1.项目背景
保险单是一种安排,公司承诺为特定的损失、损坏、疾病或死亡提供赔偿保证,以换取支付指定的保费。保费是客户需要定期向保险公司支付的一笔钱,以提供此保证,与医疗保险一样,也有车辆保险,客户每年都需要向保险公司支付一定金额的保险费,以便在车辆不幸发生事故时,保险公司将向客户提供赔偿(称为“保额”)。现在需要建立一个模型,以预测过去一年的投保人(客户)是否也会对公司提供的车辆保险感兴趣。
本项目通过对训练集和测试集进行一致性检验,确保它们在特征分布上的一致性。接着进行了客户感兴趣的影响因素分析,并建立了随机森林模型和XGBoost模型,可能对新的车辆保险产品感兴趣,从而有效地规划其营销策略和优化业务模式。
2.数据说明
| 英文特征名 | 中文翻译 | 描述 |
|---|---|---|
| id | 客户ID | 客户的唯一标识符 |
| Gender | 性别 | 客户的性别(男/女) |
| Age | 年龄 | 客户的年龄 |
| Driving_License | 驾照 | 如果客户有驾驶执照,则为1,否则为0 |
| Region_Code | 地区代码 | 客户所在地区的代码 |
| Previously_Insured | 之前投保 | 如果客户之前已投保车辆保险,则为1,否则为0 |
| Vehicle_Age | 车辆年龄 | 车辆的年龄 |
| Vehicle_Damage | 车辆损坏 | 如果客户的车辆曾经损坏,则为1,否则为0 |
| Annual_Premium | 年保费 | 客户每年需要支付的保费金额 |
