目录
端到端精确一次(End-To-End Exactly-Once)
状态一致性
流式计算本身就是一个一个进行的,所以正常处理的过程中结果肯定是正确的,但在发生故障、需要恢复回滚时就需要更多的保障机制。我们通过检查点的保存来保证状态恢复后计算结果的正确。
状态一致性其实就是结果的正确性,一般从数据丢失、数据重复来评估。
一般说来,状态一致性有三种级别:
- 最多一次(At-Most-Once)
- 至少一次(At-Least-Once)
- 精确一次(Exactly-Once)
端到端的状态一致性
我们已经知道检查点可以保证Flink内部状态的一致性,而且可以做到精确一次。在实际应用中,不仅仅要确保Flink内部状态的正确性,我们需要确保整个应用处理流程从头到尾都应该是正确的,才能得到整体结果的正确性。
完整的流处理应用,包括数据源、流处理器和外部存储系统三个部分。这个完整应用的一致性,就叫做“端到端(end-to-end)的状态一致性”,它取决于三个组件中最弱的那一环。
一般来说,能否达到at-least-once一致性级别,主要看数据源能够重放数据,而能否达到exactly-once级别,流处理器内部、数据源、外部存储都要有相应的保证机制。
端到端精确一次(End-To-End Exactly-Once)
最难做到、也最希望做到的一致性语义就是端到端(end-to-end)的“精确一次”。
Flink内部的Exactly-Once
对于Flink内部来说,检查点机制可以保证故障恢复后数据不丢(在数据能够重放的前提下),已经可以做到exactly-once的一致性语义了。
所以端到端一致性的关键点,就在于输入的数据源端(Source)和输出的外部存储端(Sink)。
输入端保证
输入端主要指的就是Flink读取的外部数据源。对于一些数据源来说,并不提供数据的缓冲或是持久化保存,数据被消费之后就彻底不存在了,例如socket文本流。对于这样的数据源,故障后我们即使通过检查点恢复之前的状态,可保存检查点之后到发生故障期间的数据已经不能重发了,这就会导致数据丢失。所以就只能保证at-most-once的一致性语义,相当于没有保证。
想要在故障恢复后不丢数据,外部数据源就必须拥有重放数据的能力。常见的做法就是对数据进行持久化保存,并且可以重设数据的读取位置。一个最经典的应用就是Kafka。在Flink的Source任务中将数据读取的偏移量保存为状态,这样就可以在故障恢复时从检查点中读取出来,对数据源重置偏移量,重新获取数据。
数据源可重放数据,或者说可重置读取数据偏移量,加上Flink的Source算子将偏移量作为状态保存进检查点,就可以保证数据不丢。这是达到at-least-once一致性语义的基本要求,当然也是实现端到端exactly-once的基本要求。
输出端保证
有了Flink的检查点机制,以及可重放数据的外部数据源,我们已经能做到at-least-once了。但是想要实现exactly-once却还有更大的困难:数据有可能重复写入外部系统。
因为检查点保存之后,继续到来的数据也会一一处理,任务的状态也会更新,最终通过Sink任务将计算结果输出到外部系统;只是状态改变还没有存到下一个检查点中。这时如果出现故障,这些数据都会重新来一遍,就计算了两次。我们知道对Flink内部状态来说,重复计算的动作是没有影响的,因为状态已经回滚,最终改变只会发生一次;但对于外部系统来说,已经写入的结果已经无法收回了,再次执行写入就会把同一个数据写入两次。
所以这时,保证了端到端的at-least-once语义。
为了实现端到端exactly-once,我们还需要对外部存储系统、以及Sink连接器有额外的要求。能够保证exactly-once一致性的写入方式有两种:
- 幂等写入
- 事务写入
幂等写入
所谓“幂等”操作,就是说一个操作可以重复执行很多次,但只导致一次结果更改。也就是说,后面再重复执行就不会对结果起作用了,或者说后面的结果和之前的结果保持一致。
对于幂等写入,遇到故障进行恢复时,有可能会出现短暂的不一致。不过当数据的重放逐渐超过发生故障的点的时候,最终的结果还是一致的。
事务写入
事务是应用程序中一系列的操作,事务中所有操作要么全部完成,要么全部不完成。
