前言
上一次我们实现了静态图片转字符画:
https://blog.csdn.net/weixin_54143563/article/details/139778645
由此我们不禁思考,对于动态的gif应该怎么转换呢?
思路
在网上我学习到了一种思路:
1.创建中间的临时文件夹tmp,用来存放gif每一帧的画面。
2。上一步保存的每一帧画面拿出来进行字符画的处理,在继续保存到tmp中,用字符画覆盖原来第一步保存的画面。
3.将tmp中的字符画合成为gif。
其中第2步的转化字符画的核心函数为:
# 将图片处理成字符画
def img2ascii(img, ascii_chars, isgray, font, scale1):
scale = scale1
# 将图片转换为 RGB 模式
im = Image.open(img).convert('RGB')
# 设定处理后的字符画大小
raw_width = int(im.width * scale)
raw_height = int(im.height * scale)
# 获取设定的字体的尺寸
x0, y0, x1, y1 = font.getbbox(' ')
font_x, font_y = x1-x0, y1
# 确定单元的大小
block_x = int(font_x * scale)
block_y = int(font_y * scale)
# 确定长宽各有几个单元
w = int(raw_width/block_x)
h = int(raw_height/block_y)
# 将每个单元缩小为一个像素
im = im.resize((w, h), Image.NEAREST)
# txts 和 colors 分别存储对应块的 ASCII 字符和 RGB 值
txts = []
colors = []
for i in range(h):
line = ''
lineColor = []
for j in range(w):
pixel = im.getpixel((j, i))
lineColor.append((pixel[0], pixel[1], pixel[2]))
line += get_char(ascii_chars, pixel[0], pixel[1], pixel[2])
txts.append(line)
colors.append(lineColor)
# 创建新画布
img_txt = Image.new('RGB', (raw_width, raw_height), (255, 255, 255))
# 创建 ImageDraw 对象以写入 ASCII
draw = ImageDraw.Draw(img_txt)
for j in range(len(txts)):
for i in range(len(txts[0])):
if isgray:
draw.text((i * block_x, j * block_y), txts[j][i], (119,136,153))
else:
draw.text((i * block_x, j * block_y), txts[j][i], colors[j][i])
img_txt.save(img)
scale为缩放的比例,这里一般选择1即按照原来的尺寸,那么我们就可以先忽略这个参数了。
然后将图片转为RGB的模式,获取图像的大小。
接着获取字体尺寸的大小,字体文件选用的是Courier-New.ttf文件:

由block_x和block_y分别表示字体单元的长和宽。

w和h确定了原图像中含有的单元数量
那么这里说的将每个单元缩小为一个像素应该如何理解呢?
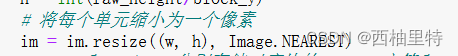
因为w和h确定了原图像中含有的单元数量,现在将im按照最近邻算法缩小为w和h。
所以这个新缩小的图像每一个像素实际上表示的为一个单元。
简单理解就是将原图像划分为许多方格:

然后,我们将上面每一个方格看作一个元素,来创建一个新的图像im。
接着我们处理每一个单元即可。
get_char函数内容如下:
# 将不同的灰度值映射为 ASCII 字符
def get_char(ascii_chars, r, g, b):
length = len(ascii_chars)
gray = int(0.2126 * r + 0.7152 * g + 0.0722 * b)
return ascii_chars[int(gray/(256/length))]
因此该函数实际为按原图像像素值选取ASCII字符。
最后txts为一个列表,列表中每个元素代表的每一行选取的字符串。
colors存放每个单元块的颜色信息。
下面创建原图像尺寸的画布,但是依然按照方格作为像素来遍历(这样做的好处是可以简化处理步骤)。

