
Q
Q
Q 来近似
P
P
P ,则有两种方案:
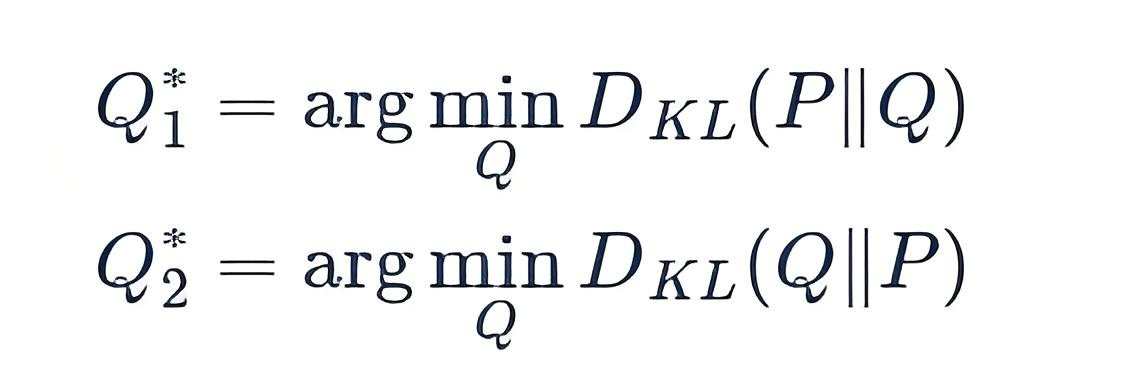
拟合效果如下图所示:
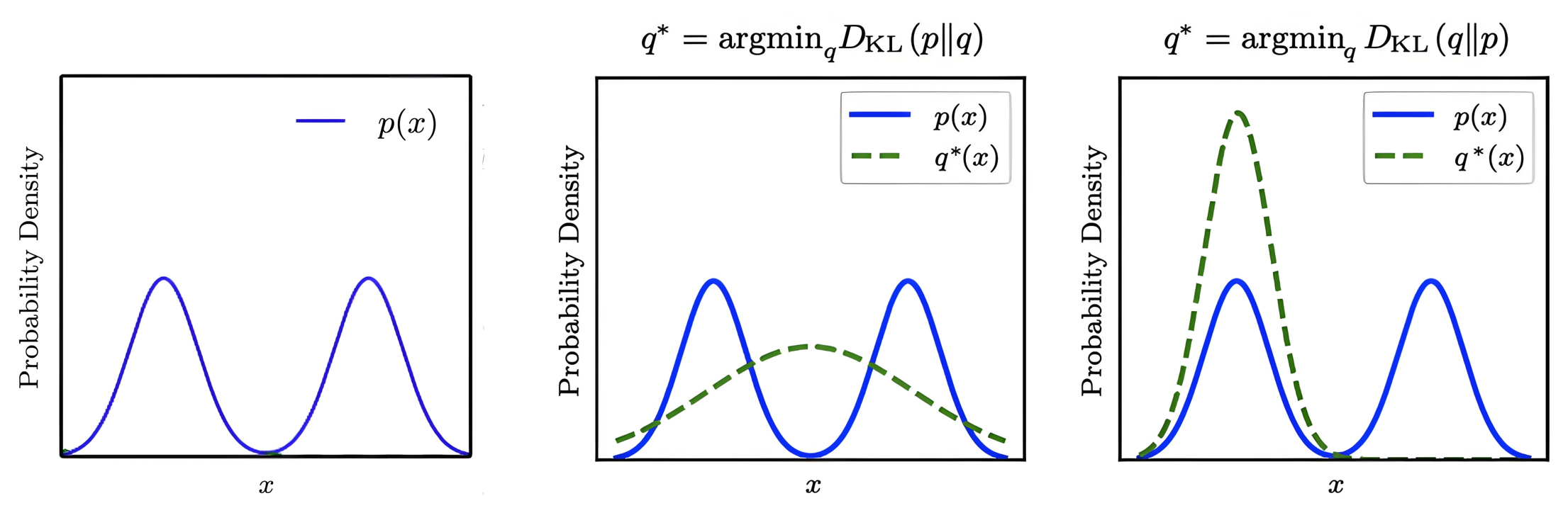
选择 Q 1 ∗ Q_1^* Q1∗:极小化前向KL损失下的拟合行为特性:寻找均值(Mean-Seeking Behaviour)
- 当 P ( x ) P(x) P(x) 较大的时候 Q ( x ) Q(x) Q(x) 也必须较大。如果 P ( x ) P(x) P(x) 较大时 Q ( x ) Q(x) Q(x) 较小,则 P ( x ) log P ( x ) Q ( x ) P(x) \log \frac{P(x)}{Q(x)} P(x)logQ(x)P(x)较大。
- 当 P ( x ) P(x) P(x) 较小的时候 Q ( x ) Q(x) Q(x) 可以较大,也可以较小,因此 Q 1 Q_1 Q1会贴近 P ( x ) P(x) P(x) 的峰值。由于峰值有两个,因此 Q 1 Q_1 Q1 无法偏向任意一个峰值,最终结果就是 其峰值在 P ( x ) P(x) P(x) 的两个峰值之间,如图中第二张图片所示。
选择 Q 2 ∗ Q_2^* Q2∗:极小化反向KL损失下的拟合行为特性:搜寻模态(Mode-Seeking Behaviour)