| Policy_Sales_Channel | 保单销售渠道 | 与客户接触的渠道的匿名代码,即不同的代理、邮件、电话、面对面等 |
| Vintage | 客户关系天数 | 客户与公司关系的天数 |
| Response | 响应 | 客户是否对车辆保险感兴趣,如果客户对车辆保险感兴趣,则为1,否则为0 |
3.Python库导入及数据读取
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.stats import chi2_contingency,ks_2samp,spearmanr
from sklearn.model_selection import train_test_split,RandomizedSearchCV
from imblearn.over_sampling import RandomOverSampler
from sklearn.ensemble import RandomForestClassifier
import xgboost as xgb
from sklearn.metrics import classification_report,confusion_matrix,roc_curve, auc,precision_recall_curve,precision_recall_fscore_support
from joblib import Parallel, delayed
train_data = pd.read_csv("/home/mw/input/08054086/train.csv")
test_data = pd.read_csv("/home/mw/input/08054086/test.csv")
4.数据一致性检验
通过对训练集与测试集进行分析,确保测试集和训练集在特征分布上是一致的,这有助于确认模型在训练过程中学到的规律在测试数据上也是适用的。
4.1数据预览
训练集信息:
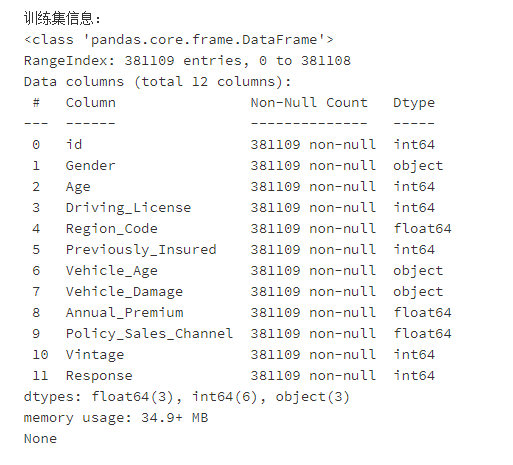
测试集信息:
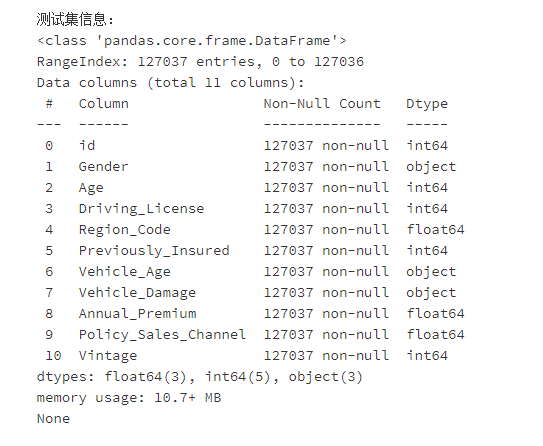
4.2可视化分析
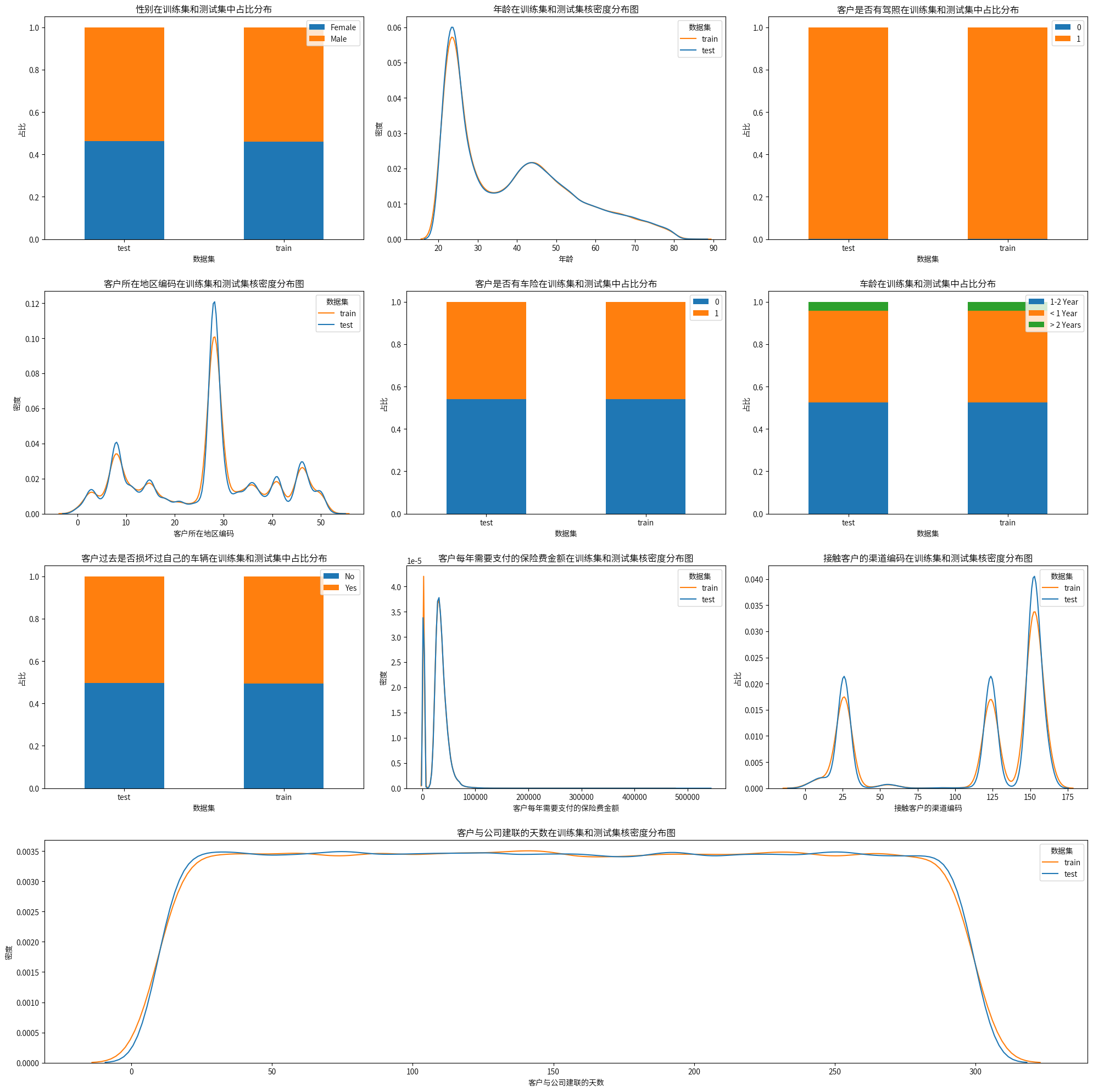
通过对两个数据集进行可视化分析,可以初步认为两个数据具有一致性,当然为了进一步验证两个数据之间的一致性,接下来将使用统计检验确保两个数据的一致性。
4.3卡方检验
对于分类变量,可以使用卡方检验(Chi-Square Test)来检验两个数据集在分类变量上的分布是否一致。
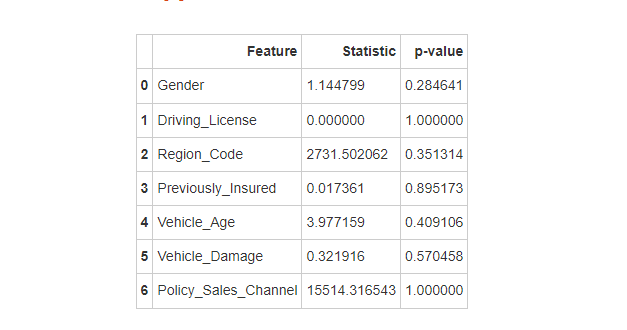
通过卡方检验,发现所有分类变量的p值均大于0.05,说明训练集和测试集在这些特征上的分布没有显著差异。
4.4KS检验
Kolmogorov-Smirnov检验(KS检验):用于检验两个样本是否来自相同的分布。
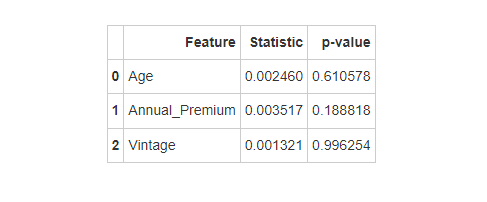
通过KS检验,所有数值变量的p值均大于0.05,说明训练集和测试集在这些特征上的分布没有显著差异。