但是在画布draw上放置字符时,坐标为(i * block_x, j * block_y),这是将方格又还原为了像素。
将拆分画面帧与处理字符画整合:
# 拆分 gif 将每一帧处理成字符画
def gif2pic(file, ascii_chars, isgray, font, scale):
'''
file: gif 文件
ascii_chars: 灰度值对应的字符串
isgray: 是否黑白
font: ImageFont 对象
scale: 缩放比例
'''
im = Image.open(file)
im.seek(0)
duration = im.info.get('duration')
path = os.getcwd()
if(not os.path.exists(path+"/tmp")):
os.mkdir(path+"/tmp")
os.chdir(path+"/tmp")
# 清空 tmp 目录下内容
for f in os.listdir(path+"/tmp"):
os.remove(f)
try:
while 1:
current = im.tell()
name = file.split('.')[0]+'_tmp_'+str(current)+'.png'
# 保存每一帧图片
im.save(name)
# 将每一帧处理为字符画
img2ascii(name, ascii_chars, isgray, font, scale)
# 继续处理下一帧
im.seek(current+1)
except:
os.chdir(path)
return duration合成函数如下:
# 拆分 gif 将每一帧处理成字符画
#def gif2pic(file, ascii_chars, isgray, font, scale):
def gif2pic(file):
'''
file: gif 文件
ascii_chars: 灰度值对应的字符串
isgray: 是否黑白
font: ImageFont 对象
scale: 缩放比例
'''
file_reader=imageio.get_reader(file)
gif_frames=[]
for i,frame in enumerate(file_reader):
im=Image.fromarray(frame)
gif_frames.append(im)
file_reader.close()
return gif_frames
#imageio.mimsave("test003.gif",gif_frames,format='GIF',duration=30,loop=0)
print('end')
我们看看示例如何:

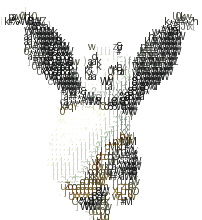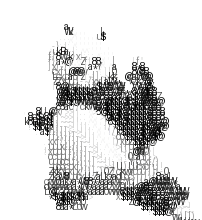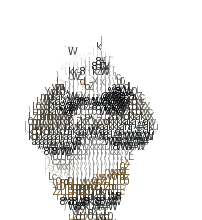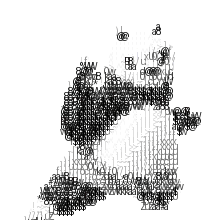
存在的问题
这么看貌似是实现了目标,但是对于我重新找到的示例:芙芙的表情包,来进行转换效果如下:


感觉有卡顿的现象,这是什么造成的呢?回看了一下生成的tmp中间文件,确确实实抽取了原gif的每一帧呀。
另外,将每一帧转化为字符画后保存,最后才将转化的字符画合成为gif还是有些多此一举,为什么不再每一帧转化为字符画后就写入gif动画中呢?这样我们只用遍历一次gif画面帧即可。为了实现这个步骤,我首先创建一个画面帧的列表,然后每次将转化的字符画添加进列表,最后使用
imageio.mimsave("test002.gif",images,mode='I',format='GIF')合成gif,不过,执行这行代码总是出现这样的报错:

直接上网搜,别人使用的变量和我们是不一样的,还是不能解燃眉之急呀。
上面两个问题困扰了我很久。
经过多次尝试,我发现了其实上面两个问题是有一定联系的。
为什么会出现卡顿?
因为我们保存画面帧的时候,后缀的区别在与01,02,03·······这样的数字。在功夫熊猫的示例中,gif的帧数不超过10,所以没有卡顿的情况。
但是对于芙芙表情包,还有100帧的前提下,我们读取tmp的方式为:

打印一下读取的文件名:
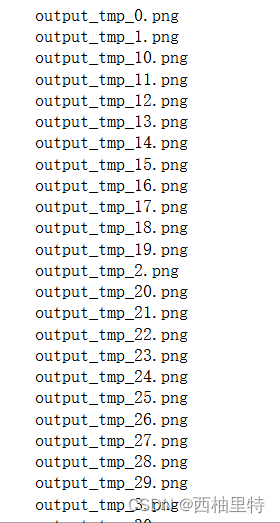
发现了问题,按照字符大小来读取文件,那么10是小于2的因为我们首先比较第一个不同的字符,1小于2,因此我们并不是按照顺序读取的。
接下来,我们可以单纯提取文件名中的数字字符,然后转为整形,从而按照实际循序读取文件。但是这样显然有增加了许多计算。
那么我们直接在获取每一帧画面转字符画的时候就合成gif就可以避免文件名大小的问题了,这也就是上面我们遇到的第二个要解决的情况。
按理说,既然能够在tmp中保存每一帧的画面,那么直接利用这些画面合成一个新的gif也不应该有问题呀。我在仔细回看原来的代码,发现了这样一个细节:

画面转为RGB,还记得之前webp文件转JPG吗?因为JPG文件没有透明度的通道所以要先转为RGB,所以上面出现输入shape不匹配也是因为多了一个透明度的通道,那么我们只需要在获取每一帧后先转一下RGB再次进行后续的操作就没有问题了:

最终效果展示:


可见转化后也很丝滑了。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » GIF转字符画

发表评论 取消回复