输出端最大的问题,就是写入到外部系统的数据难以撤回。而利用事务就可以实现对已写入数据的撤回。
事务写入的基本思想就是:用一个事务来进行数据向外部系统的写入,这个事务是与检查点绑定在一起的。当Sink任务遇到barrier时,开始保存状态的同时就开启一个事务,接下来所有数据的写入都在这个事务中;待到当前检查点保存完毕时,将事务提交,所有写入的数据就真正可用了。如果中间过程出现故障,状态会回退到上一个检查点,而当前事务没有正常关闭(因为当前检查点没有保存完),所以也会回滚,写入到外部的数据就被撤销了。
具体来说,又有两种实现方式:预写日志(WAL)和两阶段提交(2PC)
(1)预写日志(write-ahead-log,WAL)
事务提交是需要外部存储系统支持事务的,否则没有办法真正实现写入的回撤。
那对于一般不支持事务的存储系统,如何能够实现事务写入呢? 预写日志(WAL)就是一种非常简单的方式。
具体步骤是:
①先把结果数据作为日志(log)状态保存起来,保持在状态后端中。
②进行检查点保存时,也会将这些结果数据一并做持久化存储。
③在收到检查点完成的通知时,将所有结果一次性写入外部系统。
④在成功写入所有数据后,在内部再次确认相应的检查点,将确认信息也进行持久化保存。这才代表着检查点的真正完成。
我们会发现,这种方式类似于检查点完成时做一个批处理,一次性的写入会带来一些性能上的问题;而优点就是比较简单,由于数据提前在状态后端中做了缓存,所以无论什么外部存储系统,理论上都能用这种方式一批搞定。
在Flink中DataStream API提供了一个模板类GenericWriteAheadSink,用来实现这种事务型的写入方式。
需要注意的是,预写日志这种一批写入的方式,有可能会写入失败;所以在执行写入动作之后,必须等待发送成功的返回确认消息。在成功写入所有数据后,在内部再次确认相应的检查点,这才代表着检查点的真正完成。这里需要将确认信息也进行持久化保存,在故障恢复时,只有存在对应的确认信息,才能保证这批数据已经写入,可以恢复到对应的检查点位置。
但这种“再次确认”的方式,也会有一些缺陷。如果我们的检查点已经成功保存、数据也成功地一批写入到了外部系统,但是最终保存确认信息时出现了故障,Flink最终还是会认为没有成功写入。于是发生故障时,不会使用这个检查点,而是需要回退到上一个;这样就会导致这批数据的重复写入。
(2)两阶段提交(two-phase-commit,2PC)
前面提到的各种实现exactly-once的方式,多少都有点缺陷;而更好的方法就是传说中的两阶段提交(2PC)。 顾名思义,它的想法是分成两个阶段:先做“预提交”,等检查点完成之后再正式提交。这种提交方式是真正基于事务的,它需要外部系统支持事务。
具体的实现步骤为:
①当第一条数据到来时,或者收到检查点的分界线时(第一条数据到达会启动一个事物,之后都是用分界线到达启动一个事物),Sink任务都会启动一个事务。
②接下来接收到的所有数据,都通过这个事务直接写入外部系统;这时由于事务没有提交,所以数据尽管写入了外部系统,但是不可用,是“预提交”的状态。
③当Sink任务收到JobManager发来检查点完成的通知时,正式提交事务,写入的结果就真正可用了。
当中间发生故障时,当前未提交的事务就会回滚,于是所有写入外部系统的数据也就实现了撤回。
这种两阶段提交(2PC)的方式充分利用了Flink现有的检查点机制:分界线的到来,就标志着开始一个新事务;而收到来自JobManager的checkpoint成功的消息,就是提交事务的指令。每个结果数据的写入,依然是流式的,不再有预写日志时批处理的性能问题;最终提交时,也只需要额外发送一个确认信息。所以2PC协议不仅真正意义上实现了exactly-once,而且通过搭载Flink的检查点机制来实现事务,只给系统增加了很少的开销。
Flink提供了TwoPhaseCommitSinkFunction接口,方便我们自定义实现两阶段提交的SinkFunction的实现,提供了真正端到端的exactly-once保证。不过两阶段提交虽然精巧,却对外部系统有很高的要求。这里将2PC对外部系统的要求列举如下:
外部系统必须提供事务支持,或者Sink任务必须能够模拟外部系统上的事务。
在检查点的间隔期间里,必须能够开启一个事务并接受数据写入。
在收到检查点完成的通知之前,事务必须是“等待提交”的状态。在故障恢复的情况下,这可能需要一些时间。如果这个时候外部系统关闭事务(例如超时了),那么未提交的数据就会丢失。
Sink任务必须能够在进程失败后恢复事务。
提交事务必须是幂等操作。也就是说,事务的重复提交应该是无效的。
可见,2PC在实际应用同样会受到比较大的限制。具体在项目中的选型,最终还应该是一致性级别和处理性能的权衡考量。
Flink和Kafka连接时的精确一次保证
在流处理的应用中,最佳的数据源当然就是可重置偏移量的消息队列了;它不仅可以提供数据重放的功能,而且天生就是以流的方式存储和处理数据的。所以作为大数据工具中消息队列的代表,Kafka可以说与Flink是天作之合,实际项目中也经常会看到以Kafka作为数据源和写入的外部系统的应用。在本小节中,我们就来具体讨论一下Flink和Kafka连接时,怎样保证端到端的exactly-once状态一致性。
整体介绍
既然是端到端的exactly-once,我们依然可以从三个组件的角度来进行分析:
(1)Flink内部 Flink内部可以通过检查点机制保证状态和处理结果的exactly-once语义。
(2)输入端 输入数据源端的Kafka可以对数据进行持久化保存,并可以重置偏移量(offset)。所以我们可以在Source任务(FlinkKafkaConsumer)中将当前读取的偏移量保存为算子状态,写入到检查点中;当发生故障时,从检查点中读取恢复状态,并由连接器FlinkKafkaConsumer向Kafka重新提交偏移量,就可以重新消费数据、保证结果的一致性了。
(3)输出端 输出端保证exactly-once的最佳实现,当然就是两阶段提交(2PC)。作为与Flink天生一对的Kafka,自然需要用最强有力的一致性保证来证明自己。
也就是说,我们写入Kafka的过程实际上是一个两段式的提交:处理完毕得到结果,写入Kafka时是基于事务的“预提交”;等到检查点保存完毕,才会提交事务进行“正式提交”。如果中间出现故障,事务进行回滚,预提交就会被放弃;恢复状态之后,也只能恢复所有已经确认提交的操作。
需要的配置
在具体应用中,实现真正的端到端exactly-once,还需要有一些额外的配置:
(1)必须启用检查点
(2)指定KafkaSink的发送级别为DeliveryGuarantee.EXACTLY_ONCE
(3)配置Kafka读取数据的消费者的隔离级别
这里所说的Kafka,是写入的外部系统。预提交阶段数据已经写入,只是被标记为“未提交”(uncommitted),而Kafka中默认的隔离级别isolation.level是read_uncommitted,也就是可以读取未提交的数据。所以应该将隔离级别配置 为read_committed,表示消费者遇到未提交的消息时,会停止从分区中消费数据,直到消息被标记为已提交才会再次恢复消费。当然,这样做的话,外部应用消费数据就会有显著的延迟。
(4)事务超时配置
Flink的Kafka连接器中配置的事务超时时间transaction.timeout.ms默认是1小时,而Kafka集群配置的事务最大超时时间transaction.max.timeout.ms默认是15分钟。所以在检查点保存时间很长时,有可能出现Kafka已经认为事务超时了,丢弃了预提交的数据;而Sink任务认为还可以继续等待。如果接下来检查点保存成功,发生故障后回滚到这个检查点的状态,这部分数据就被真正丢掉了。所以这两个超时时间,前者应该小于等于后者。
案例
该案例完成从Kafka的topic_1主题中读取源数据,Flink进行数据处理,处理完成后把数据发送到Kafka的ws主题中。
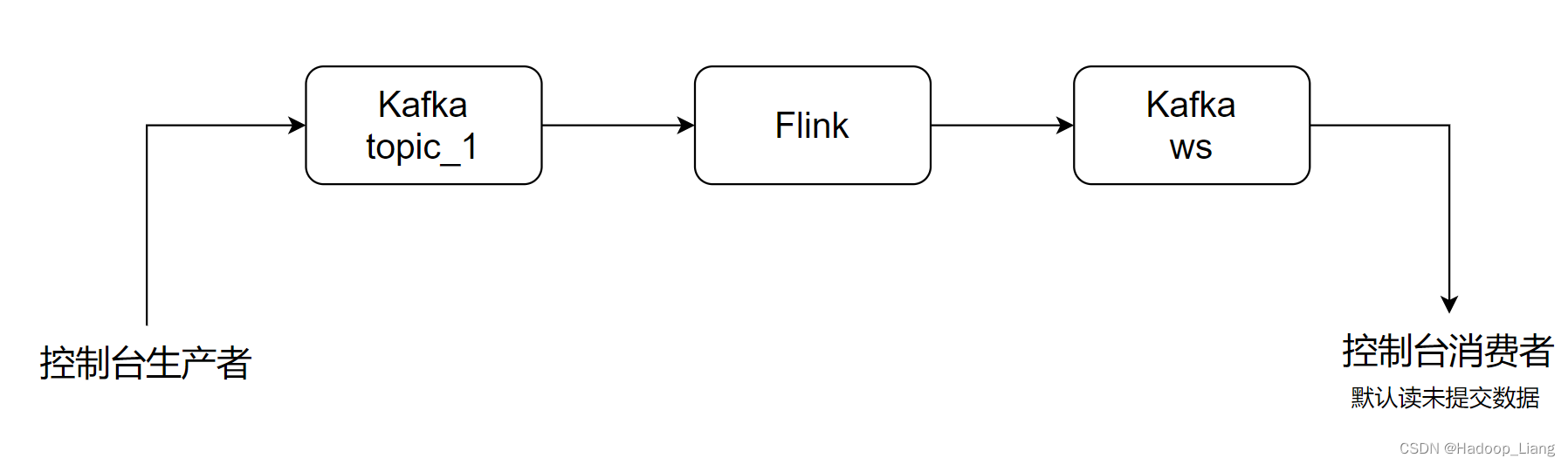
案例代码可以在Flink Stream API实践 的基础上进行。
添加依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>Flink 代码
