-
数据库用户管理及高级sql语句
-
数据库管理
-
数据库用户管理
-
mysql权限表
-
在mysql中mysql库中的user表是最重要的权限表,记录允许连接到服务器的账号信息以及全局权限,
-
在mysql库中db和host表也是重要的权限表
-
db表中存储了用户对某个数据库的操作权限,决定用户能够从那个主机存取那个数据库。
-
host表中存储了某个主机对数据库的操作权限。
-
-
-
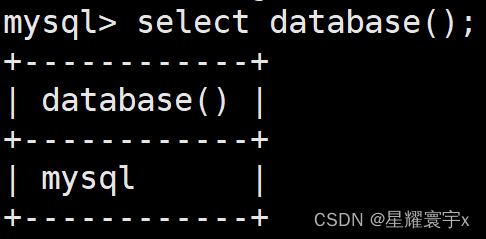
查看自己在那个库
-
select database()
-
-
-
用户管理
-
完整直接的登录命令
-
mysql -u用户 -p密码 -h 从哪登录 -p 连接端口 可以跟库名
-
-
例如在系统命令行中执行sql语句
-
mysql -u root -p -h localhost test -e "DESC person;"
-
-e 后用引号引起要使用的sql语句
-
-
-
新建普通用户
-
create user ’用户名‘@’从哪登录‘ identified by ’通过那个密码连接‘
-
create创建后用户权限较低需要赋予权限
-
-
grant select on *.* to '用户名'@’从哪登录‘ identified by ’登陆密码‘
-
用授权语句也可以进行用户的创建
-
-
insert into user (Host,User,Password) VALUES('localhost','customer1',PASSWORD('customer1'));
-
直接修改权限表
-
-
-
删除用户
-
drop user ’用户名‘@’那个终端‘
-
DELETE FROM mysql.user WHERE host='localhost' and user='customer1';
-
注意and限制条件,避免对整体数据进行改动
-
-
-
-
密码管理
-
系统命令行修改
-
mysqladmin -u root -p password "123456"
-
-
修改权限表
-
UPDATE mysql.user set Password=password("rootpwd2") WHERE User="root" and Host="localhost";
-
在修改权限表时一定要加where进行限制
-
-
-
使用sql命令
-
SET password=password("rootpwd3");
-
需要注意该方式是修改当前登录用户的密码
-