综上所述,可以认为训练集和测试集在特征分布上是一致的,因此可以只对训练集进行进一步的分析和模型训练,将简化分析过程,并确保模型在测试集上的评估具有代表性。
5.客户感兴趣的影响因素分析
5.1可视化分析
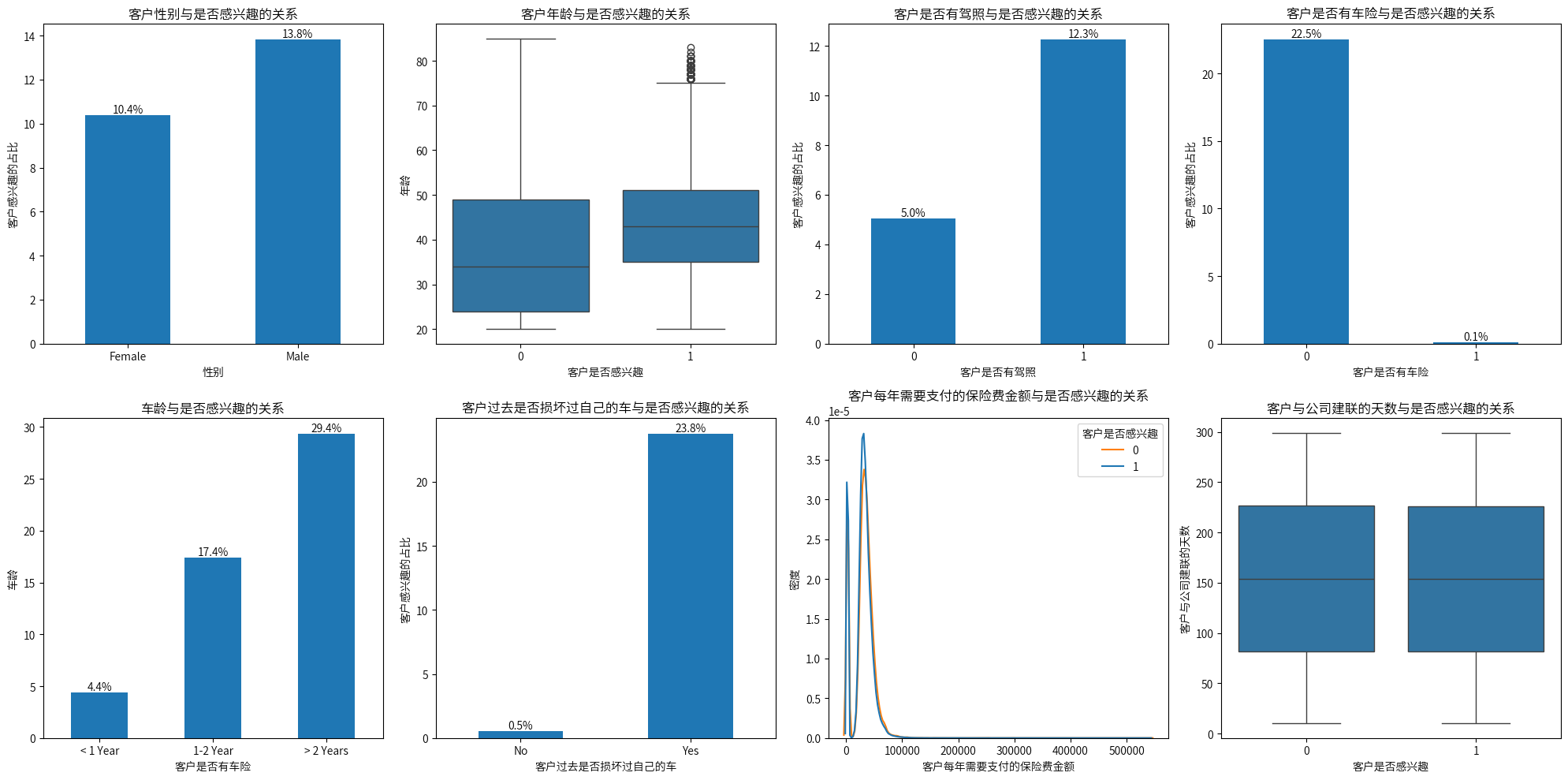
通过可视化分析,可以直观的观察到:
-
男性客户比女性客户对车辆保险感兴趣的占比更大。
-
对汽车保险感兴趣的客户年龄分布中位数更高,不感兴趣的客户年龄分布更广,这可能反映了中年客户对汽车保险的需求较高。
-
有驾照的客户更有可能拥有车辆,因此对汽车保险更感兴趣。
-
已经投过车险的客户明显对这个汽车保险不感兴趣,因此,后续营销推广的时候,可以减少与这些客户的接触。
-
老旧车辆的客户对汽车保险需求更大,因此,可以多接触这类客户进行推广。
-
经历过车辆损坏的客户更倾向于购买保险。
-
对汽车保险感兴趣的客户和不感兴趣的客户在年度保费的分布上没有显著差异,分布形态较为相似,表明年保费对客户兴趣的影响较小。
-
对汽车保险感兴趣的客户和不感兴趣的客户在与公司建联的天数上没有显著差异,表明客户与公司的关系长短对其兴趣影响不大。
5.2斯皮尔曼相关性分析
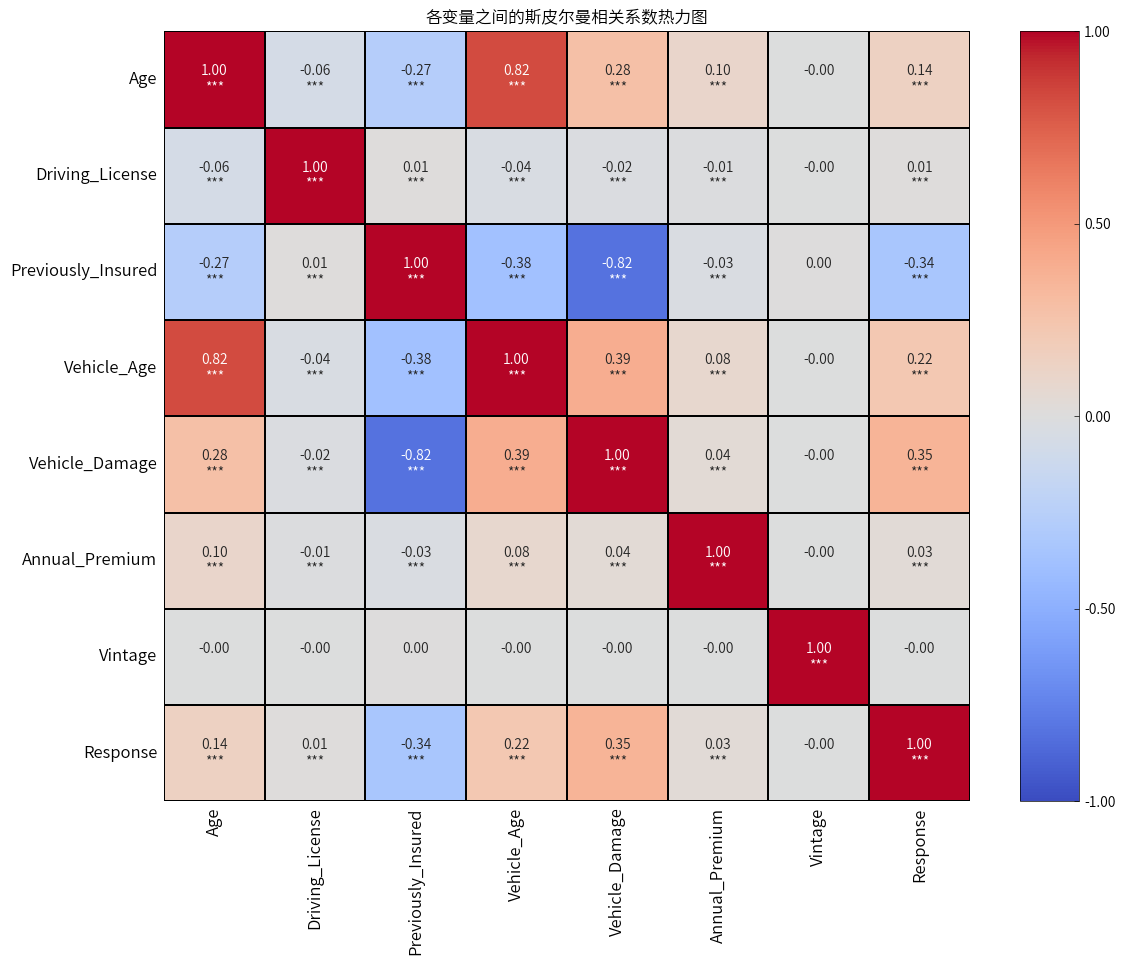
-
年龄与客户对车辆保险的兴趣呈正相关,即年龄越大,客户对车辆保险的兴趣越高。
-
是否有驾照与客户对车辆保险的兴趣显著,但是相关性才0.01,这种情况通常发生在样本量非常大的时候,因为即使是非常微小的相关性在大样本中也可能被检测为显著。
-
