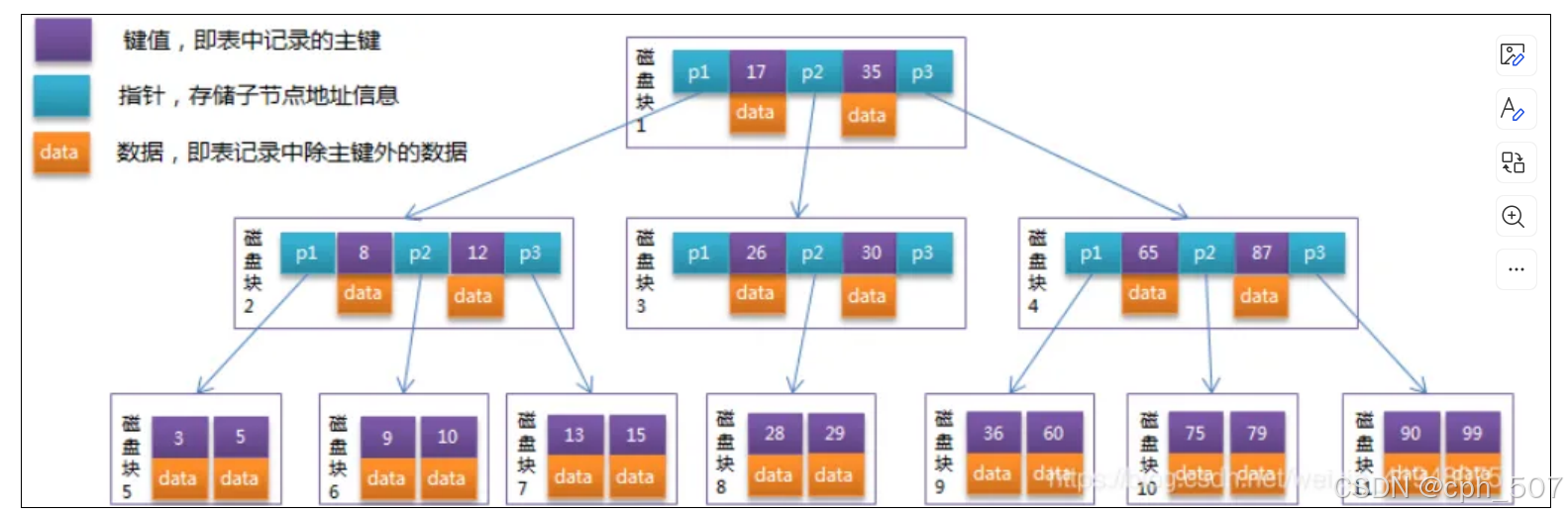
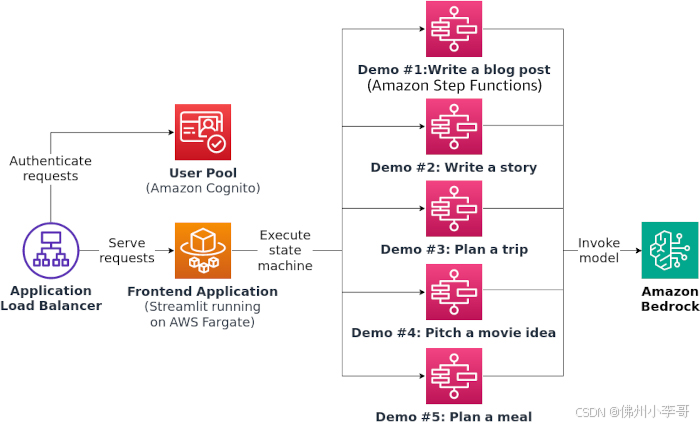
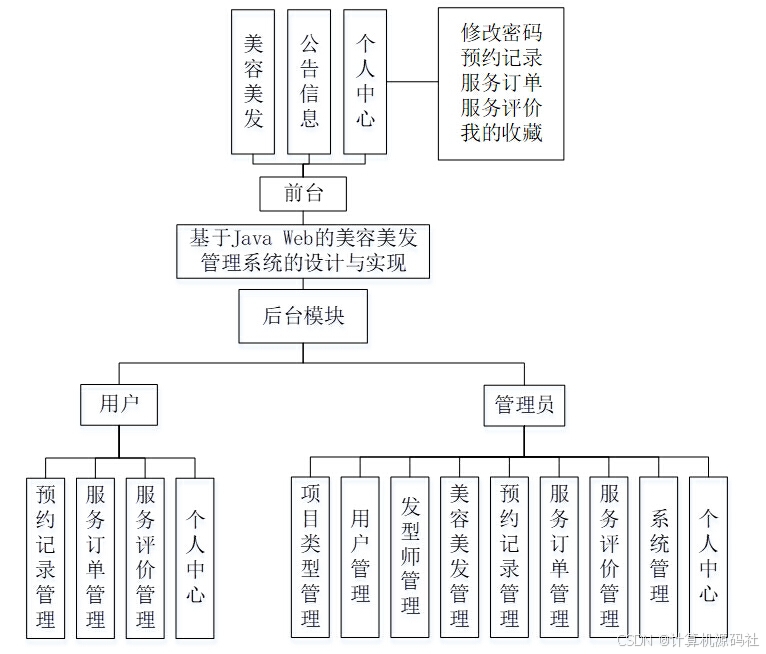
ViP-LLaVA: Making Large Multimodal Models Understand Arbitrary Visual Prompts 文章资讯 2024年08月10日 0 点赞 0 评论 18 浏览