写在前面
Kafka、RocketMQ都是很出名的中间件,上次我们讲解了Kafka,这次我们来讲讲RocketMQ的原理。
基本架构图
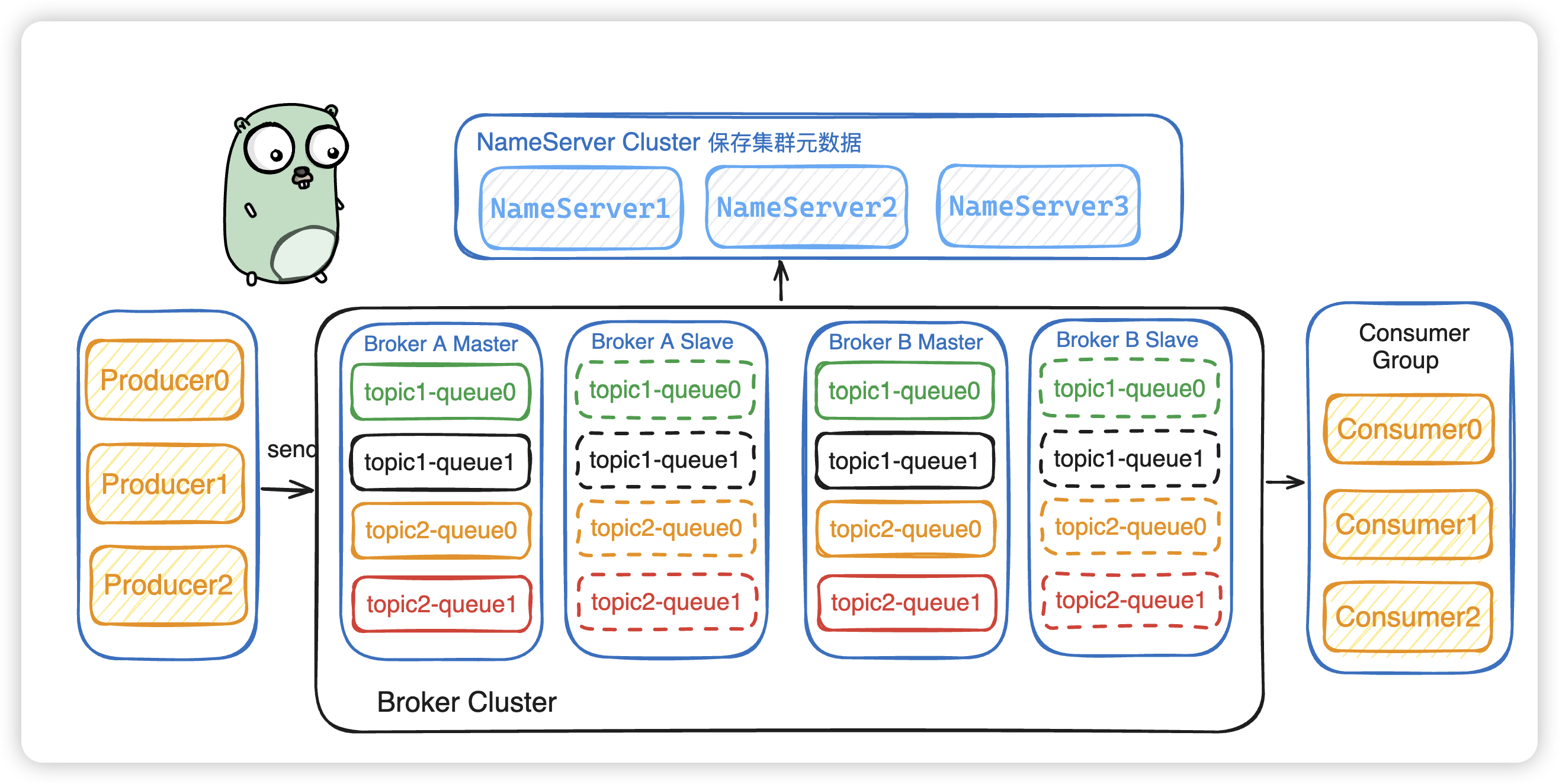
解析
RocketMQ 总共可以分成四个模块
- NameServer:提供
服务发现和路由功能,管理各种元数据信息。 - Broker:消息存储和路由分发节点,负责
存储消息和将消息路由给消费者。 - Producer:消息生产者,负责
产生并发送消息到指定的 Topic。 - Consumer:消息消费者,订阅 Topic 并从 Broker 拉取消息进行处理。
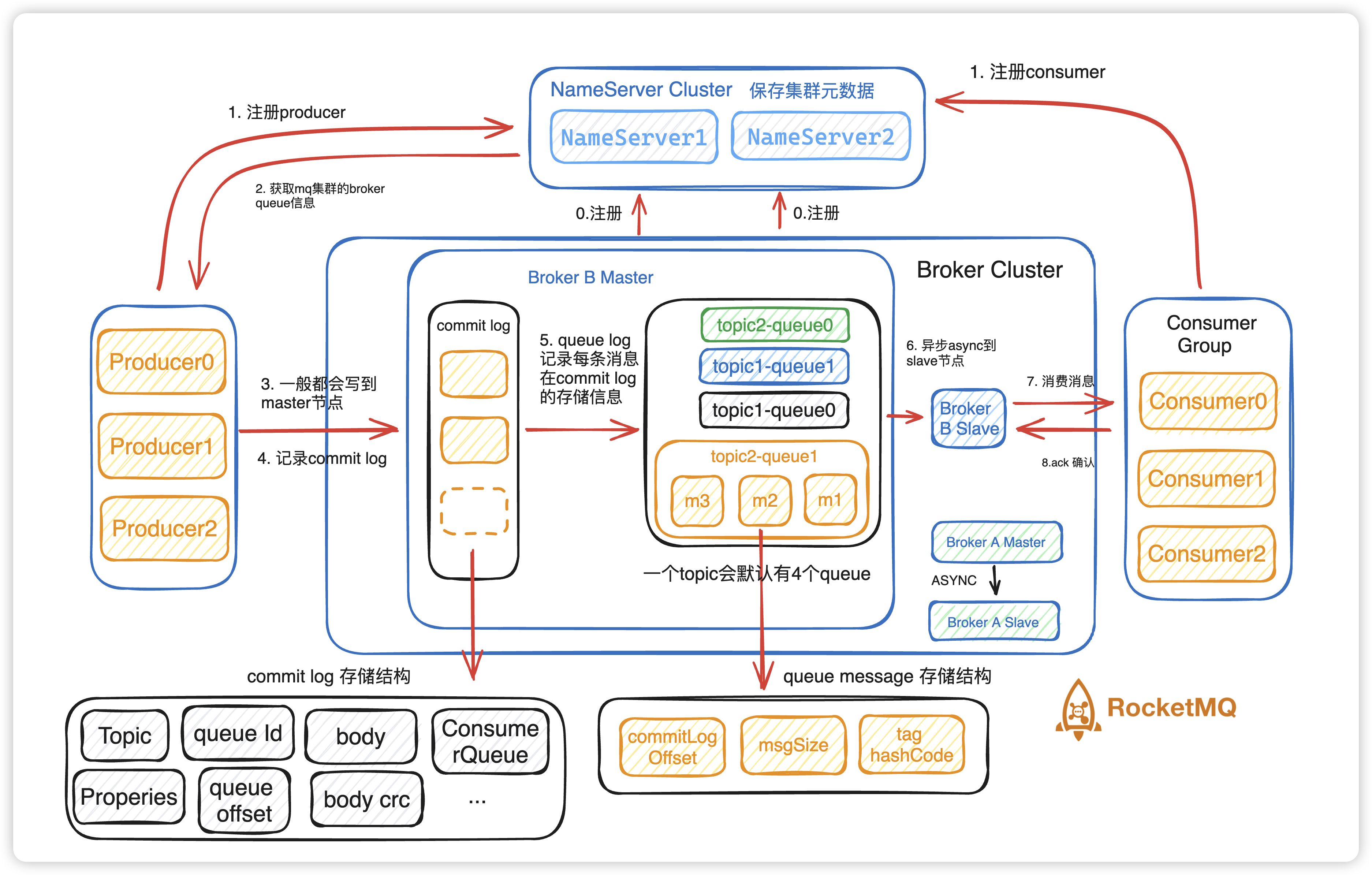
大体读写步骤
- 注册 Broker Cluster 到 NameServer。
- 注册 Producer、Consumer 到 NameServer。