之前是否投保与客户对车辆保险的兴趣呈负相关,之前有投保的客户对新车保险的兴趣较低。
-
车龄与客户对车辆保险的兴趣呈正相关,即车辆越老,客户对车辆保险的兴趣越高。
-
车辆是否损坏与客户对车辆保险的兴趣呈正相关,即曾经损坏过车辆的客户对车辆保险的兴趣较高。
-
年度保费与客户对车辆保险的兴趣显著,但是相关性才0.03,同理也可能是大样本导致的。
-
与公司建联的天数与客户对车辆保险的兴趣没有相关性。
5.3卡方检验
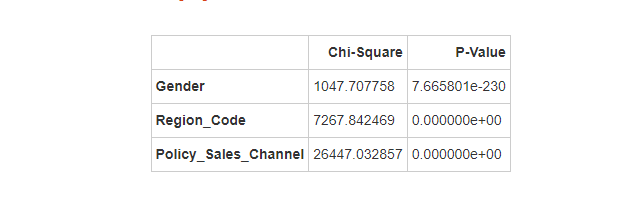
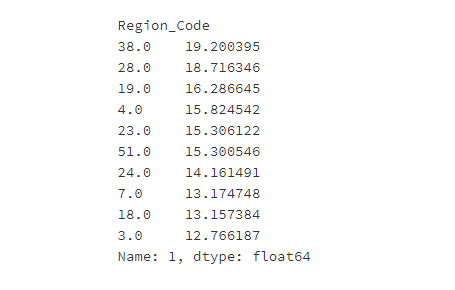
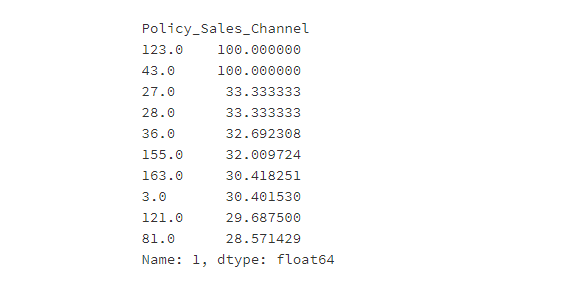
123这个与客户接触的渠道的匿名代码共有:1条。 43这个与客户接触的渠道的匿名代码共有:1条。
通过卡方检验发现:性别、客户所在地区的代码、与客户接触的渠道的匿名代码与客户是否对车辆保险感兴趣有显著关系,并且地区38、28、19客户感兴趣的占比比其他地区大,123、43这两个与客户接触的渠道的匿名代码才1条,不具有代表性,27、28、36、155、163这5个与客户接触的渠道能较大可能的让客户感兴趣。
6.随机森林
6.1数据预处理
客户感兴趣的样本共有:46710条,占比:0.12。
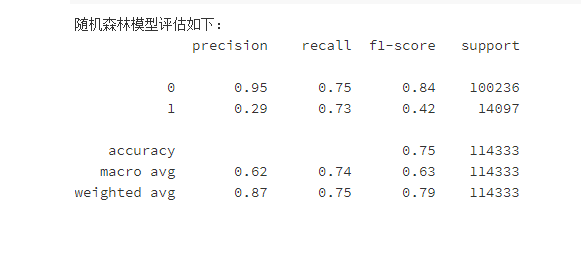
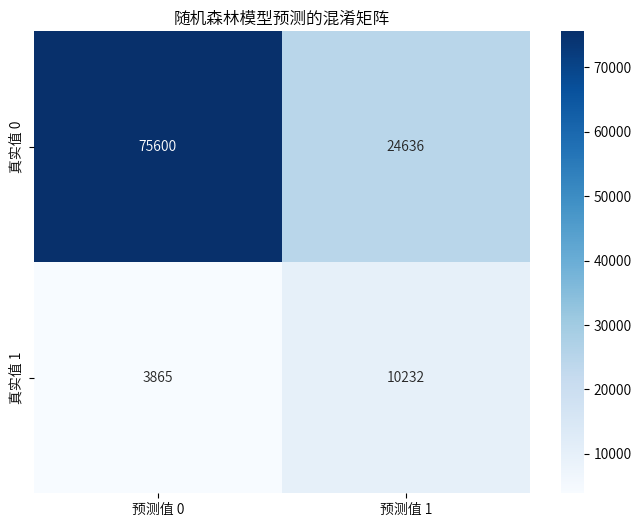
6.2建立模型
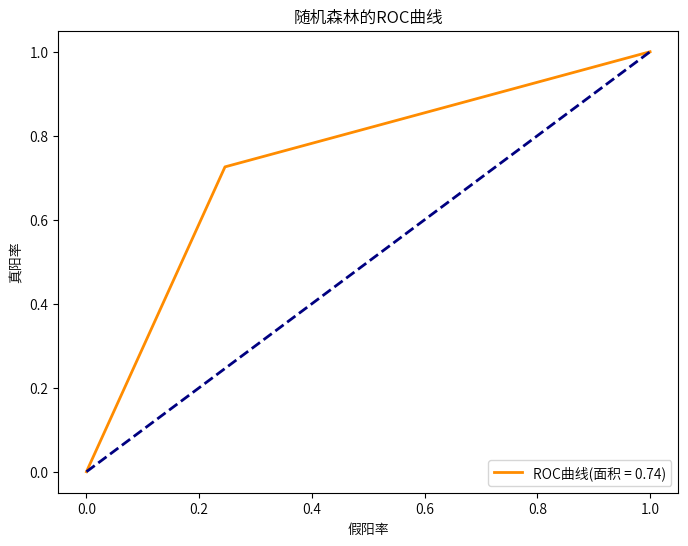
