【Pandas驯化-12】一文搞懂Pandas中的分组函数groupby与apply、lambda使用
本次修炼方法请往下查看

欢迎莅临我的个人主页 这里是我工作、学习、实践 IT领域、真诚分享 踩坑集合,智慧小天地!
相关内容文档获取 微信公众号
相关内容视频讲解 B站博主简介:AI算法驯化师,混迹多个大厂搜索、推荐、广告、数据分析、数据挖掘岗位 个人申请专利40+,熟练掌握机器、深度学习等各类应用算法原理和项目实战经验。
技术专长: 在机器学习、搜索、广告、推荐、CV、NLP、多模态、数据分析等算法相关领域有丰富的项目实战经验。已累计为求职、科研、学习等需求提供近千次有偿|无偿定制化服务,助力多位小伙伴在学习、求职、工作上少走弯路、提高效率,近一年好评率100% 。
博客风采: 积极分享关于机器学习、深度学习、数据分析、NLP、PyTorch、Python、Linux、工作、项目总结相关的实用内容。
文章目录
下滑查看解决方法
1. 基本介绍
如果要说上面介绍的一些pandas的基本操作大部分execl厉害的人也能实现,个人感觉pandas处理数据贼有魅力的地方在于它的聚合分组统计操作,这也是在数据建模中特征提取用的最多的地方,在特征提取时,经常需要提取样本分组的统计信息特征。
因此,把这方面的骚操作掌握好了,不仅可以提升数据分析的质量,同时两个不同的操作在效率上也是数倍甚至几十倍的差距,在介绍groupby之前先介绍几个骚函数:
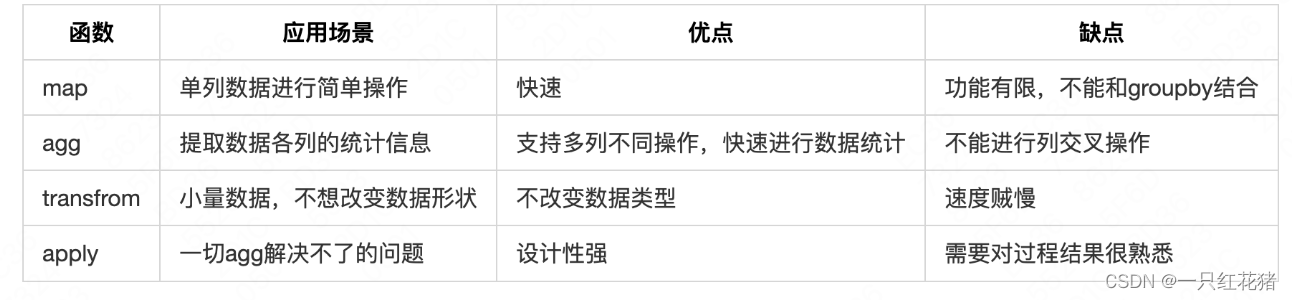
map :只能对一列数据进行操作,且不能和groupby进行结合操作agg:能够与groupby结合操作,但是时一列一列的输出数据的,因此,改方法不能修改在groupby后修改数据,但是它的优点在于可以对多个列数据进行多个不同的基本统计信息(sum, count, min, max等)transform:能够与groupby结合操作,这个函数的优点就是不改变数据的形状来进行分组统计,数据即是多行多列也是一行一列进行输出的,但是虽然是多行多列的输出,不能够在transform内部调用某列进行操作,只能先选择某列在进行操作。apply:能够与groupby结合操作,输出了多行多列的数据,因此可以对数据提取某列进行操作,上述骚函数中,apply函数的功能最为强大,只有你想不到的,没有它做不到的。
2. 使用方法
2.1 groupby函数使用
在进行特征工程时,经常需要按照一定的规则进行统计特征提取,这个gropuby操作和hadoop的mapreduce有一定的相似,groupby可以理解为对数据进行拆分再进行应用再进行合并,当理解了之前介绍的几个骚函数以及一些常用的统计函数然后如果能想象的到groupby之后的数据结构,基本就可以开始你无限的骚操作了,不管是解决产品经理的数据报告需求还是特征提取基本问题不大了,下面介绍一些个人比较喜欢用的操作:
对Dataframe数据进行Groupby之后,可以直接一些简单的统计操作,基本上该有的统计函数都有封装,如果只要统计某列,只需将groupby后的数据取出那一列进行相应的操作就可以,具体如下所示:
import pandas as pd
df = pd.DataFrame({
'a': ['A', 'B', 'A', 'C', 'B', 'C', 'A'],
'b': [1, 2, 3, 4, 5, 6, 7],
'c': [10, 20, 30, 40, 50, 60, 70]
})
print(df)
a b c
0 A 1 10
1 B 2 20
2 A 3 30
3 C 4 40
4 B 5 50
5 C 6 60
6 A 7 70
使用 groupby 对列 a 进行分组,并计算其它列的均值。
mean_grouped = df.groupby('a').mean()
print(mean_grouped)
b c
a
A 4.000000 40.0
B 3.500000 35.0
C 5.000000 50.0
2.2 按列 a 分组统计列 b 的均值
如果只对特定列进行操作,可以在 groupby 后指定列名。,具体为:
mean_grouped_b = df.groupby('a')['b'].mean()
mean_grouped_b
a
A 4.0
B 3.5
C 5.0
Name: b, dtype: float64
2.3 注意事项
- groupby 操作返回的是一个分组对象,可以通过 .mean()、.sum() 等聚合函数来计算统计量。
- 如果分组列中含有 NaN 值,它们将被自动排除在分组之外。
- 聚合函数默认不会修改原始 DataFrame,而是返回一个新的对象。
3. 高阶用法
3.1 性能对比
在使用groupby时有多种不同的方式,下面为具体的实例:
df = pd.DataFrame({'key1':['a', 'a', 'b', 'b', 'a'],
'key2':['one', 'two', 'one', 'two', 'onw'], 'data1':np.random.randn(5),
'data2':np.random.randn(5)})
# 对上述的表按照key1,key2分组统计data1的均值的两种写法:
1.df['data1'].groupby([df['key1'], df['key2']]).count()
2.df.groupby(['key1', 'key2'])['data1'].count()
- 经过对上述的两段代码进行性能测试可以发现,第二段代码相对于第一段代码性能