-
SET PASSWORD FOR 'testUser'@'localhost'=password("newpwd");
-
该方式可以利用root权限对其他用户的密码进行修改
-
-
-
管理员密码丢失解决办法
-
跳过权限表
-
mysqld-safe --skip-grant-tables &
-
也可以在配置文件中加入该选项,然后进行重启重载的方式。加入”&“ 选项将该命令放到后台执行,并且该行为会被记录错误日志
-
-
无密码登录使用update语句对密码字段进行修改
-
update mysql.user set password=password('mypass') where user='root' and host='localhost';
-
修改完毕后重新加载权限表
-
flush privileges;
-
-
-
-
-
-
授权管理
-
默认授权语句的all授权不包括授权权限
-
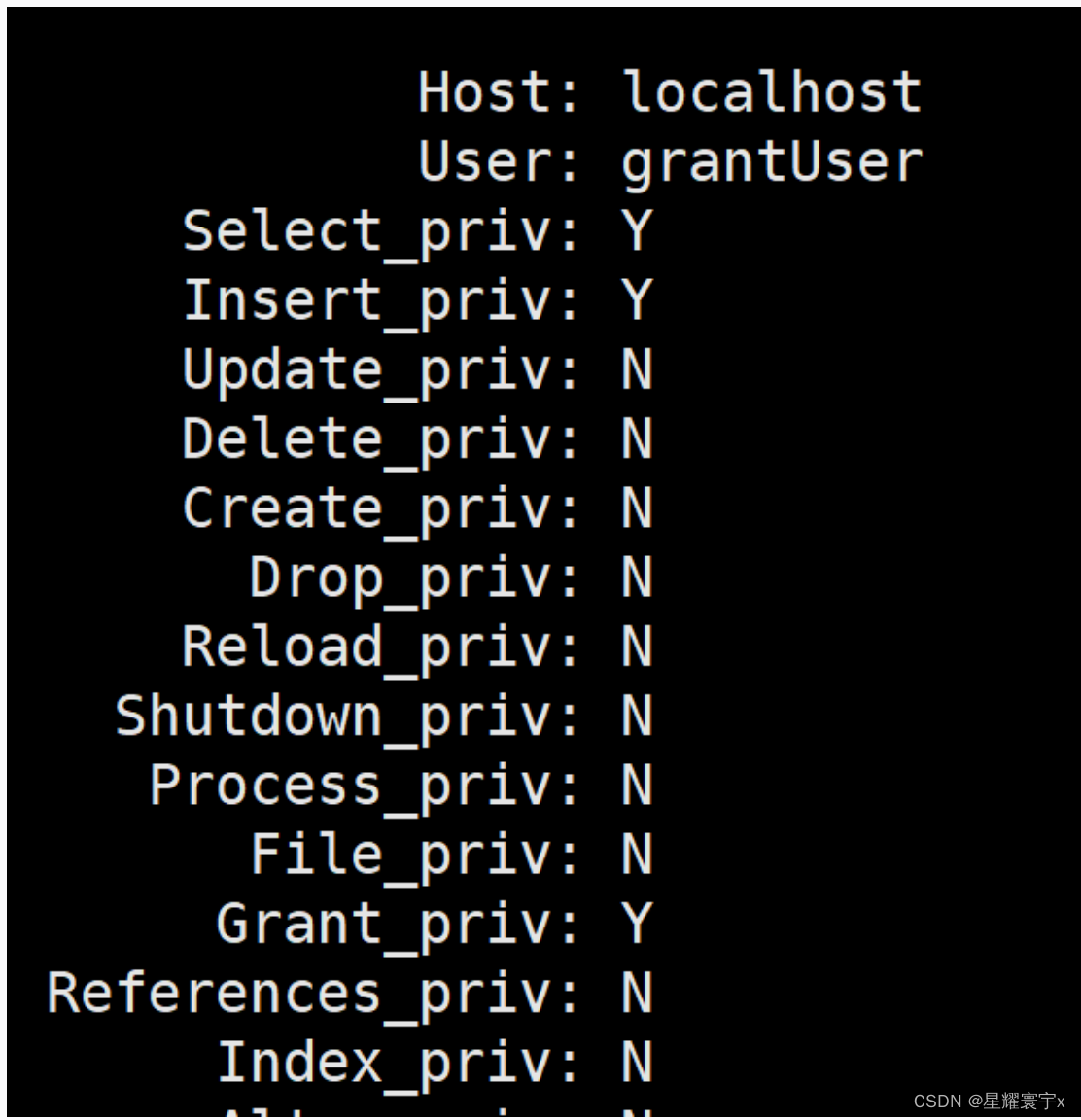
GRANT SELECT,INSERT ON *.* TO 'grantUser'@'localhost' IDENTIFIED BY 'grantpwd' ;
-
WITH GRANT OPTION :该语句能赋予用户的授权权限。
-
-
-
-
收回权限
-
REVOKE UPDATE ON *.* FROM 'testUser'@'localhost';
-
单独收取update权限
-
-
-
查看权限
-
可以查询user表
-
-
Y表示有权限
-
N表示无权限
-
-
-
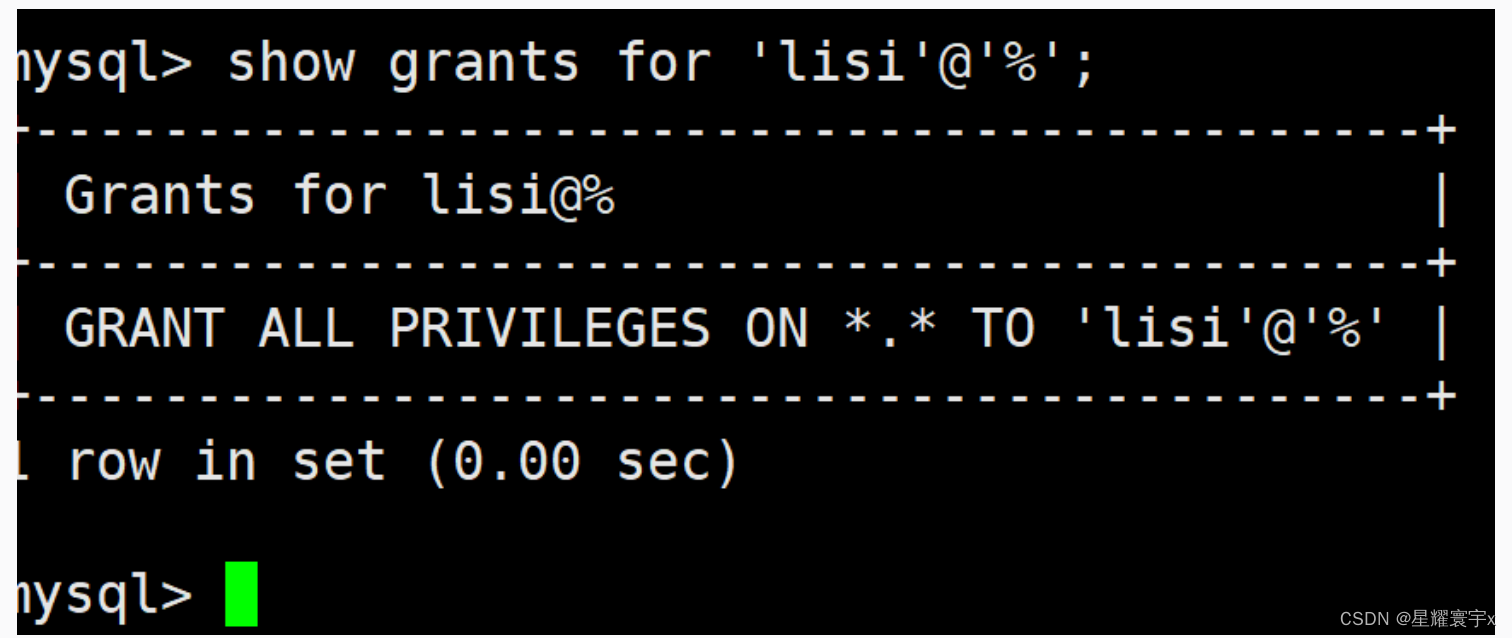
show grants for ’账户‘@’在那登录‘
-
-
-
访问控制
-
通过授权时
-
GRANT SELECT,INSERT ON *.* TO 'grantUser'@'localhost' IDENTIFIED BY 'grantpwd'
-
'grantUser'@'localhost' 通过@后的语句可以限定用户能从什么条件下进行登录。
-
-
-
-
-
-
高级sql语句
-
实验测试表
-