6.3优化参数
最佳参数: {'n_estimators': 50, 'min_samples_split': 2, 'min_samples_leaf': 1, 'max_features': 'log2', 'max_depth': 30}
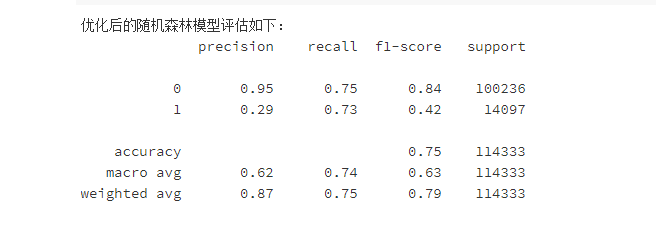
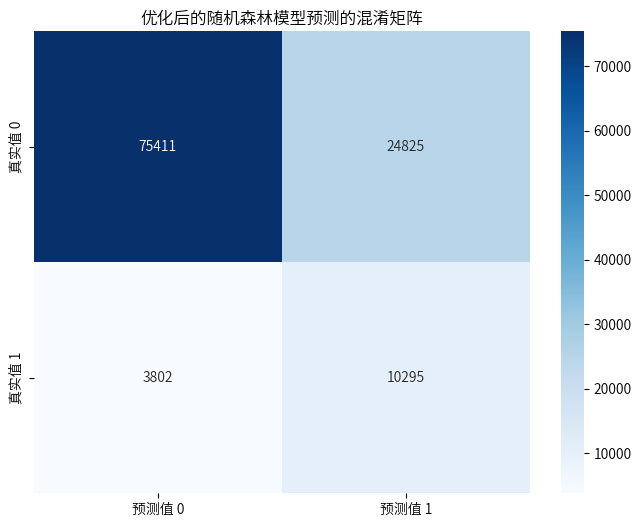
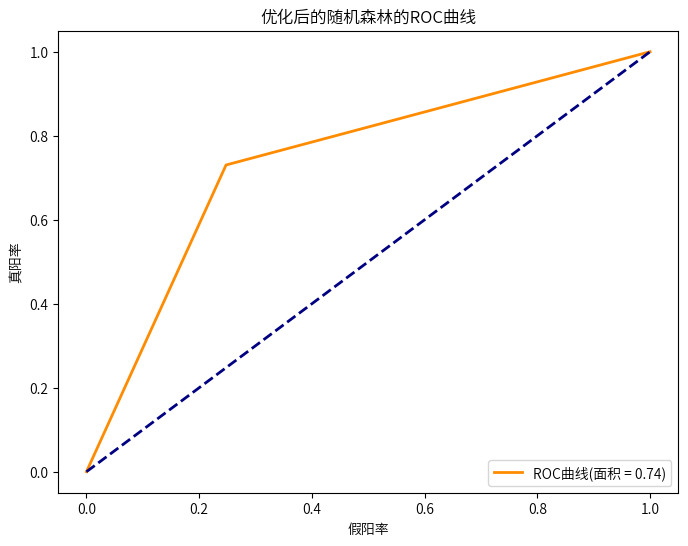
6.4调整决策阈值
默认情况下,分类模型使用0.5作为决策阈值,即预测概率大于等于0.5的样本被分类为正类,反之为负类。然而,这个默认阈值未必总是最佳的。通过调整决策阈值,可以改变模型的分类决策,从而优化特定评估指标。例如:
-
提高阈值可以减少假阳性,从而提高精确率。
-
降低阈值可以减少假阴性,从而提高召回率。
最佳阈值: 0.6338067939336395
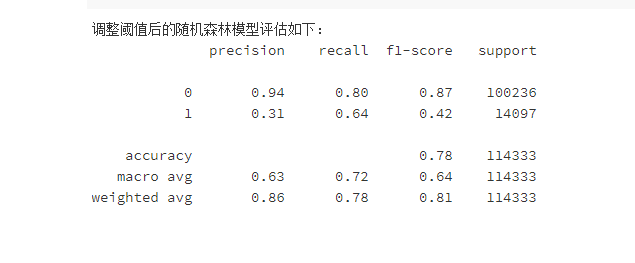
6.5重要度分析
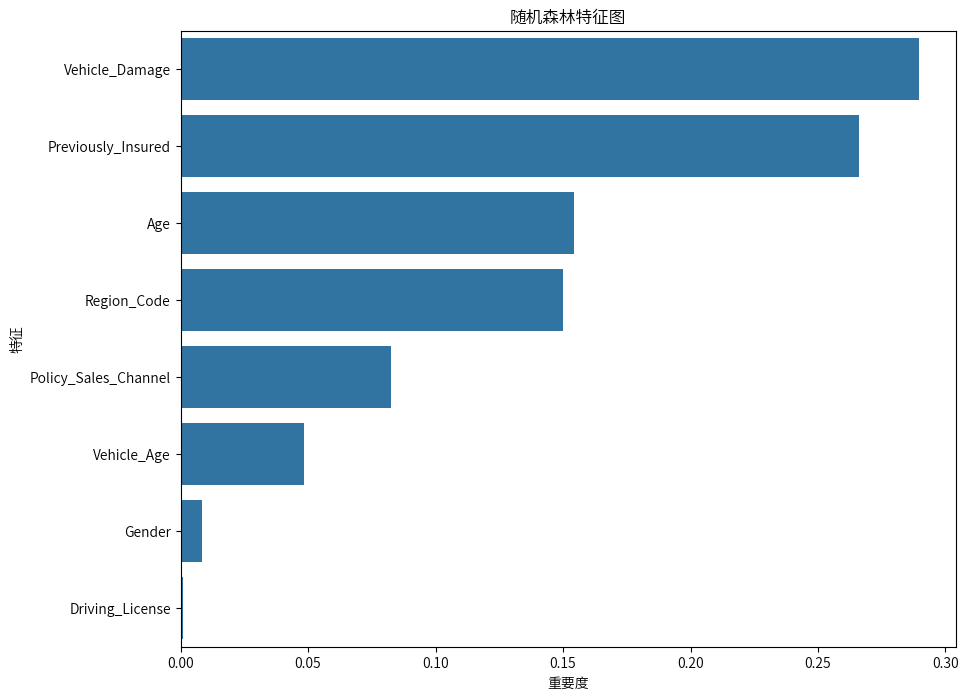
优化后的模型,提升并不明显,但是通过调整策略阈值后,预测准确率也还及格,最终输出了影响模型的重要因素,“客户的车辆曾经是否损坏”、“客户之前是否已投保车辆保险”这两个因素在模型预测的时候比较重要。
7.XGBoost
7.1建立模型
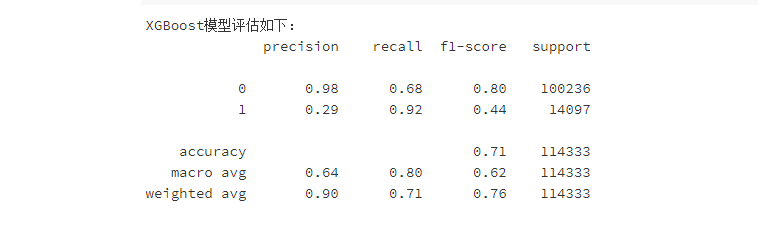
