前言
当数据量较小时,Redis 会优先考虑用 ziplist 来存储 hash、list、zset,这么做可以有效的节省内存空间,因为 ziplist 是一块连续的内存空间,它采用一种紧凑的方式来存储元素。但是它也有缺点,比如查找的时间复杂度高、内存分配的开销、连锁更新的风险等。
于是 Redis 在 3.0 版本推出了 quicklist,它可以看作是 ziplist 的升级版,本质是把多个 ziplist 串联成链表,把每个 ziplist 限制在一定的大小,以此来降低 内存分配、连锁更新 的影响,但是它并没有完全解决连锁更新的问题,并且链表的每个节点也是要额外占用内存的。
Redis 5.0 终于推出了一个新的紧凑列表 listpack,它沿用了 ziplist 的内存布局,元素紧挨在一起,没有指针的额外开销,同时解决了连锁更新的问题。
一、ziplist
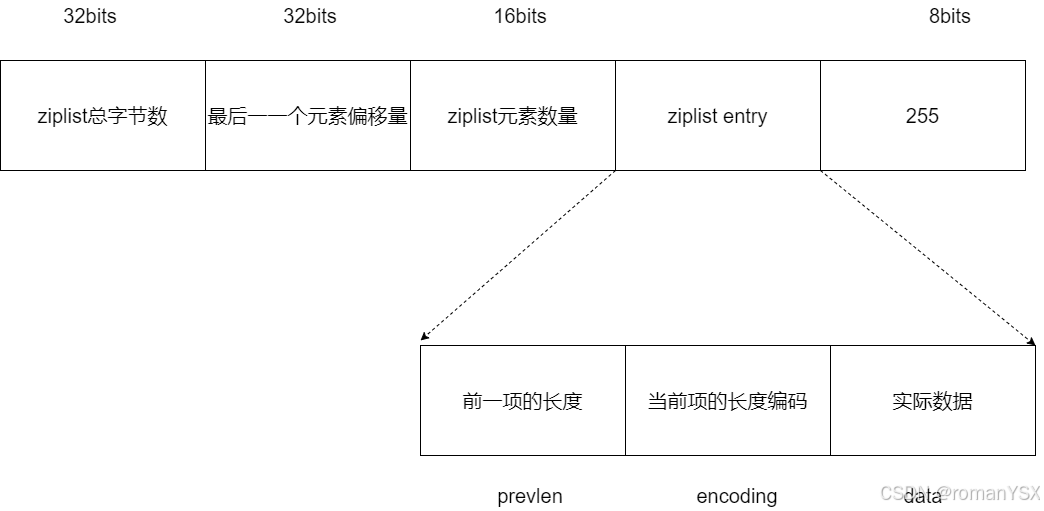
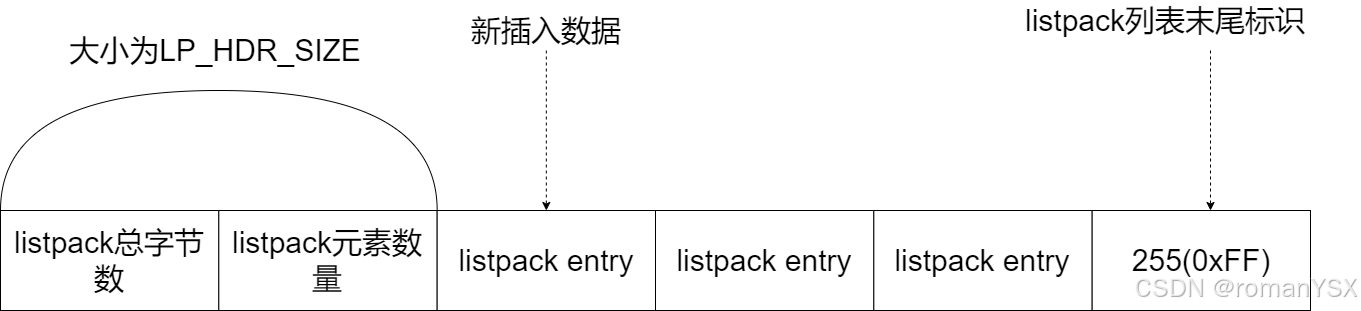
一个 ziplist 数据结构在内存中的布局,就是一块连续的内存空间。这块空间的起始部分是大小固定的 10 字节元数据,其中记录了 ziplist 的总字节数、最后一个元素的偏移量以及列表元素的数量,而这 10 字节后面的内存空间则保存了实际的列表数据。在 ziplist 的最后部分,是一个 1 字节的标识(固定为 255),用来表示 ziplist 的结束,如下图所示:
不过,虽然 ziplist 通过紧凑的内存布局来保存数据,节省了内存空间,但是 ziplist 也面临着随之而来的两个不足:查找复杂度高和潜在的连锁更新风险。那么下面,我们就分别来了解下这两个问题。
1.1 ziplist 查找复杂度高
因为 ziplist 头尾元数据的大小是固定的,并且在 ziplist 头部记录了最后一个元素的位置,所以,当在 ziplist 中查找第一个或最后一个元素的时候,就可以很快找到。
