有三种方法,
第一种:均值融合,代码如下
data = pd.read_csv(\ result/submission_randomforest.csv\ )
data['randomforest'] = data['target'].values
temp = pd.read_csv(\ result/submission_lightgbm.csv\ )
data['lightgbm'] = temp['target'].values
temp = pd.read_csv(\ result/submission_xgboost.csv\ )
data['xgboost'] = temp['target'].values
data['target'] = (data['randomforest'] + data['lightgbm'] + data['xgboost']) / 3
data[['card_id','target']].to_csv("result/voting_avr.csv", index=False)
发现简单的均值融合不能使模型效果提升
第二种:加权融合
加权融合的思路并不复杂,从客观计算流程上来看我们将赋予不同模型训练结果以不同权重,而具体权重的分配,我们可以根据三组模型在公榜上的评分决定,即假设模型A和B分别是2分和3分(分数越低越好的情况下),则在实际加权过程中,我们将赋予A模型结果3/5权重,B模型2/5权重,因此,加权融合过程如下:
data['target'] = data['randomforest']*0.2+data['lightgbm']*0.3 + data['xgboost']*0.5
data[['card_id','target']].to_csv(' result/voting_wei1.csv' , index=False)
发现结果略有改善,但实际结果不如但模型结果
第三种:stacking
思路:比如你用了三种模型(XGBOOST,LIGHTGBM,RANDOMFOREST),每个模型都会将数据集分成五份进行交叉验证,并在验证集上进行预测得到五个验证结果,拼起来就是一个完整的验证结果,把三个模型验证结果竖向拼起来就是一个完整的验证结果,同理在测试集上做这个操作,得到的prediction_train和prediction_test就是二阶段训练的训练集和测试集
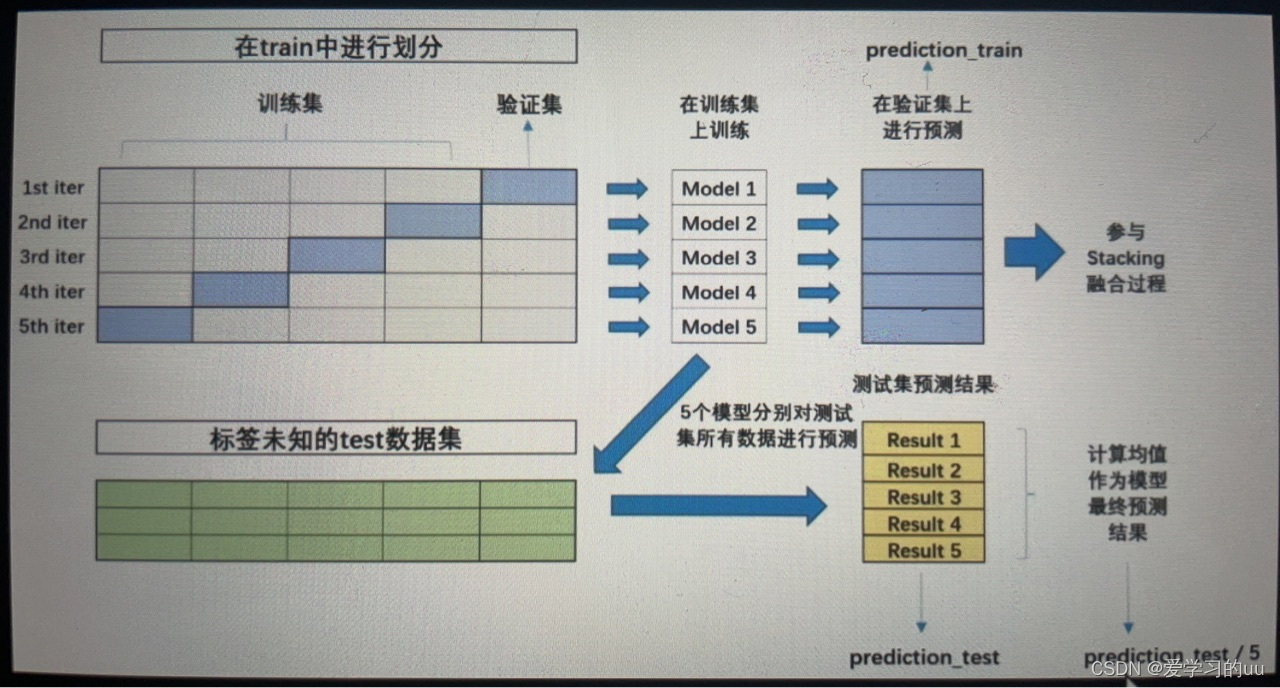
读入数据:oof是训练数据集的预测结果(也就是上面的prediction_train),而predictions则是单模型预测结果。
oof_rf = pd.read_csv('./preprocess/train_randomforest.csv')
predictions_rf = pd.read_csv('./preprocess/test_randomforest.csv')
oof_lgb = pd.read_csv('./preprocess/train_lightgbm.csv')
predictions_lgb = pd.read_csv('./preprocess/test_lightgbm.csv')
oof_xgb = pd.read_csv('./preprocess/train_xgboost.csv')
predictions_xgb = pd.read_csv('./preprocess/test_xgboost.csv')
def stack_model(oof_1, oof_2, oof_3, predictions_1, predictions_2, predictions_3, y):
# Part 1.数据准备
# 按行拼接列,拼接验证集所有预测结果
# train_stack就是final model的训练数据
train_stack = np.hstack([oof_1, oof_2, oof_3])
# 按行拼接列,拼接测试集上所有预测结果
# test_stack就是final model的测试数据
test_stack = np.hstack([predictions_1, predictions_2, predictions_3])
# 创建一个和测试集行数相同的全零数组
predictions = np.zeros(test_stack.shape[0])
# Part 2.多轮交叉验证
from sklearn.model_selection import RepeatedKFold
folds = RepeatedKFold(n_splits=5, n_repeats=2, random_state=2020) #5折交叉验证,两轮
# fold_为折数,trn_idx为每一折训练集index,val_idx为每一折验证集index
for fold_, (trn_idx, val_idx) in enumerate(folds.split(train_stack, y)):
# 打印折数信息
print(' fold n°{}' .format(fold_+1))
# 训练集中划分为训练数据的特征和标签
trn_data, trn_y = train_stack[trn_idx], y[trn_idx]
# 训练集中划分为验证数据的特征和标签
val_data, val_y = train_stack[val_idx], y[val_idx]
# 采用贝叶斯回归作为结果融合的模型(final model)
clf = BayesianRidge()
# 在训练数据上进行训练
clf.fit(trn_data, trn_y)
# 在验证数据上进行预测,并将结果记录在oof对应位置
# oof[val_idx] = clf.predict(val_data)
# 对测试集数据进行预测,每一轮预测结果占比额外的1/10
predictions += clf.predict(test_stack) / (5 * 2)
# 返回测试集的预测结果
return predictions
最终得到私榜分数3.627,公榜3.72,即staking比voting更有效
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » kaggle竞赛实战9——模型融合

发表评论 取消回复