本篇文章是博主在人工智能等领域学习时,用于个人学习、研究或者欣赏使用,并基于博主对人工智能等领域的一些理解而记录的学习摘录和笔记,若有不当和侵权之处,指出后将会立即改正,还望谅解。文章分类在AI学习笔记:
AI学习笔记(9)---《聚类算法(3)---K-means 算法》
聚类算法(3)---K-means 算法
目录
1. 前言
理解并掌握动态聚类算法所涉及的一些基础概念,并通过 Matlab 编程实现。
理解并掌握感 K-means 算法原理以及物理含义,编写一个简单的基于欧式距离的 K-means 算法进行聚类的例子。
2.相关知识
2.1模式特征
在模式识别的任务中,模式通常是指我们观测的样本,而描述模式则通常是通过特征向量这样一种方式来进行的。
2.2相似性测度
相似性测度是用来衡量模式(或称样本)之间相似性的“依据”。这里的模式可以理解为“特征向量”,因为在做聚类分析时,我们通常会将待分类的对象抽象成若干的“特征值”,这些“特征值”组成的向量便是待聚类的模式。
通过相似性测度,我们可以量化不同模式之间的相似性,从而作为分类的依据。这里简要介绍两种距离测度:欧式距离、马氏距离。
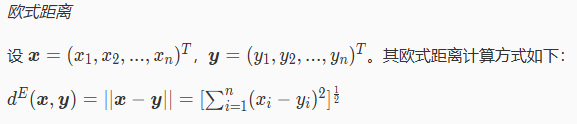

可见,相比于欧氏距离,马氏距离在计算时用到了样本集合的协方差矩阵。可以证明,马氏距离对一切非奇异线性变换都是不变的,这说明它不受特征量纲选择的影响。举例来说,特征向量xi不同分量很可能是实际的物理量,随着量纲的不同,数值会发生变化,如 1 千克变为 100 克。量纲改变导致的数值变化可能会影响不同样本之间的相似性测度。
2.3类间距离测度方法
这里主要介绍重心距离法,这是一种用一个点来表示一个类的空间位置方法。通过重心距离法,不仅能够量化类别与类别之间的距离,也能够很好的量化模式与类别之间的距离。在后面介绍的 K-means 聚类算法中,使用重心距离法会简化计算过程。
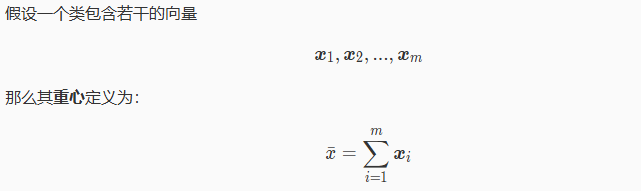
3.K-means 算法原理
K-means 算法是一种动态聚类算法。动态聚类算法的基本思想是定义一个能表征聚类过程或结果优劣的准则函数,然后不断优化准则函数,最终取得一个理想的聚类效果。动态聚类算法的基本步骤是:
- 选取初始聚类中心及有关参数,进行初始聚类;
- 计算样本和聚类的距离,调整样本的类别;
- 计算各聚类的参数,删除、合并或分类一些聚类;
- 从初始聚类开始,通过迭代算法动态的改变类别和聚类中心,使准则函数取得极值或设定的参数达到设计要求时停止。
K-means 算法算法步骤:

