浅谈大模型参数TopP和TopK
大语言模型中的temperature、top_p和top_k参数是用来控制模型生成文本时的随机性和创造性的。下面分享一下topP和topK两个参数的意义及逻辑;
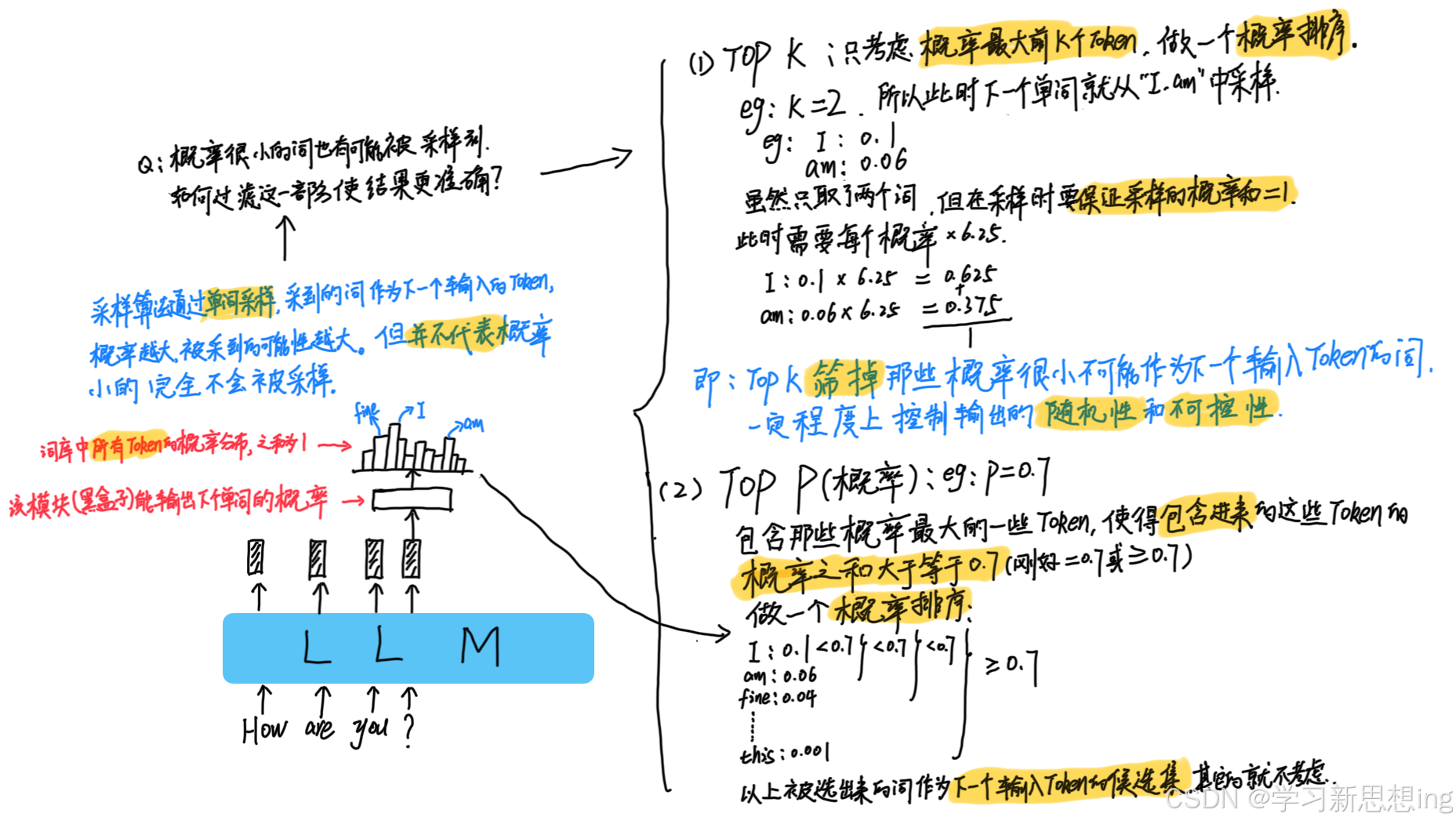
top K(Top-K Sampling)
-
作用:只从模型认为最可能的
k个词中选择下一个词。k值越大,选择范围越广,生成的文本越多样;k值越小,选择范围越窄,生成的文本越趋向于高概率的词。 -
常见设置:一般设置在40到100之间。较小的
k值可以提高文本的相关性和连贯性,而较大的k值则增加了文本的多样性。
top P(Nucleus Sampling)
-
作用:从概率累计达到
p的那一组词中随机选择下一个词。与Top-K不同,Top-P是动态的,依据每个上下文的不同而变化。 -
常见设置:通常设置在0.8到0.95之间。较低的
top_p值(如0.8)使生成的文本更加可预测和相关,而较高的值(如0.95)增加了文本的多样性和创造性。
top K VS top P
-
top_k提供了一个固定数量的候选词,而top_p提供了一个动态变化的候选词集合,其大小取决于特定上下文中词的概率分布。 -
使用
top_k可能会导致生成的文本在不同情况下过于类似,因为它总是从固定数目的最可能的词中选择。相比之下,top_p提供了更多的灵活性和多样性,因为它允许根据上下文的不同选择不同数量的候选词。
通俗理解top P和top K背后逻辑
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 06浅谈大语言模型可调节参数TopP和TopK

发表评论 取消回复