create database auth; use auth create table t1(id int(10), name char(20),level int(10)); insert into t1 value(10,'sagou',42); insert into t1 value(8,'senoku',45); insert into t1 value(15,'useless',47); insert into t1 value(27,'guess',52); insert into t1 value(199,'useless',48); insert into t1 value(272,'Theshy',36); insert into t1 value(298,'leslieF',40); insert into t1 value(30,'shirley',58); insert into t1 value(190,'zhangsan',48); insert into t1 value(271,'lisi',52); insert into t1 value(299,'wangwu',52); insert into t1 value(31,'zhaoliu',58); create table t2(id int(10), name char(20),level int(10)); insert into t2 value(10,'sagou',42); insert into t2 value(8,'senoku',45); insert into t2 value(15,'useless',47); insert into t2 value(27,'guess',52); insert into t2 value(199,'useless',48); insert into t2 value(272,'Theshy',36); insert into t2 value(298,'leslieF',40);
-
创建了两个t1表与t2表
-
-
-
查询并进行筛选排序
-
select id,name,level from t1 where level>=45 order by level desc;
-
筛选条件level>=45
-
排序order by level desc
-
desc:降序排序
-
asc:升序排序(默认)
-
-
-
-
查询结果分组化
-
group by通常与聚合函数一起使用
-
计数
-
count
-
-
求和
-
sum
-
-
求平均数
-
avg
-
-
最大值
-
max
-
-
最小值
-
min
-
-
-
例
-
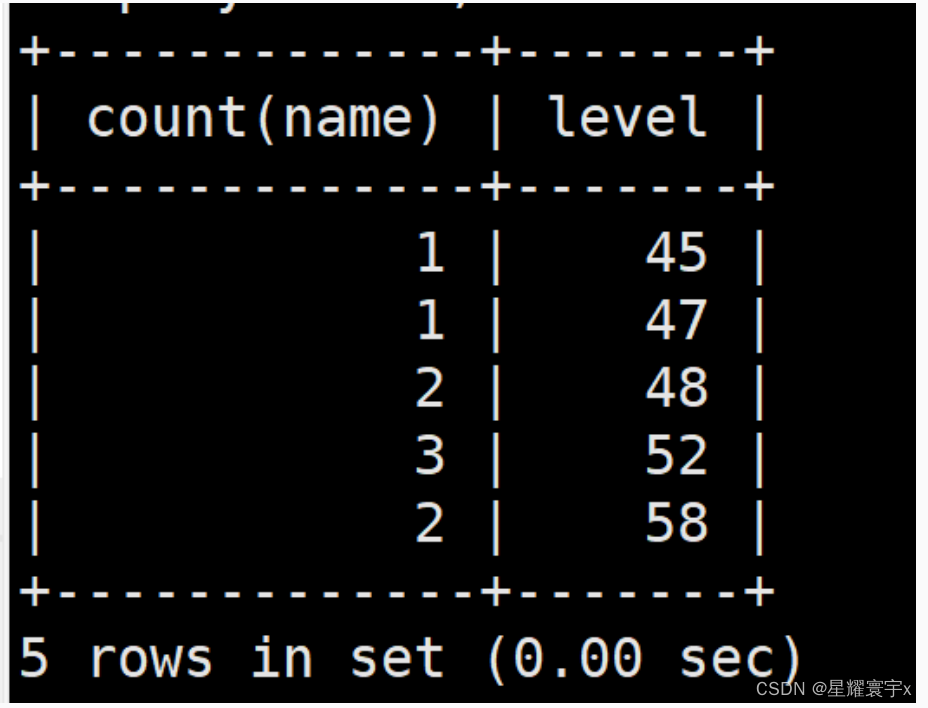
统计等级45以上,以等级分组每个分组有多少人
-
select count(name),level from t1 where level>=45 group by level;