- Producer 获取MQ集群的Broker、Queue等信息。
- Producer 发消息,一般消息都会选择master进行写入,而slave进行读取。
- 顺序写入消息到 commit log 中。
- queue log会记录每条commit log的存储信息,当然不会记录所有,只记录一些重要的,commitLogOffset等等。
- master 将消息异步给slave。
- Consumer读取slave的消息。
- Consumer返回ACK作为确认消息消费成功。
1. NameServer
当Broker服务启动后,会向NameServer注册信息,比如broker中的Topic、消费偏移量、队列、ip、端口等,由Broker的心跳发送到NameServer,BrokerCluster 中的每一个节点都会注册到NameServer上。
即使一个NameService节点挂了,剩下的一个NameService节点仍然包含所有的broker信息。不过NameService是无状态的, NameService之间不会相互通信,那么一个NameService挂了,不会影响另外一个NameService。
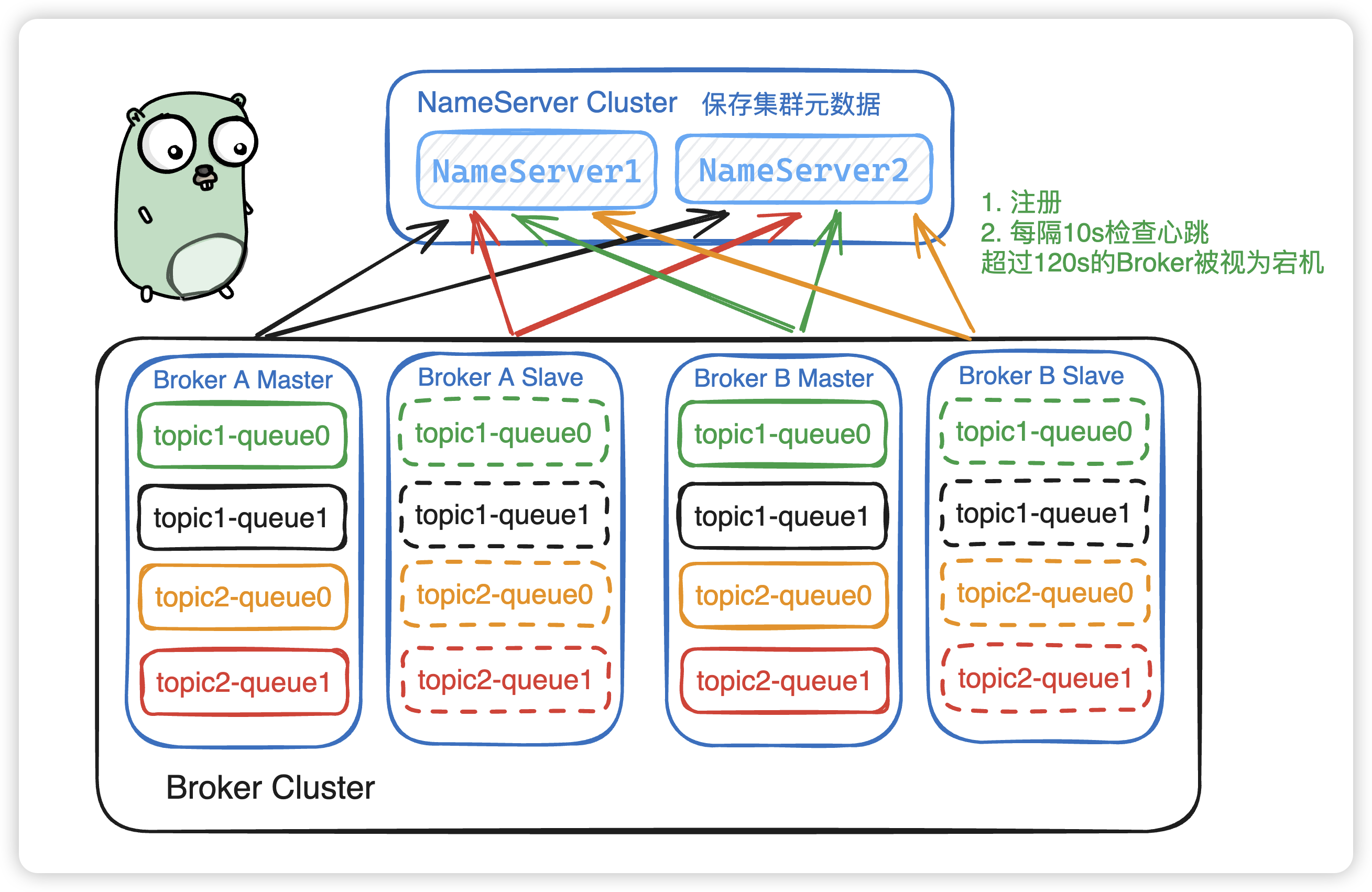
注册完Broker之后,NameServer会每隔10s发送心跳检查Broker,如果Broker超过120s还没有相应,则这个Broker被视为宕机
2. Broker
2.1 CommitLog & Message Queue
Broker 启动,跟所有的 NameServer 保持长连接,每 30s 发送一次发送心跳包(像心跳一样持续稳定的发送请求)。心跳包中包含当前 Broker 信息 ( IP+ 端口等)以及存储所有 Topic 信息。注册成功后,NameServer 集群中就有 Topic 跟 Broker 的映射关系。