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.kafka.clients.producer.ProducerConfig;
import java.time.Duration;
public class KafkaEOSDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 代码中用到hdfs,需要导入hadoop依赖、指定访问hdfs的用户名
System.setProperty("HADOOP_USER_NAME", "hadoop");
// 启用检查点,设置为精准一次,hdfs namenode主机和端口号注意根据实际情况修改
env.enableCheckpointing(5000, CheckpointingMode.EXACTLY_ONCE);
CheckpointConfig checkpointConfig = env.getCheckpointConfig();
checkpointConfig.setCheckpointStorage("hdfs://node2:9820/chk");
checkpointConfig.setExternalizedCheckpointCleanup(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// 读取kafka数据
KafkaSource<String> kafkaSource = KafkaSource.<String>builder()
.setBootstrapServers("node2:9092,node3:9092,node4:9092")
.setGroupId("test")
.setTopics("topic_1")
.setValueOnlyDeserializer(new SimpleStringSchema())
.setStartingOffsets(OffsetsInitializer.latest())
.build();
DataStreamSource<String> kafkaDataStreamSource = env.fromSource(kafkaSource, WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(3)), "kafkasource");
KafkaSink<String> kafkaSink = KafkaSink.<String>builder()
.setBootstrapServers("node2:9092,node3:9092,node4:9092")
.setRecordSerializer(
KafkaRecordSerializationSchema.<String>builder()
.setTopic("ws")
.setValueSerializationSchema(new SimpleStringSchema())
.build()
)
// 精准一次,开启2pc
.setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
// 精准一次,必须设置 事务的前缀
.setTransactionalIdPrefix("prefix-")
// 精准一次,必须设置事务超时时间: 大于checkpoint间隔,小于15分
.setProperty(ProducerConfig.TRANSACTION_TIMEOUT_CONFIG, 10 * 60 * 1000 + "")
.build();
kafkaDataStreamSource.sinkTo(kafkaSink);
env.execute();
}
}启动zk
zk.sh start
启动kafka
kf.sh start
查看kafka主题,如果没有topic_1和ws主题的话,则需要创建相关主题
kafka-topics.sh --bootstrap-server node2:9092,node3:9092,node4:9092 --list
创建kafka主题