-
-
count():计数函数
-
-
-
统计等级45以上,以等级分组每个分组有多少人并进行降序排序
-
select count(name),level from t1 where level>=45 group by level order by count(name) desc;
-
-
-
-
限制结果条目
-
只返回匹配的记录
-
使用limit语句
-
只显示前三个用户的信息
-
select id,name,level from t1 limit 3
-
-
也可以结合排序功能,不过要注意limit排序需要放到最后
-
select id,name,level from t1 order by level desc limit 3;
-
-
只显示特定行的匹配结果
-
select id,name,level from t1 limit 2,3;
-
表示显示第二行开始的三行数据
-
-
-
-
-
设置别名
-
为了将某些较长的列名简化增加易读性可以设置别名
-
例
-
在统计数量时会将数量列名设置为count(name)利用别名简化显示
-
select count(*) as number from t1;
-
as:alias别名,以此作为连接;可以设置汉语,如果采用了utf8等支持汉语的编码格式。
-
-
-
-
-
创建表时将其它表的内容导入到该表
-
create table t3 as select * from t1;
-
-
-
通配符
-
在使用select时限制条件where后的匹配可以使用通配符
-
”%“:表示匹配所有
-
“_“:表示匹配单个字符
-
-
-
子查询
-
利用select嵌套实现子查询的需求
-
insert into t2 select * from t1 where id in (select id from t1)
-
-
-
NULL
-
在创建表时可以利用not null 来规定避免出现空值的情况。
-
null与空值有何区别
-
空值
-
长度为0
-
空值的判断使用=’’或者<>’’来处理。
-
-
null
-
长度为null占用空间
-
IS NULL 或者 IS NOT NULL,是用来判断字段是不是为 NULL 或者不是 NULL,不能查出是不是空值的。
-
-
在通过 count()计算有多少记录数时,如果遇到 NULL 值会自动忽略掉,遇到空值会加入到记录中进行计算。
-
-
-
逻辑运算符
-
逻辑非:NOT 或 !