Broker接受消息,会顺序写入消息到 CommitLog 中。Broker里面的两个存储介质:Commit log 和 Message queue的区别:
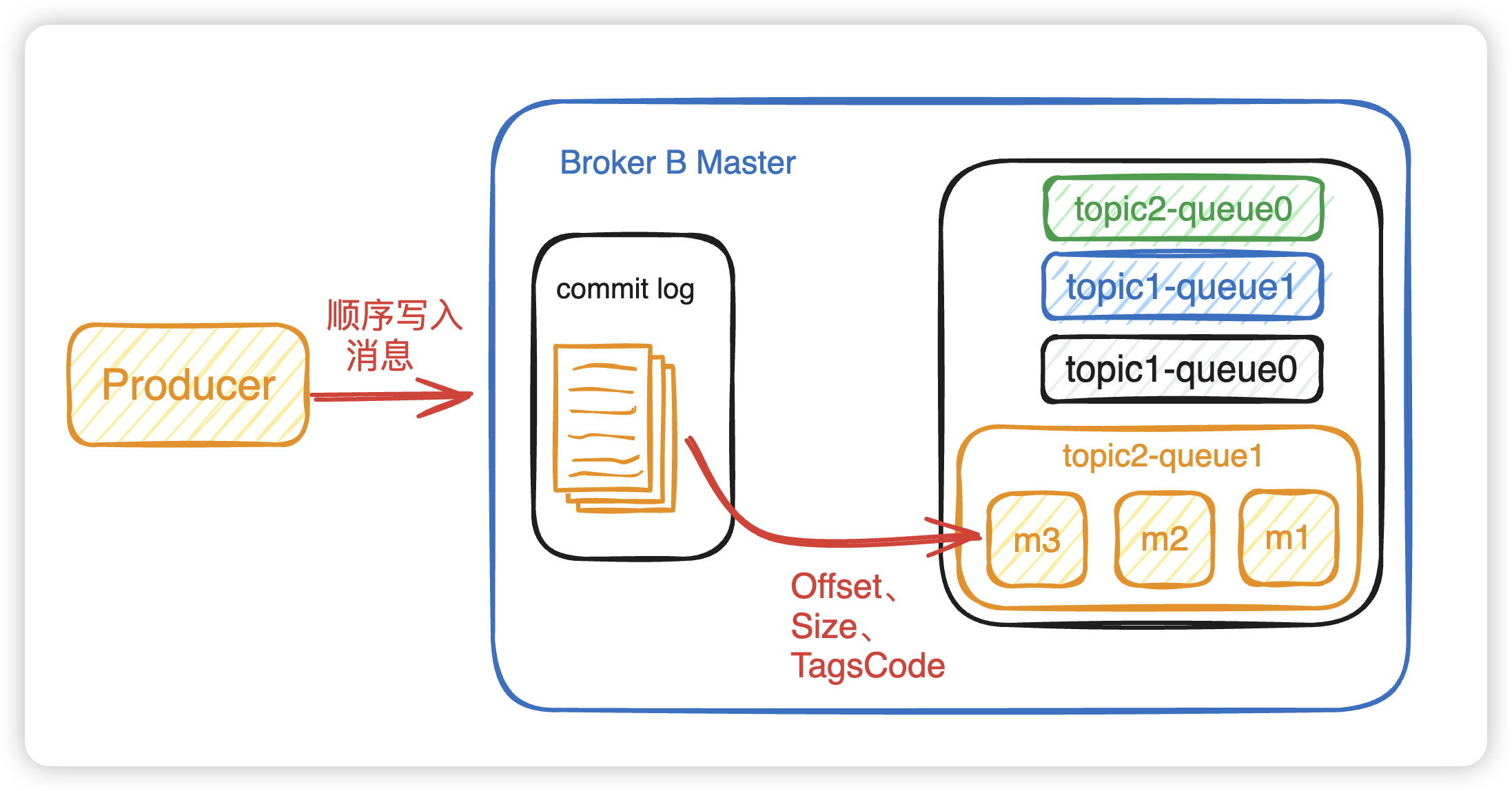
- Commit log 存储消息实体。顺序写,随机读。虽然是随机读,但是利用package机制,可以批量地从磁盘读取,作为cache存到内存中,加速后续的读取速度。
- Message queue 存储消息的
偏移量。读消息先读 message queue,根据偏移量到 commit log 读消息本身。
所以其实我们的消息不是存放在queue中,而是存放在commit log中,这就是为什么queue会被称为逻辑队列
2.2 Index File
2.2.1 介绍
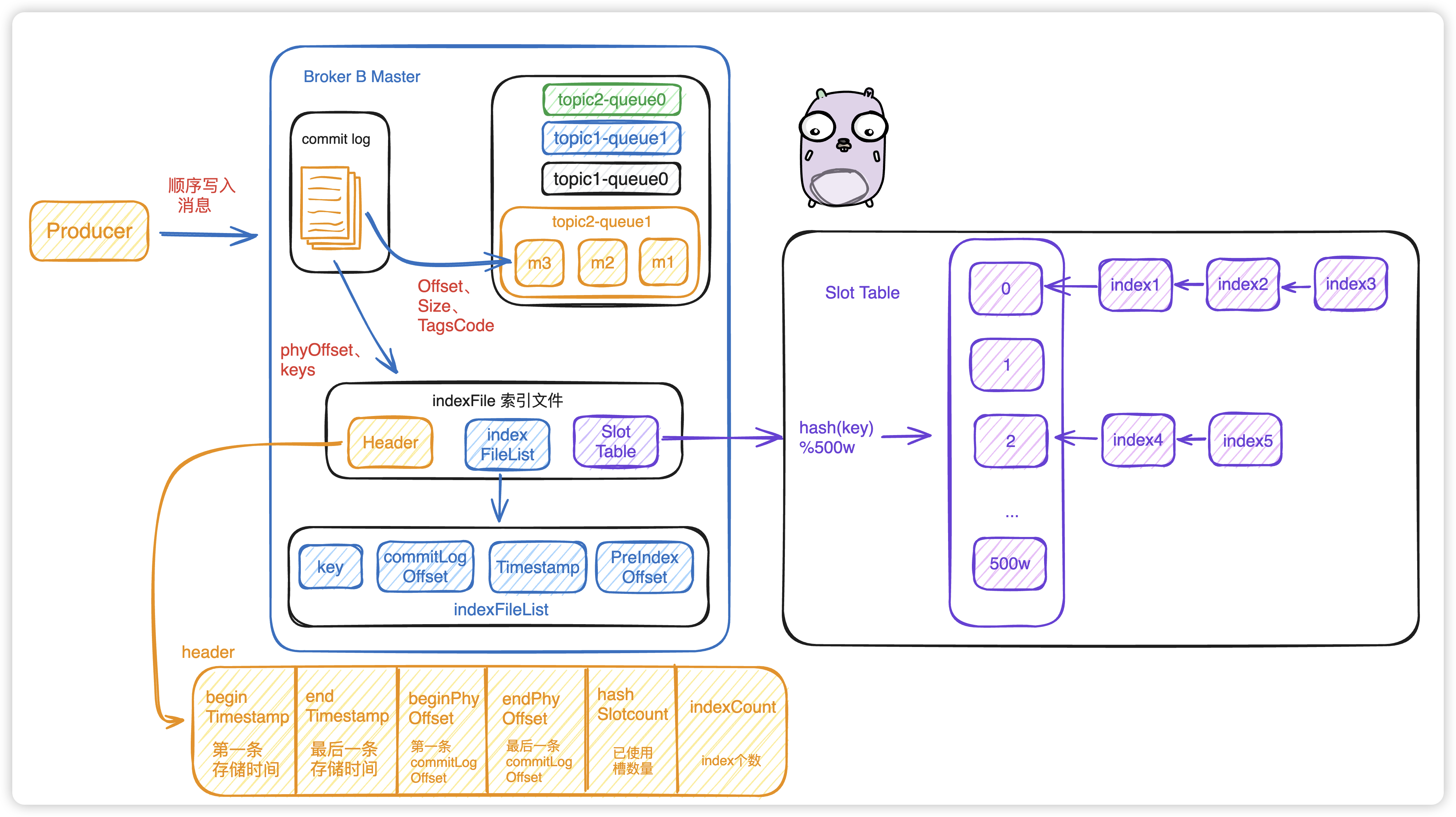