kafka-topics.sh --bootstrap-server node2:9092,node3:9092,node4:9092 --create --replication-factor 1 --partitions 1 --topic topic_1 kafka-topics.sh --bootstrap-server node2:9092,node3:9092,node4:9092 --create --replication-factor 1 --partitions 1 --topic ws
启动控制台生产者
kafka-console-producer.sh --broker-list node2:9092 --topic topic_1
启动控制台消费者
kafka-console-consumer.sh --bootstrap-server node2:9092 --topic ws
运行hadoop(主要用到hdfs)
myhadoop.sh start
这里的myhadoop.sh是自己编写的启动脚本。也可以只启动hdfs。
运行KafkaEOSDemo.java程序
控制台生产者生产消息,发送消息,例如:hello world
控制台消费者消费消息
生产消息后,消费者几乎不用等待就可收到消息(hello world)。原因是控制台消费者默认消费的是checkpoint未提交的数据。
在控制台消费者终端,按Ctrl+c关闭控制台消费者。
解决办法:设置消费数据类型为读已提交数据。
.setProperty(ConsumerConfig.ISOLATION_LEVEL_CONFIG, "read_committed")
将控制台消费者改为自己编写的IDEA消费者,设置消费数据类型为读已提交数据。
kafka消费者代码如下:
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import java.time.Duration;
/**
* kafka 消费者 消费ws主题数据
*/
public class KafkaEOSDemo2 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
KafkaSource<String> kafkaSource = KafkaSource.<String>builder()
.setBootstrapServers("node2:9092,node3:9092,node4:9092")
.setGroupId("test")
.setTopics("ws")
.setValueOnlyDeserializer(new SimpleStringSchema())
.setStartingOffsets(OffsetsInitializer.latest())
// 作为下游的消费者,要设置事务的隔离级别为: 读已提交
.setProperty(ConsumerConfig.ISOLATION_LEVEL_CONFIG, "read_committed")
.build();
env.fromSource(kafkaSource, WatermarkStrategy.forBoundedOutOfOrderness(Duration.ofSeconds(3)), "kafkasource")
.print();
env.execute();
}
}测试
运行KafkaEOSDemo2.java程序
控制台生产者生产消息
hello hadoop
[hadoop@node2 kafka]$ kafka-console-producer.sh --broker-list node2:9092 --topic topic_1 >hello world >hello hadoop >
等待一会后,IDEA控制台才有数据输出
hello hadoop
说明此时读的是checkpiont后已提交sink的数据。
完成!enjoy it!
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Flink端到端的精确一次(Exactly-Once)

发表评论 取消回复