-
有一方不成立,则结果就不成立
-
-
逻辑与:AND 或 &&
-
任何一个值为0,则结果就为0
-
-
逻辑或 :R 或 ||
-
任何一个值为1,则结果就为1
-
-
逻辑异或:XOR
-
双方都成立则最终值不成立,双方都不成立,则最终值也不成立 双方有一个成立,一个不成立,则最终值成立
-
-
-
位运算符
-
&
-
按位与
-
任何一个值为0结果就为0
-
-
-
|
-
按位或
-
任何一个值为1结果就为1
-
-
-
^
-
按位异或
-
-
!
-
取反
-
-
左移
-
<<
-
-
右移
-
>>
-
-
-
连接查询
-
创建测试用表
-
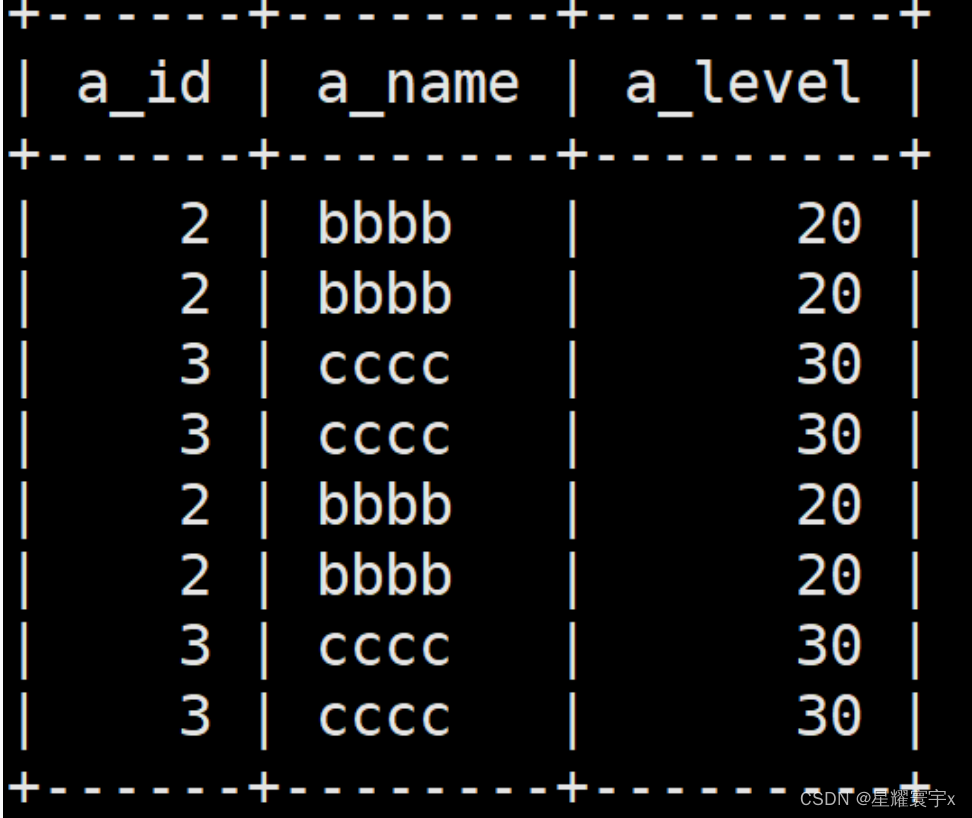
CREATE TABLE `a_t1` ( `a_id` int(11) DEFAULT NULL, `a_name` varchar(32) DEFAULT NULL, `a_level` int(11) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8; CREATE TABLE `b_t1` ( `b_id` int(11) DEFAULT NULL, `b_name` varchar(32) DEFAULT NULL, `b_level` int(11) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8; insert into a_t1(a_id, a_name, a_level) values(1, 'aaaa', 10); insert into a_t1(a_id, a_name, a_level) values(2, 'bbbb', 20); insert into a_t1(a_id, a_name, a_level) values(3, 'cccc', 30); insert into a_t1(a_id, a_name, a_level) values(4, 'dddd', 40); insert into b_t1(b_id, b_name, b_level) values(2, 'bbbb', 20); insert into b_t1(b_id, b_name, b_level) values(3, 'cccc', 30); insert into b_t1(b_id, b_name, b_level) values(5, 'eeee', 50); insert into b_t1(b_id, b_name, b_level) values(6, 'ffff', 60);