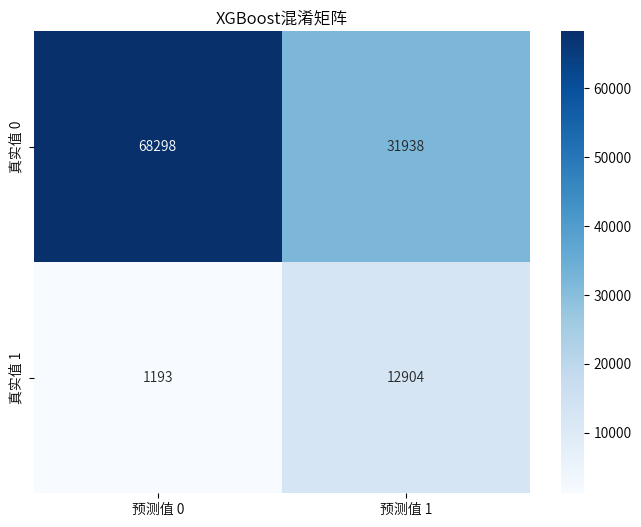
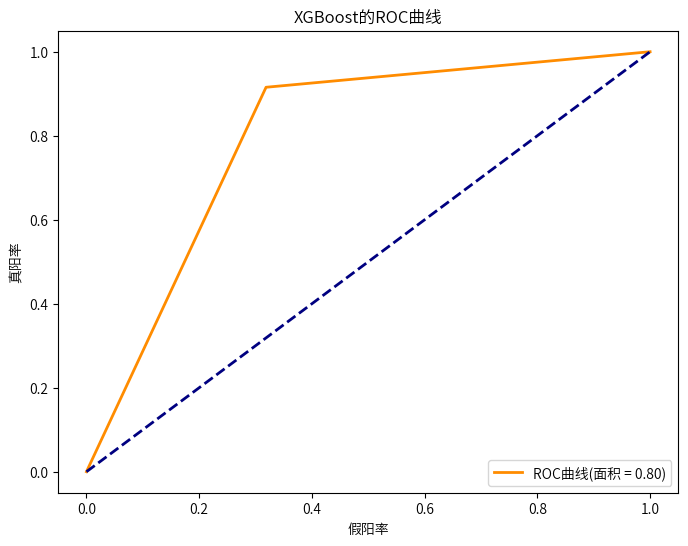
7.2优化参数
最佳参数: {'subsample': 0.8, 'n_estimators': 400, 'min_child_weight': 1, 'max_depth': 10, 'learning_rate': 0.1, 'gamma': 0.1, 'colsample_bytree': 0.9}
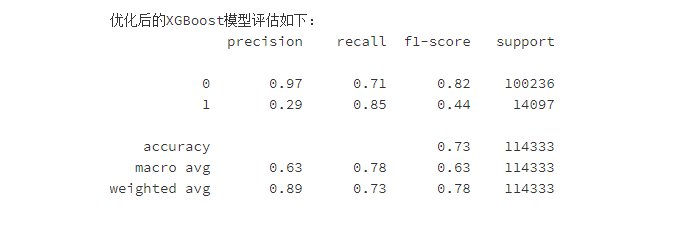
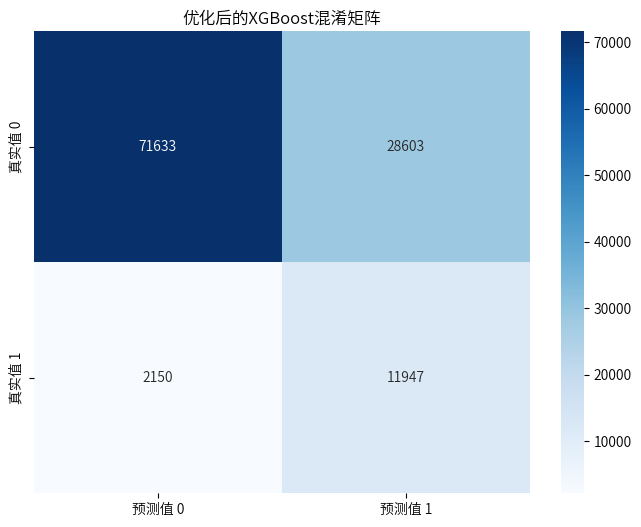
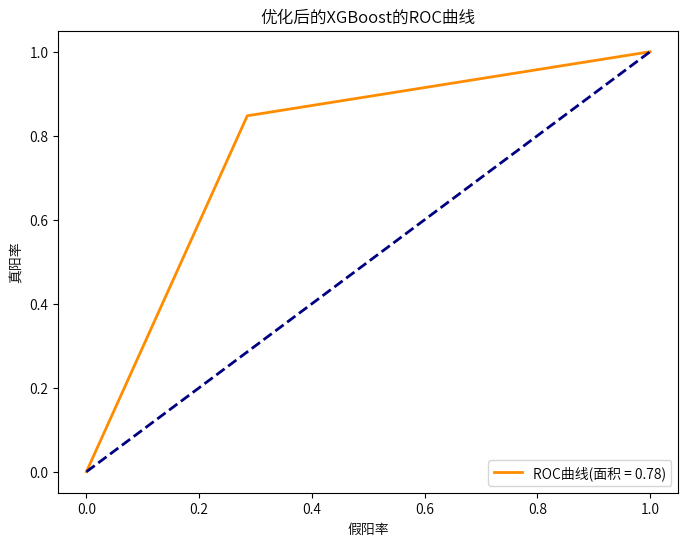
7.3调整决策阈值
最佳阈值: 0.6731685
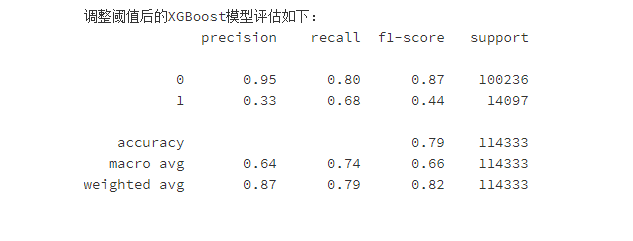
7.4重要度分析
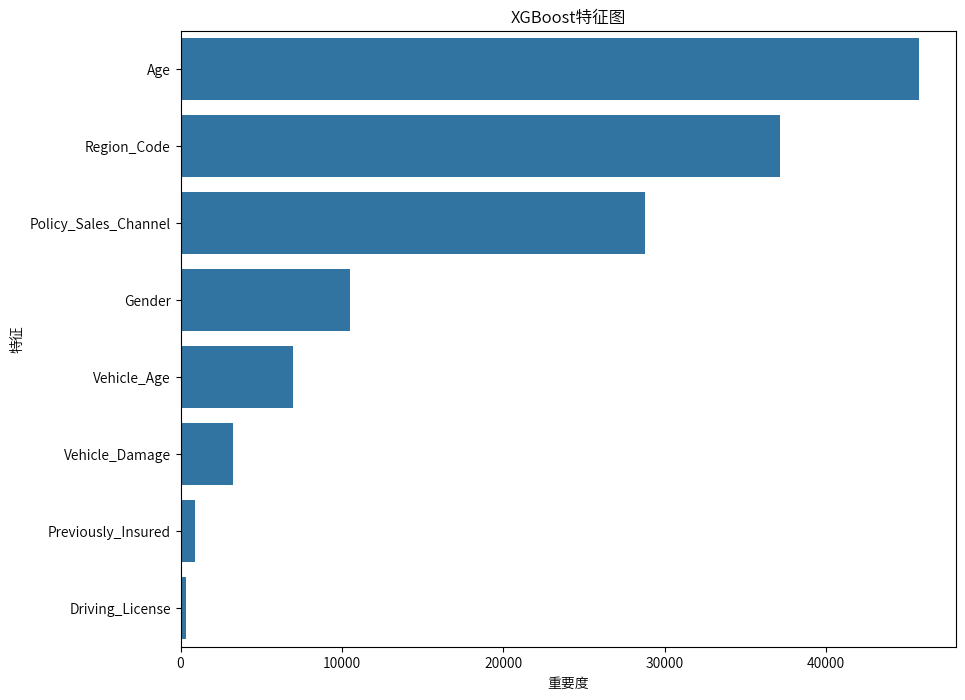
XGBoost模型一开始预测的准确率略低于随机森林模型,但是随着不断的调整优化,略高于随机森林模型了,并且输出重要特征为:“客户的年龄”、“客户所在地区的代码”、“与客户接触的渠道的匿名代码”。
8.对测试集预测
8.1数据预处理
仿照处理训练集的方法一样,只不过这里不用划分数据了,后续用建好的模型就可以预测了。
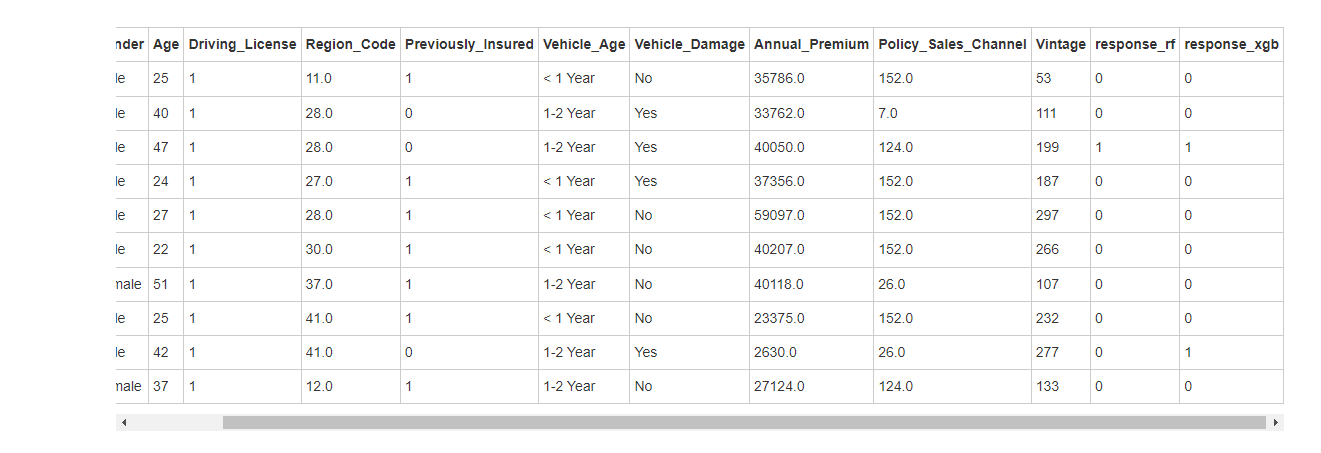
8.2使用随机森林和XGBoost预测