因为所有的消息都存在CommitLog中,如果要实现根据 key 查询 消息的方法,就会变得非常困难,所以为了解决这种业务需求,有了IndexFile的存在。用于为生成的索引文件提供访问服务,通过消息 Key 值查询消息真正的实体内容。
IndexFile 如何创建?以创建的时间戳命名。参数:phyOffset物理偏移量(也就是commitLogOffset)、keys。
如何查询消息呢?
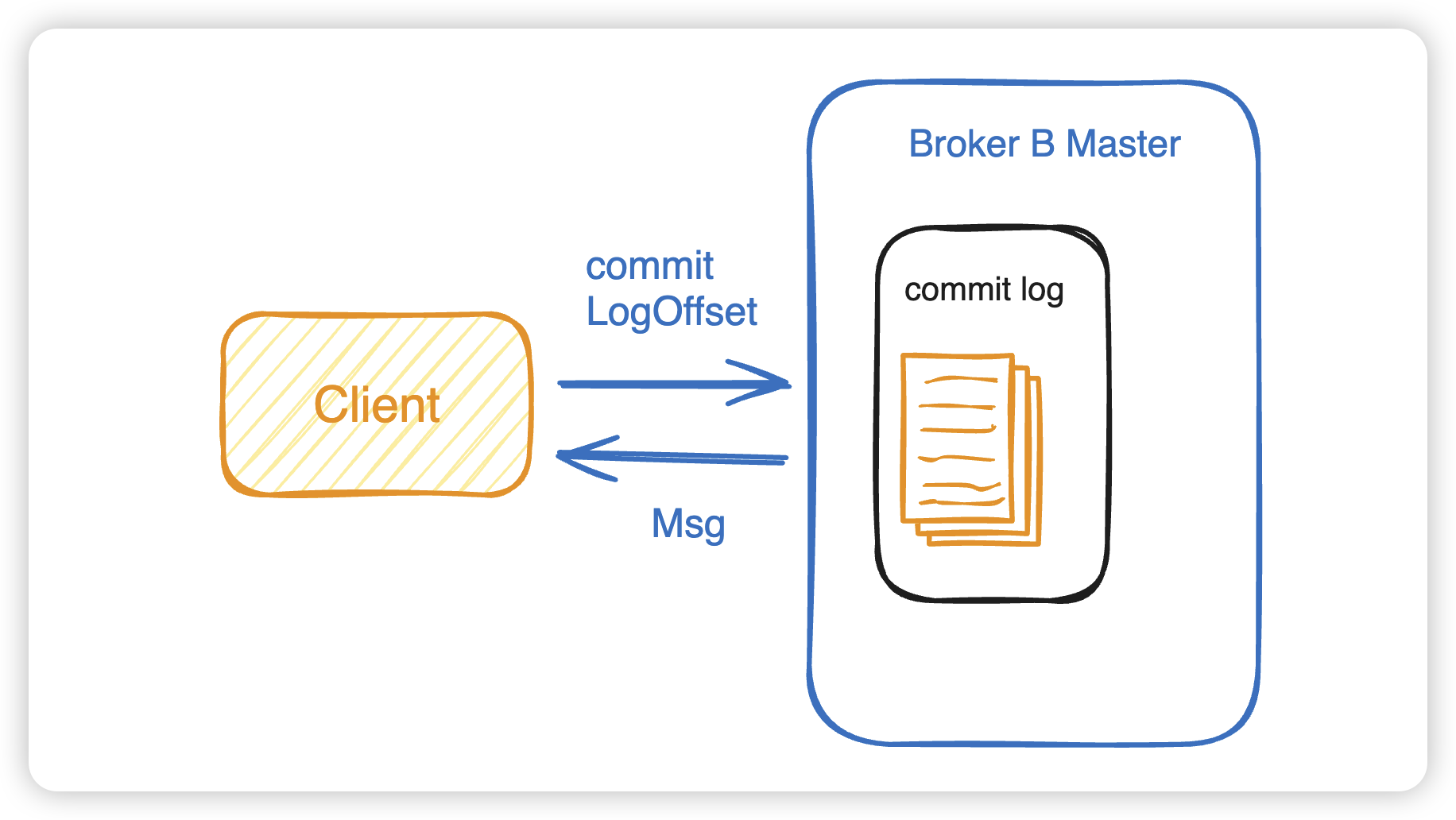
2.2.2 按照MessageId查询
RocketMQ中的MessageId的长度总共有16字节,其中包含了消息存储主机地址(IP地址和端口),消息Commit Log offset。
- Client 端从 MessageId 中解析出 Broker 的地址(IP地址和端口)和Commit Log的偏移地址发送一个RPC请求。
- Broker 端读取消息的过程用其中的 commitLog offset 和 size 去 commitLog 中找到真正的记录并解析成一个完整的消息返回。