-
-
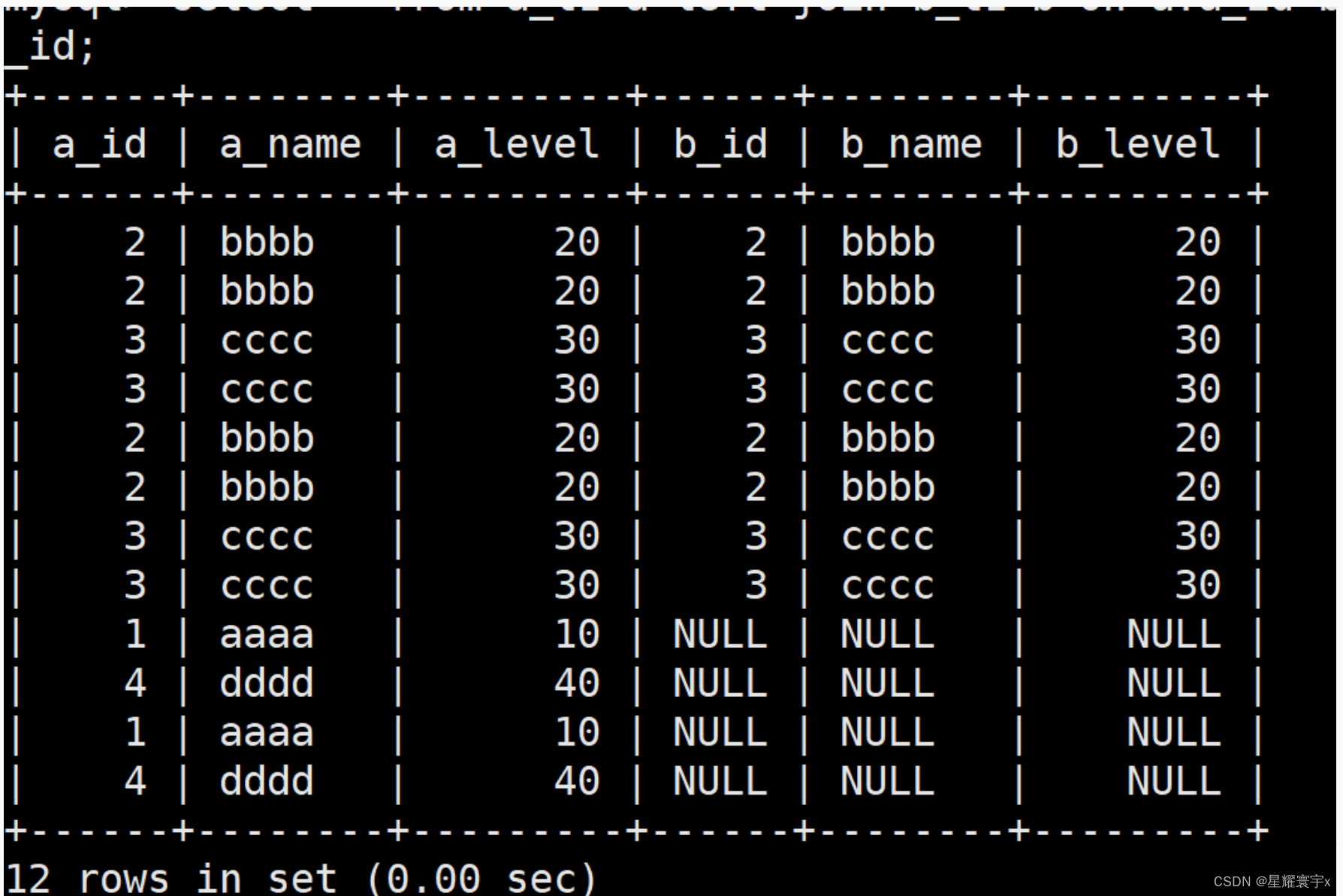
内连接
-
select a_id,a_name,a_level from a_t1 inner join b_t1 on a_id=b_id;
-
-
相当于查询两个数据表共同有的部分,(交集)
-
-
-
-
左连接
-
select * from a_t1 a left join b_t1 b on a.a_id=b.b_id;
-
-
以左表为主,查询出左表中的所有内容和与右表中相同的内容,不同的以null代替
-
-
-
右连接与左连接相反
-
-
-
数据库函数
-
聚合函数
-
avg() :返回指定列的平均值
-
count() :返回指定列中非 NULL 值的个数
-
min() :返回指定列的最小值
-
max() :返回指定列的最大值
-
sum(x) :返回指定列的所有值之和
-
例
-
mysql>select sum(level) as sum_level from t1; mysql>select max(level) as max_level from t1; mysql>select min(level) as min_level from t1;
-
-
-
字符串函数
-
length(x) 返回字符串 x 的长度第
-
trim() 移除字符串两侧的空白字符或其他预定义字符
-
concat(x,y) 将提供的参数 x 和 y 拼接成一个字符串
-
upper(x) 将字符串 x 的所有字母变成大写字母
-
lower(x) 将字符串 x 的所有字母变成小写字母
-
left(x,y) 返回字符串 x 的前 y 个字符
-
right(x,y) 返回字符串 x 的后 y 个字符
-
repeat(x,y) 将字符串 x 重复 y 次
-
space(x) 返回 x 个空格
-
replace(x,y,z) 将字符串 z 替代字符串 x 中的字符串 y
-
strcmp(x,y) 比较 x 和 y,返回的值可以为-1,0,1
-