9.总结
本项目通过对训练集和测试集进行一致性检验,确保它们在特征分布上的一致性。接着进行了客户感兴趣的影响因素分析,并建立了随机森林模型和XGBoost模型。通过不断优化模型和调整策略阈值,得到了最终的模型和最优阈值,并对测试集进行了预测。具体结论如下:
-
数据一致性检验:通过可视化分析、卡方检验和KS检验,确认训练集和测试集在特征分布上是一致的,确保模型在测试集上的评估具有代表性。
- 影响因素分析:利用可视化分析、斯皮尔曼相关性分析和卡方检验发现以下结论:
-
男性客户比女性客户对车辆保险更感兴趣。
-
中年客户对汽车保险的需求较高。
-
有驾照的客户对汽车保险更感兴趣。
-
已经投过车险的客户对这个汽车保险明显不感兴趣。
-
老旧车辆的客户对汽车保险需求更大。
-
车辆曾经损坏的客户更倾向于购买保险。
-
客户所在地区的代码以及与客户接触的渠道的匿名代码与客户是否对车辆保险感兴趣有显著关系。其中,地区代码38、28、19的客户对保险的兴趣占比高于其他地区,渠道代码27、28、36、155、163的接触方式能较大可能引起客户的兴趣。
-
-
随机森林模型:在该模型中,重要特征包括“客户的车辆曾经是否损坏”和“客户之前是否已投保车辆保险”。
-
XGBoost模型:在该模型中,重要特征包括“客户的年龄”、“客户所在地区的代码”和“与客户接触的渠道的匿名代码”。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 基于统计检验与机器学习研究客户对保险兴趣的因素

发表评论 取消回复