4.编程实现
4.1欧式距离计算MATLAB代码
function [distance] = step1_mission(v1, v2)
%%%%%%%%%% Begin %%%%%%%%%%
m = size(v1, 1); % 获取矩阵 v1 的行数,即向量 v1 的数量
n = size(v2, 1); % 获取矩阵 v2 的行数,即向量 v2 的数量
dist_matrix = zeros(m, n); % 初始化 m 行 n 列的零矩阵,用于存储距离值
for i = 1:m % 遍历 v1 的每一行
for j = 1:n % 遍历 v2 的每一行
dist_matrix(i, j) = sqrt(sum((v1(i, :) - v2(j, :)).^2)); % 计算 v1 的第 i 个向量与 v2 的第 j 个向量之间的欧氏距离
end
end
distance = dist_matrix; % 将距离矩阵赋值给输出变量 distance
%disp(dist_matrix); % 可选:输出距离矩阵
%%%%%%%%%% End %%%%%%%%%%
end4.2 K-means 聚类法MATLAB代码
function [output_c] = step2_mission( vs, init_c )
% 读取样本个数,特征维度,初始化类心
[sample_num,~] = size(vs); % sample_num读取样本个数
[center_num, center_d] = size(init_c); % center_num类心个数,center_d 特征维度大小
old_c = init_c;
new_c = init_c;
% K-means 算法迭代部分
while 1
% 计算样本到类心欧式距离,并根据欧式距离进行分类
%%%%%%%%%% Begin %%%%%%%%%%
for i=1:sample_num
infer=99999;
for j=1:center_num
dist=euclidean_dist(vs(i,:),init_c(j,:));
if dist<infer
infer=dist;
classify(i)=j;
end
end
end
%%%%%%%%%% End %%%%%%%%%%
% 初始化新类心
new_c = zeros(center_num, center_d);
new_c_count = zeros(1,center_num);
% 使用重心法计算计算新类心
for idx = 1:sample_num
new_c(classify(idx),:) = new_c(classify(idx),:) + vs(idx,:);
new_c_count(classify(idx)) = new_c_count(classify(idx)) + 1;
end
new_c = new_c./((new_c_count')*ones(1, center_d));
% 判断是否收敛,阈值为0.01,是则结束迭代,否则更新类心继续迭代
%%%%%%%%%% Begin %%%%%%%%%%
flag=1;
for i=1:center_num
for j=1:center_d
if old_c(i,j)-new_c(i,j)>0.01
flag=0;
end
end
end
if flag
break;
else
old_c=new_c;
end
%%%%%%%%%% End %%%%%%%%%%
end
% 返回聚类类心作为结果
output_c = new_c;
end
function [distance] = step1_mission(v1, v2)
%%%%%%%%%% Begin %%%%%%%%%%
m = size(v1, 1); % 获取矩阵 v1 的行数,即向量 v1 的数量
n = size(v2, 1); % 获取矩阵 v2 的行数,即向量 v2 的数量
dist_matrix = zeros(m, n); % 初始化 m 行 n 列的零矩阵,用于存储距离值
for i = 1:m % 遍历 v1 的每一行
for j = 1:n % 遍历 v2 的每一行
dist_matrix(i, j) = sqrt(sum((v1(i, :) - v2(j, :)).^2)); % 计算 v1 的第 i 个向量与 v2 的第 j 个向量之间的欧氏距离
end
end
distance = dist_matrix; % 将距离矩阵赋值给输出变量 distance
%disp(dist_matrix); % 可选:输出距离矩阵
%%%%%%%%%% End %%%%%%%%%%
end4.3 测试输入
MATLAB终端输入下面指令
测试step1_mission(v1, v2)
a1 = [0 0 0];
b1 = [2 2 2];
a2 = [1 5 9; 5 5 5; 9 9 9];
b2 = [0 0 0];
a3 = [1 1 1; 2 2 2];
b3 = [3 3 3; 0 0 0; 5 5 5];
a4 = [1 2 3 4 5 6 7 8 9];
b4 = [1 1 2 3 4 5 6 8 9; 5 5 5 5 5 6 8 7 0];
result1 = step1_mission(a1,b1)
result2 = step1_mission(a2,b2)
result3 = step1_mission(a3,b3)
result4 = step1_mission(a4,b4)
测试step2_mission(samples, c1)
samples = [-7.82 -4.58 -3.97; -6.68 3.16 2.71; 4.36 -2.91 2.09; 6.72 0.88 2.80; -8.64 3.06 3.50; -6.87 0.57 -5.45; 4.47 -2.62 5.76; 6.73 -2.01 4.18; -7.71 2.34 -6.33; -6.91 -0.49 -5.68; 6.18 2.81 5.82; 6.72 -0.93 -4.04; -6.25 -0.26 0.56; -6.94 -1.22 1.13; 8.09 0.20 2.25; 6.81 0.17 -4.15; -5.19 4.24 4.04; -6.38 -1.74 1.43; 4.08 1.30 5.33; 6.27 0.93 -2.78];
c1 = [1.0 1.0 1.0; -1.0 1.0 -1.0];
c2 = [0.0 0.0 0.0; -1.0 1.0 -1.0];
c3 = [0.0 0.0 0.0; 1.0 1.0 1.0; -1.0 0.0 2.0];
c4 = [-0.1 0.0 0.1; 0.0 -0.1 0.1; -0.1 -0.1 0.1];
disp('task1:');
output_c1 = step2_mission(samples, c1)
disp('task2');
output_c2 = step2_mission(samples, c2)
disp('task3');
output_c3 = step2_mission(samples, c3)
disp('task4');
output_c4 = step2_mission(samples, c4)
文章若有不当和不正确之处,还望理解与指出。由于部分文字、图片等来源于互联网,无法核实真实出处,如涉及相关争议,请联系博主删除。如有错误、疑问和侵权,欢迎评论留言联系作者,或者私信联系作者。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 聚类算法(3)---K-means 算法

发表评论 取消回复