substring(x,y,z) 获取从字符串 x 中的第 y 个位置开始长度为 z 的字符串
-
reverse(x) 将字符串 x 反转
-
-
时间日期函数
-
curdate() 返回当前时间的年月日
-
curtime() 返回当前时间的时分秒
-
now() 返回当前时间的日期和时间
-
month(x) 返回日期 x 中的月份值
-
week(x) 返回日期 x 是年度第几个星期
-
hour(x) 返回 x 中的小时值
-
minute(x) 返回 x 中的分钟值
-
second(x) 返回 x 中的秒钟值
-
dayofweek(x) 返回 x 是星期几,1 星期日,2 星期一
-
dayofmonth(x) 计算日期 x 是本月的第几天
-
dayofyear(x) 计算日期 x 是本年的第几天
-
-
-
存储过程(是一个对象)
-
介绍:MySQL 数据库存储过程是一组为了完成特定功能的 SQL 语句的集合,存储过程在数据库中创建并保存,它不仅仅是 SQL 语句的集合,还可以加入一些特殊的控制结构,也可以控制数据的访问方式。
-
优点:
-
执行后留在缓冲区,再次调用效率高
-
灵活性高,可以进行复杂的操作
-
存储过程时存储在服务端,在客户端进行调用时消耗带宽少
-
支持多次反复调用,多人同时调用
-
-
创建存储过程
-
mysql> DELIMITER $$ mysql> CREATE PROCEDURE t1Role() BEGIN SELECT id,name,level from t1 limit 3; END $$
-
DELIMITER $$ :修改mysql结束符为$$,避免与中间的mysql语句的结束符产生冲突,创建存储过程完毕后需要修改回”;“结束符。
-
-
修改储存过程就是删除原有储存过程在创建新同名储存过程。
-
DROP PROCEDURE [IF EXISTS] procedure_name;
-
if exists 是检测存储过程依赖,避免删除造成较大影响
-
procedure_name:是具体的存储过程名
-
-
-
-
-
-
-
以上就是对mysql数据库的管理以及高级sql语言的说明,仅供参考 。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 数据库管理与数据库语句

发表评论 取消回复