2.2.3 按照Message Key查询
- 找槽位:slotKey =
40 byte + hash(topic + "#" + key) % 500W * 4byte。 - 计算槽位:slotValue = 最新插入 index 的位置。
- 遍历单向链表:从 slotValue 找到最新 index 在整个索引文件中位置 =
40byte +500w*4byte + slotValue*20byte,然后根据单个索引文件的 pre index 值找到前一个索引,一直遍历下去,直到index数据中key hash和时间区间都满足即可。添加到 commitLogOffset 的 list) 中。 - 最终根据其中的
commitLogOffset从 CommitLog 文件中读取消息的实体内容。
3. Producer
略。Producer好像除了负载均衡,就没什么好讲的地方了。
4. Consumer
在RocketMQ中,Consumer端的两种消费模式(Push/Pull)都是基于拉模式来获取消息的,pull需要手动实现拉取消息,push只需要实现消费监听器。但实际底层都是pull。
在Consumer启动后,会通过定时任务不断地向所有Broker实例发送心跳包,包含:消息消费分组名称、订阅关系集合、消息通信模式和客户端id的值等信息
Broker端在收到Consumer的心跳消息后,会将它维护在 ConsumerManager 的本地缓存变量。会根据消费者组获取对应维护的消费者组信息。
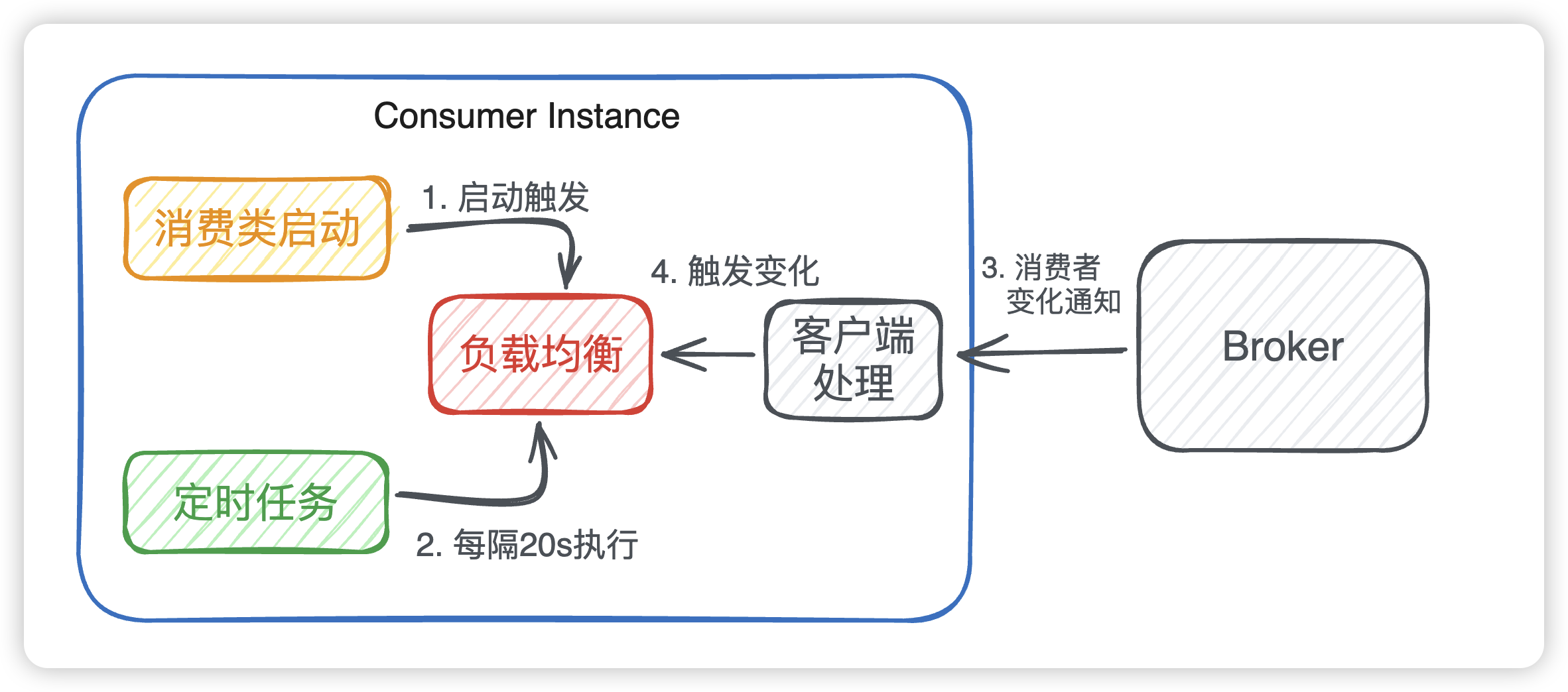
如果是新加入的consumer获取订阅信息变了,会通知这个消费者组里面的其他消费者说消费者有变化,被通知到的消费者就会重新负载均衡。
参考
[1] https://www.modb.pro/db/141171
[2] https://www.cnblogs.com/duanxz/p/5020398.html
[3] https://www.cnblogs.com/dennyzhangdd/p/15035116.html
[4] https://www.alibabacloud.com/blog/rocketmq-5-0-architecture-analysis-how-to-support-diversified-scenarios-based-on-cloud-native-architecture_600564
[5] https://cloud.tencent.com/developer/article/2277381
[6] https://www.cnblogs.com/hzzjj/p/16552514.html
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 图解 RocketMQ 架构

发表评论 取消回复