但问题是,当要查找列表中间的元素时,ziplist 就得从列表头或列表尾遍历才行。而当 ziplist 保存的元素过多时,查找中间数据的复杂度就增加了。更糟糕的是,如果 ziplist 里面保存的是字符串,ziplist 在查找某个元素时,还需要逐一判断元素的每个字符,这样又进一步增加了复杂度。
也正因为如此,我们在使用 ziplist 保存 Hash 或 Sorted Set 数据时,都会在 redis.conf 文件中,通过 hash-max-ziplist-entries 和 zset-max-ziplist-entries 两个参数,来控制保存在 ziplist 中的元素个数。
不仅如此,除了查找复杂度高以外,ziplist 在插入元素时,如果内存空间不够了,ziplist 还需要重新分配一块连续的内存空间,而这还会进一步引发连锁更新的问题。
1.2 ziplist 连续更新风险
举个简单的例子,当在一个元素 A 前插入一个新的元素 B 时,A 的 prevlen 和 prevlensize 都要根据 B 的长度进行相应的变化。那么现在,我们假设 A 的 prevlen 原本只占用 1 字节(也就是 prevlensize 等于 1),而能记录的前一项长度最大为 253 字节。此时,如果 B 的长度超过了 253 字节,A 的 prevlen 就需要使用 5 个字节来记录,这样就需要申请额外的 4 字节空间了。不过,如果元素 B 的插入位置是列表末尾,那么插入元素 B 时,我们就不用考虑后面元素的 prevlen 了。
实际上,所谓的连锁更新,就是指当一个元素插入后,会引起当前位置元素新增 prevlensize 的空间。而当前位置元素的空间增加后,又会进一步引起该元素的后续元素,其 prevlensize 所需空间的增加。
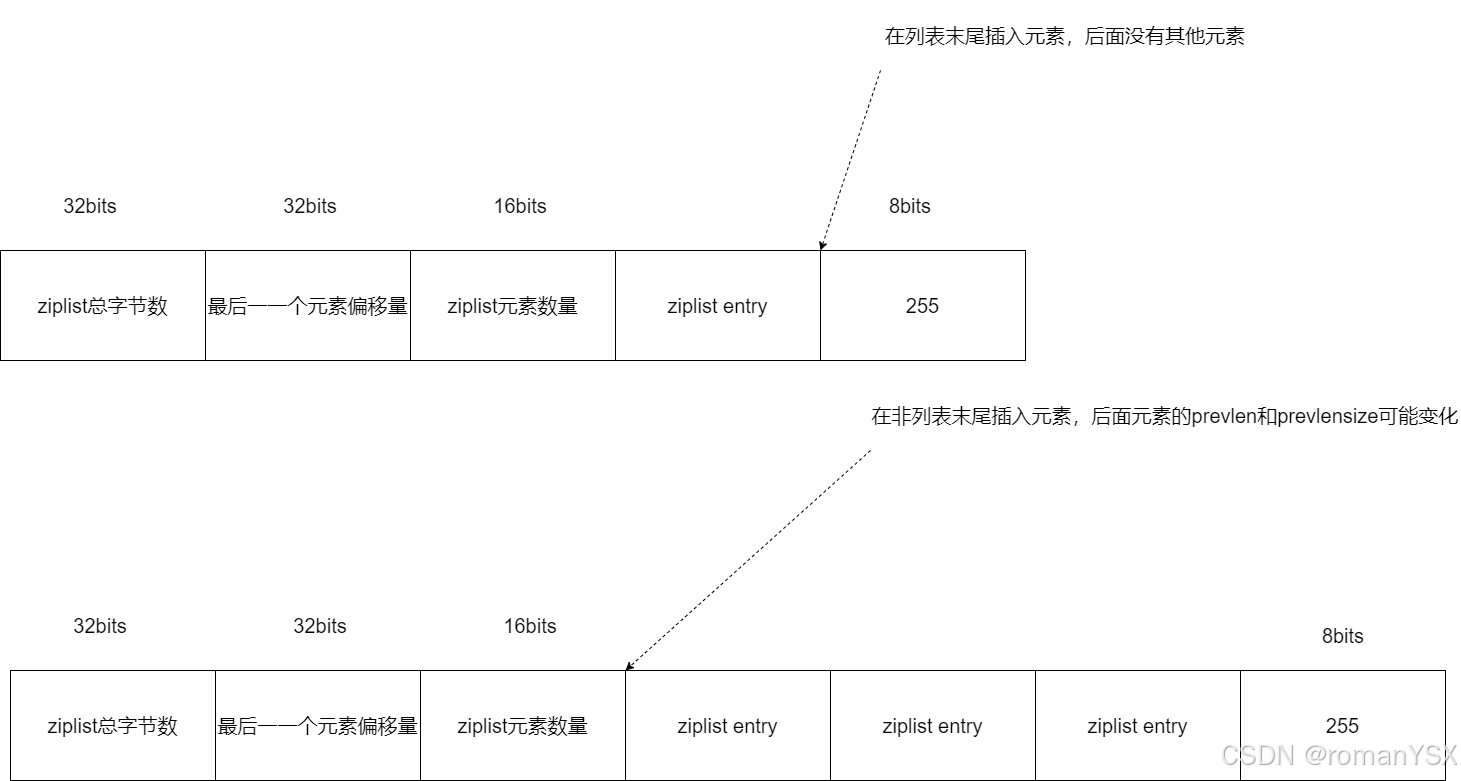