更优,在执行的时间复杂度上有一定的优势。 - 第一段代码可以解释为,取df表中data1字段按照key1,key2字段进行统计,而第二段代码是先对df表中的key1,key2字段进行分组,然后取data1字段进行统计,个人更习惯于第二段代码不仅更好理解,同时写起来更加的优雅。
3.2 和lambda、函数的结合使用
groupby结合上述几个骚函数进行分组统计信息的使用总结,如果能使用lambda表达式完成的,尽量使用lambda表达式而不去写一个函数,具体lambda的使用为:
按照列a数据分组统计其列b的均值,求和并修改名字且名字前缀为hello_
df.groupby('a'['b'].agg({'b_mean':'mean','b_sum':'sum'}).add_prefix('hello_')
其中add_prefix属性用于给列添加前缀,如果是要对行添加前缀则需要使用apply函数
hello_b_mean hello_b_sum
a
A 4.000000 16.000000
B 9.000000 18.000000
C 5.000000 11.000000
# 将groupby与apply结合起来进行自定义函数设计(需要传入参数的写法),不要传入
# 参数使用lambda表达式即可完成
1. 按照列a进行groupby取列b中值最大的n个数
def the_top_values(data, n=3, cols_name='b'):
return data.sort_values('b')[:n]
df.groupby('a').apply(the_top_values, n=3, clos_name='b')
a b
2 A 7
0 A 5
6 A 3
1 B 10
4 B 8
5 C 6
3 C 4
3.3 和agg函数结合使用的高级玩法
agg对数值型列进行多方式统计, 这里需要注意一点的就是,通过agg进行一列的多统计特征的时候,最后的输出结果是多个multiindex的columns,这个时候需要对其进行一下列名转换
import pandas as pd
# 示例 DataFrame
data = {
'ip': ['ip1', 'ip1', 'ip2', 'ip2', 'ip3'],
'a': [10, 20, 30, 40, 50],
'b': [100, 200, 300, 400, 500],
'c': [1, 2, 3, 4, 5]
}
df = pd.DataFrame(data)
ip a b c
0 ip1 10 100 1
1 ip1 20 200 2
2 ip2 30 300 3
3 ip3 40 400 4
4 ip2 50 500 5
df = df.groupby('ip').agg({
'a' : ['sum', 'max', 'min'],
'b': ['sum', 'max', 'min'],
'c': lambda x: len(x)
})
df.columns = [i[0] + '_' + i[1] for i in df.columns]
df = df.reset_index()
ip a_sum a_max a_min b_sum b_max b_min c_len
0 ip1 30.0 20.0 10.0 300.0 200.0 100.0 2
1 ip2 120.0 500.0 30.0 1200.0 500.0 300.0 2
2 ip3 40.0 400.0 40.0 400.0 400.0 400.0 1
3.3 agg、apply、transforms、map对比
agg 是聚合(aggregation)的缩写,用于对数据集中的分组(groupby)应用一个或多个聚合函数。
apply 是一个通用的方法,用于对数据集中的轴(axis)应用一个函数,并返回函数的结果。
transform 与 apply 类似,但它返回的是对原始数据集的转换结果,保持原始数据的形状不变。
map 是一个用于将映射(mapping)应用到数据集中的元素的方法,通常用于一对一的映射。
df = pd.DataFrame({
'A': [1, 2, 1, 2],
'B': [10, 20, 30, 40]
})
result = df.groupby('A').agg({'B': 'sum'})
result = df.groupby('A')['B'].apply(list)
result = df.groupby('A')['B'].transform(lambda x: x * 2)
result = df['A'].map({1: 'one', 2: 'two'})
3.4 注意事项
- 使用 agg 时,可以一次对多个列应用不同的函数,但返回的结果列名需要特别注意。
- apply 可以返回任何形状的数组,而 transform 必须返回与原始数据相同形状的数组。
- map 只适用于一维数据,且映射操作必须是一对一的。。
- errors=‘coerce’ 强制所有无法转换的值变为 NaN,这有助于数据清洗和后续处理。
4. 总结
本文介绍了如何使用 Pandas 的 groupby 和 agg 方法对 DataFrame 进行分组和聚合操作,并通过自定义聚合函数和列重命名提高了结果的可读性。这些技术在数据分析中非常有用,特别是在需要对分组数据进行综合统计分析时。希望这篇博客能够帮助你更好地理解并应用这些功能。。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【Pandas驯化-12】一文搞懂Pandas中的分组函数groupby与apply、lambda使用

发表评论 取消回复