- 当 P ( x ) P(x) P(x) 较小的时候, Q ( x ) Q(x) Q(x) 必须较小。如果 P ( x ) P(x) P(x) 较小时 Q ( x ) Q(x) Q(x) 较大,则 Q ( x ) log Q ( x ) P ( x ) Q(x) \log \frac{Q(x)}{P(x)} Q(x)logP(x)Q(x)较大。
- 当 P ( x ) P(x) P(x) 较大的时候, Q ( x ) Q(x) Q(x) 可以较大,也可以较小。因此 Q 2 Q_2 Q2 会贴近 P ( x ) P(x) P(x) 的谷值。最终结果就是会贴合 P ( x ) P(x) P(x) 峰值的任何一个。
【其他示例】 图(a)是拟合代价选择前向KL散度,图(b)和图©拟合代价选择反向KL散度(使用相同代价,但到达代价的不同局部极小值点的结果)。
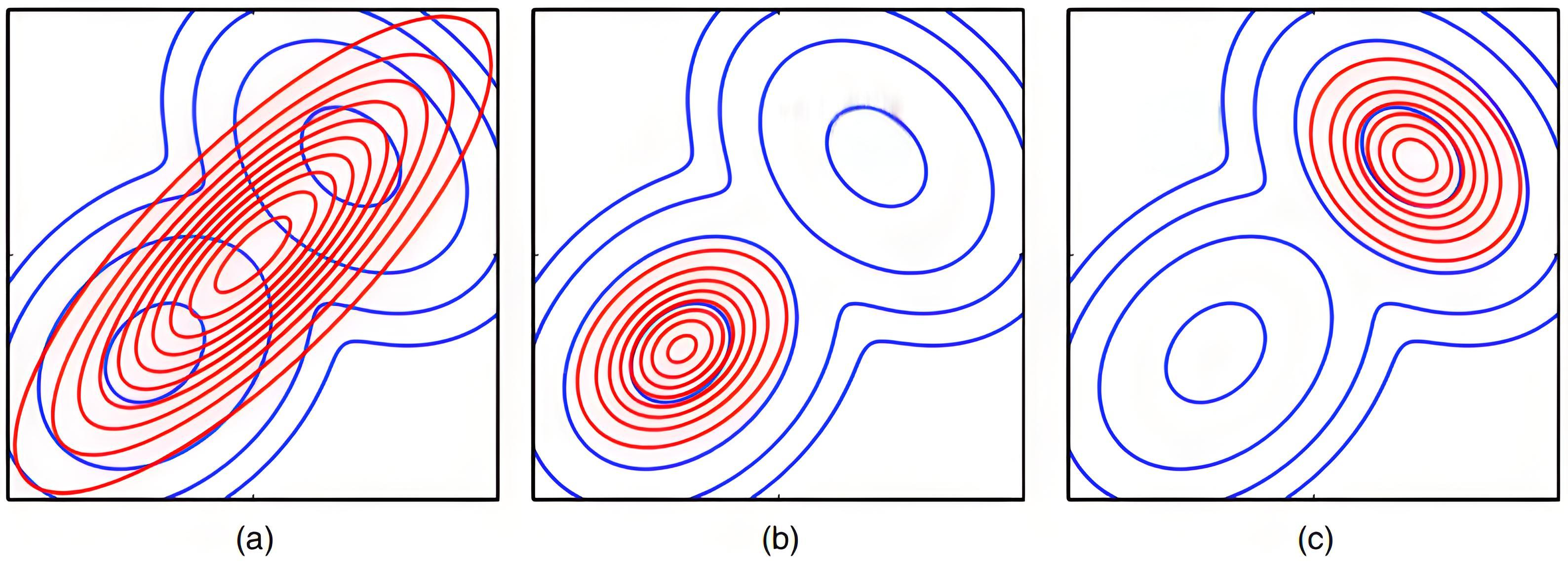
一般绝大多数场合使用 K L ( P ∥ Q ) KL(P \parallel Q) KL(P∥Q),因为当我们用分布 Q Q Q 拟合 P P P 时,我们希望对于常见的事件二者概率相差不大。
References
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 交叉熵【Cross Entropy】与KL散度【Kullback-Leibler Divergence】

发表评论 取消回复