这样,一旦插入位置后续的所有元素,都会因为前序元素的 prevlenszie 增加,而引起自身空间也要增加,这种每个元素的空间都需要增加的现象,就是连锁更新。如下图:
连锁更新一旦发生,就会导致 ziplist 占用的内存空间要多次重新分配,这就会直接影响到 ziplist 的访问性能。所以说,虽然 ziplist 紧凑型的内存布局能节省内存开销,但是如果保存的元素数量增加了,或是元素变大了,ziplist 就会面临性能问题。那么,有没有什么方法可以避免 ziplist 的问题呢?这就是接下来我要给你介绍的 quicklist 和 listpack,这两种数据结构的设计思想了。
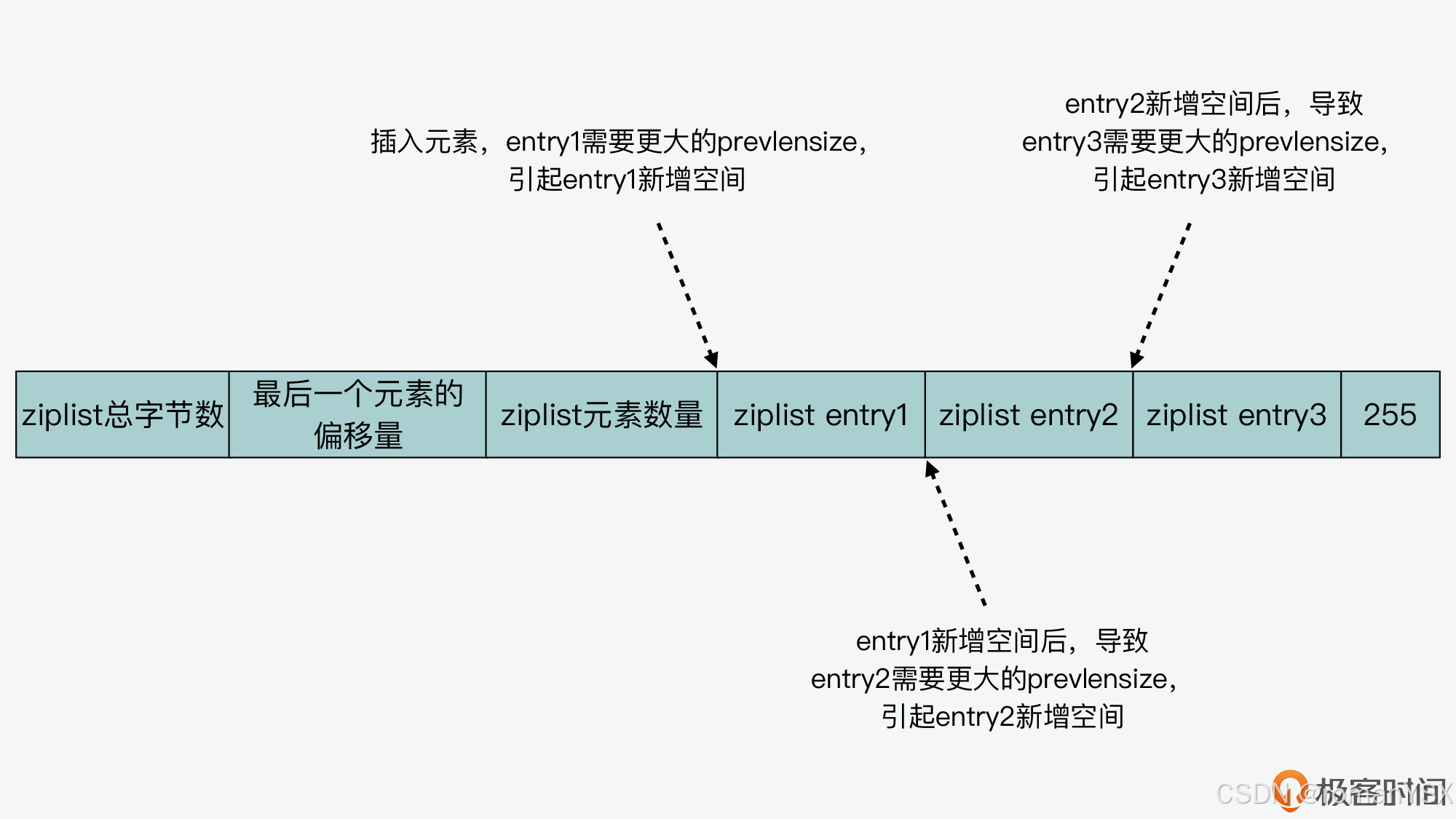
二、quicklist
quicklist 的设计,其实是结合了链表和 ziplist 各自的优势。简单来说,一个 quicklist 就是一个链表,而链表中的每个元素又是一个 ziplist。
而也正因为 quicklist 采用了链表结构,所以当插入一个新的元素时,quicklist 首先就会检查插入位置的 ziplist 是否能容纳该元素,这是通过 _quicklistNodeAllowInsert 函数来完成判断的。
_quicklistNodeAllowInsert 函数会计算新插入元素后的大小(new_sz),这个大小等于 quicklistNode 的当前大小(node->sz)、插入元素的大小(sz),以及插入元素后 ziplist 的 prevlen 占用大小。在计算完大小之后,_quicklistNodeAllowInsert 函数会依次判断新插入的数据大小(sz)是否满足要求,即单个 ziplist 是否不超过 8KB,或是单个 ziplist 里的元素个数是否满足要求。只要这里面的一个条件能满足,quicklist 就可以在当前的 quicklistNode 中插入新元素,否则 quicklist 就会新建一个 quicklistNode,以此来保存新插入的元素。
