kube-state-metrics 是一个Kubernetes的附加组件,它通过监听 Kubernetes API 服务器来收集和生成关于 Kubernetes 对象(如部署、节点和Pod等)的状态的指标。这些指标可供 Prometheus 进行抓取和存储,从而使你能够监控和分析Kubernetes集群的状态和性能。
之前介绍过node-exporter和cAdvisor,但是他们收集的指标和kube-state-metrics是不同的。
不同插件的指标
node_exporter的指标主要关注节点的CPU、内存、磁盘和网络利用率等指标,以及系统负载,I/O操作和运行进程数。cAdvisor是一个容器监控工具,集成在Kubelet中,关注容器的CPU、内存和网络的资源使用情况。这两种都是与运行状态直接相关的物理或虚拟资源的度量。
而kube-state-metrics指标则是记录部署中期望副本数与当前副本数、pod的生命周期状态、重启次数、服务端点的状态等。
在实际应用中,将这两类指标结合起来使用可以提供更全面的视图来监控和管理 Kubernetes 集群。使用 node_exporter 和 cAdvisor 的指标可以帮助理解节点和容器的性能瓶颈。使用 kube-state-metrics 的指标可以帮助理解集群中的工作负载如何分布,以及 Kubernetes 控制平面的健康状态。
kube-state-metrics部署
创建sa文件
因为这个插件需要和kubernetes API交互,所以需要权限。
apiVersion: v1
kind: ServiceAccount
metadata:
name: kube-state-metrics
namespace: kube-system创建role文件
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: kube-state-metrics
rules:
- apiGroups: [""]
resources: ["nodes", "pods", "services", "resourcequotas", "replicationcontrollers", "limitranges", "persistentvolumeclaims", "persistentvolumes", "namespaces", "endpoints"]
verbs: ["list", "watch"]
- apiGroups: ["extensions"]
resources: ["daemonsets", "deployments", "replicasets"]
verbs: ["list", "watch"]
- apiGroups: ["apps"]
resources: ["statefulsets"]
verbs: ["list", "watch"]
- apiGroups: ["batch"]
resources: ["cronjobs", "jobs"]
verbs: ["list", "watch"]
- apiGroups: ["autoscaling"]
resources: ["horizontalpodautoscalers"]
verbs: ["list", "watch"]
创建rolebinding
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: kube-state-metrics
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kube-state-metrics
subjects:
- kind: ServiceAccount
name: kube-state-metrics
namespace: kube-system
可以看到把之前创建的sa和clusterRole绑定在了一起。
[root@master prometheus]# kubectl get sa -n kube-system | grep kube-state-metrics
kube-state-metrics 1 43s
创建pod
[root@master prometheus]# cat kube-state-metrics-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
namespace: kube-system
name: kube-state-metrics
spec:
replicas: 1
selector:
matchLabels:
app: kube-state-metrics
template:
metadata:
labels:
app: kube-state-metrics
spec:
serviceAccountName: kube-state-metrics
containers:
- name: kube-state-metrics
image: quay.io/coreos/kube-state-metrics:v1.9.0
imagePullPolicy: IfNotPresent
ports:
- containerPort: 8080
这里的deployment使用了之前定义的sa。可以看到pod成功启动,ip地址为:10.244.166.164
[root@master prometheus]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
kube-state-metrics-57794dcf65-8wt8g 1/1 Running 0 110s 10.244.166.164 node1 <none> <none>
monitoring-grafana-5bb6bb7867-9j2xb 1/1 Running 0 24h 10.244.166.160 node1 <none> <none>
创建service
[root@master prometheus]# cat kube-state-metrics-service.yaml
apiVersion: v1
kind: Service
metadata:
annotations:
prometheus.io/scrape: 'true'
name: kube-state-metrics
namespace: kube-system
labels:
app: kube-state-metrics
spec:
type: NodePort
ports:
- name: kube-state-metrics
port: 8080
protocol: TCP
selector:
app: kube-state-metrics
[root@master prometheus]# kubectl get svc -n kube-system -owide
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
kube-dns ClusterIP 10.96.0.10 <none> 53/UDP,53/TCP,9153/TCP 19d k8s-app=kube-dns
kube-state-metrics NodePort 10.106.104.112 <none> 8080:31711/TCP 10s app=kube-state-metrics
monitoring-grafana NodePort 10.110.10.133 <none> 80:31519/TCP 24h k8s-app=grafana
此时查看Prometheus,可以看到endpoint里面已经识别到了这个pod
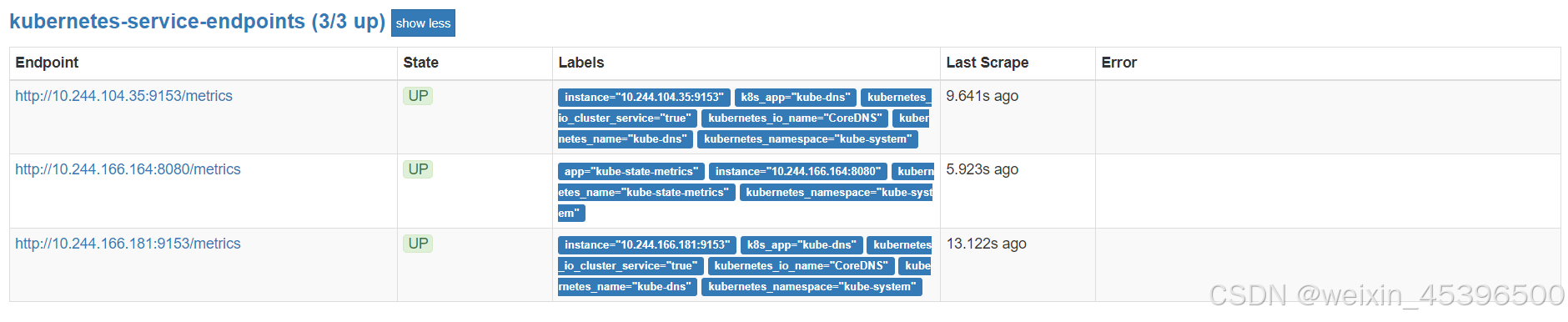
导入相应的json文件,在grafana里面也可以看到数据了。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » [单master节点k8s部署]19.监控系统构建(四)kube-state-metrics

发表评论 取消回复