这样一来,quicklist 通过控制每个 quicklistNode 中,ziplist 的大小或是元素个数,就有效减少了在 ziplist 中新增或修改元素后,发生连锁更新的情况,从而提供了更好的访问性能。而 Redis 除了设计了 quicklist 结构来应对 ziplist 的问题以外,还在 5.0 版本中新增了 listpack 数据结构,用来彻底避免连锁更新。
三、listpack
listpack 也叫紧凑列表,它的特点就是用一块连续的内存空间来紧凑地保存数据,同时为了节省内存空间,listpack 列表项使用了多种编码方式,来表示不同长度的数据,这些数据包括整数和字符串。
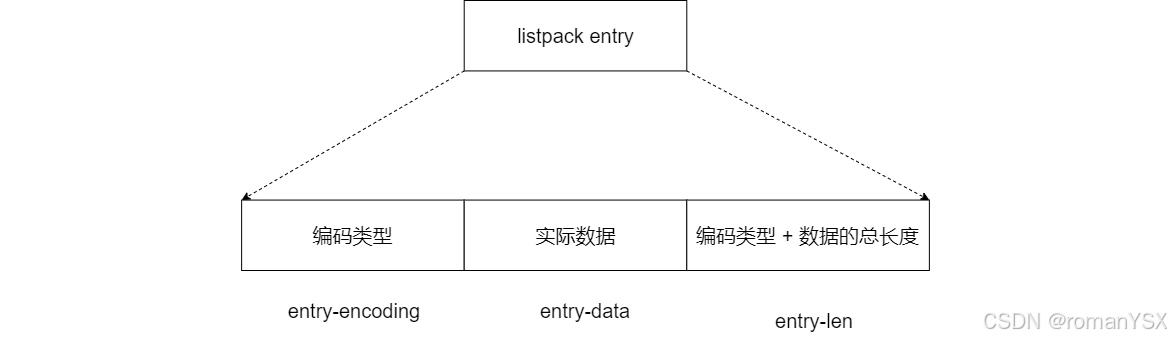
好了,了解了 listpack 的整体结构后,我们再来看下 listpack 列表项的设计。和 ziplist 列表项类似,listpack 列表项也包含了元数据信息和数据本身。不过,为了避免 ziplist 引起的连锁更新问题,listpack 中的每个列表项不再像 ziplist 列表项那样,保存其前一个列表项的长度,它只会包含三个方面内容,分别是:
- 当前元素的编码类型(entry-encoding)
- 元素数据 (entry-data)
- 以及编码类型和元素数据这两部分的长度 (entry-len)
如下图所示:
在 listpack 中,因为每个列表项只记录自己的长度,而不会像 ziplist 中的列表项那样,会记录前一项的长度。所以,当我们在
listpack 中新增或修改元素时,实际上只会涉及每个列表项自己的操作,而不会影响后续列表项的长度变化,这就避免了连锁更新。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » redis的紧凑列表ziplist、quicklist、listpack

发表评论 取消回复