本文由Markdown语法编辑器编辑完成。
1.背景:
我们的产品是通过docker image的方式发布,并且编排在docker-compose.yml中发布。在同一个docker-compose.yml中的服务,相互之间,可以通过对方的服务名和端口,来直接访问,而无需知道对方服务的ip地址,这样对于接口的url的拼接和识别,带来了很大的好处。
然而,当我们的产品,近期在某一家医院上线后,却发现了之前未曾遇到的问题,就是同一个docker-compose.yml中的服务,使用服务名进行访问时,无法访问,导致很多依赖接口的功能无法正常使用。
具体的微服务架构大致如下:
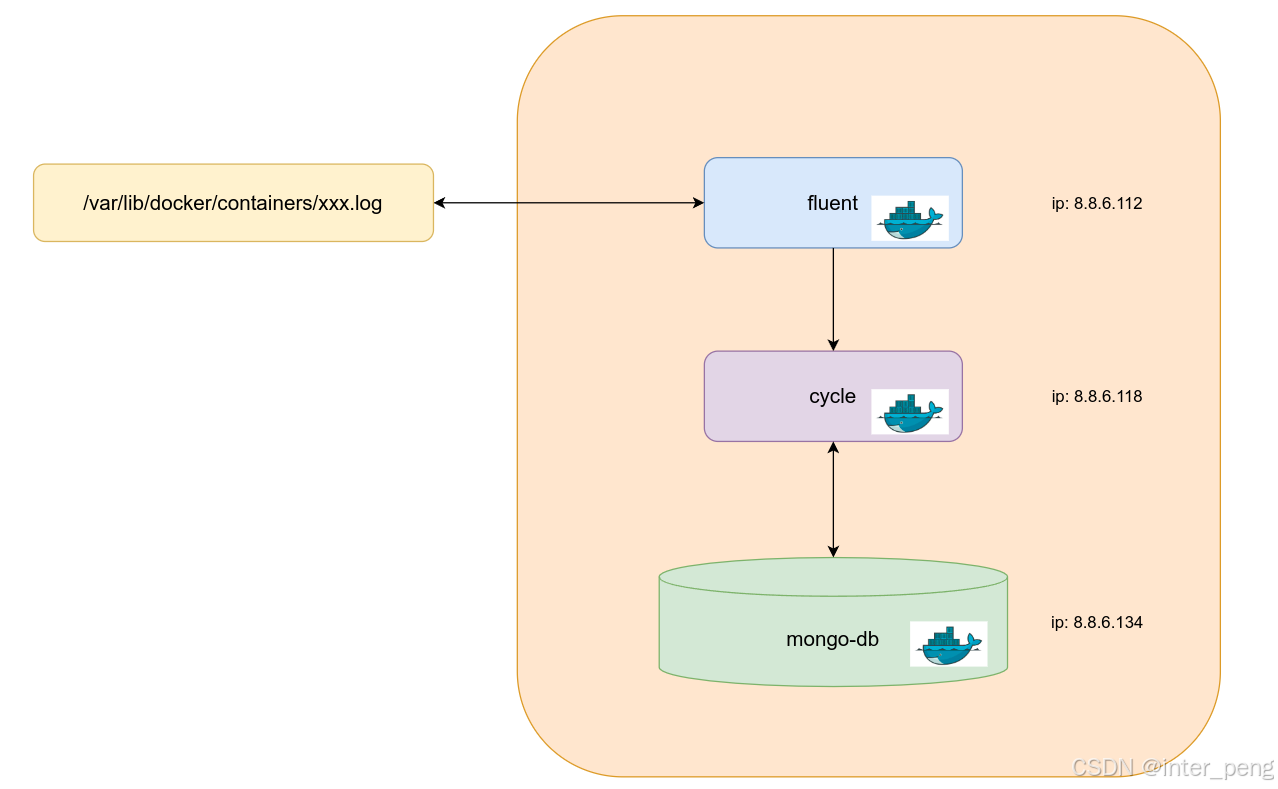
fluent服务,会持续地从/var/lib/docker/containers目录下,读取里面的所有容器的docker日志。每一个容器,会有一个hashid. 这个日志文件的名称,就是以这个服务的hash id命名的。fluent采集到各个容器的json格式的日志后,经过一定的筛选,将符合要求的日志,通过cycle提供的接口,通知给cycle服务;
cycle服务, 将日志转化成dict的形式,存到mongo db数据库中。每一条记录,都会包含患者和检查的一些信息。
当前端需要查看某个患者或某个检查的处理记录时,cycle服务从mongo-db中读取出记录,并按照时间顺序,将它们组成一颗树,展示给运维人员。
异常情况发生:
这套服务,在公司的测试环境,和其他医院,都可以正常的工作。但是,在这家医院,前端根据患者ID查询时,却无法正常展示。通过查看fluent服务和cycle服务的日志。
cycle服务,没有出现异常的日志;而fluent服务,则一直在刷warn和error的日志。我对照公司的测试环境,fluent服务,运行时是没有出现这样的warn和error日志的。异常的日志如下图所示:
它提示无法连接到cycle服务。因此,即使它搜集到了日志信息,但无法将日志信息,通知给cycle服务。大概的报错日志和原因如下:
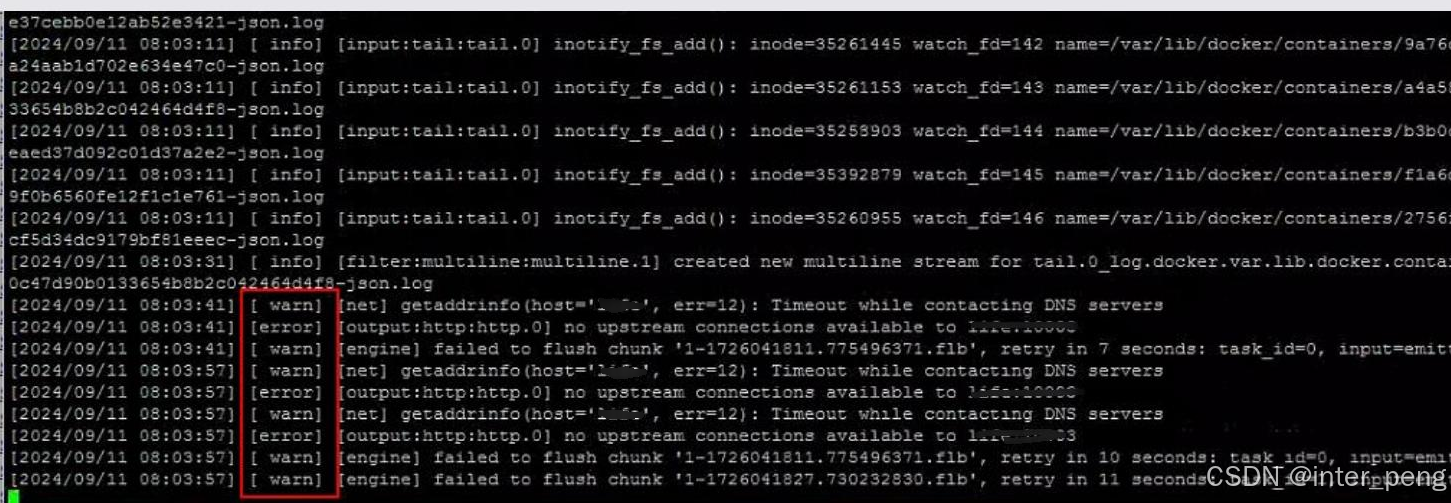
其中比较关键的错误信息如下:
[error] no upstream connection available to xxxx:1000x
[warn] [engine] failed to flush chunk xxx, retry in 7 seconds...
[warn] [net] getaddrinfo(host='xxxx', err=12):Timeout while contacting DNS servers
......
通过查询引起该问题的可能原因,大致的回答如下:
from kimi chat:
这段错误信息是来自一个网络服务或应用程序的日志,通常出现在尝试连接到某个服务或主机时遇到问题。具体来说,"getaddrinfo(host='xxxx', err=12):Timeout while contacting DNS servers" 表示在尝试解析主机名 'xxxx' 时,DNS 查询超时了。这通常意味着应用程序无法在预定的时间内从DNS服务器获取到所需的IP地址信息。
- `getaddrinfo` 是一个网络函数,用于根据主机名获取其IP地址。
- `host='xxxx'` 表示正在尝试解析的主机名。
- `err=12` 是错误代码,通常与超时有关。
- "Timeout while contacting DNS servers" 明确指出了问题:在尝试联系DNS服务器时发生了超时。
这种情况可能是由于网络连接问题、DNS服务器不可用或响应过慢等原因造成的。解决这类问题通常需要检查网络连接,确认DNS服务器的可用性,或者尝试更换DNS服务器。
分析后,大概原因是,容器间通过服务名访问时,docker在底层会做一个DNS的解析,也就是将服务的名称,解析出服务的真实ip. 因为在docker-compose.yml中,每一个服务,都一定会被分配一个ip.
网络请求,最终其实还是通过ip:port/interface_url来完成的。
那么在确认了其他没有问题的情况下,归结的原因大概是DNS解析过慢,造成无法及时解析出IP,导致连接超时了。
既然是因为DNS解析的速度,那么我们就希望能够绕过这个DNS的解析环节。那要跳过DNS解析,只有事先知道对方服务的ip和端口才可以。
因此,解决问题的思路和方案大致如下:
1> 为cycle服务,在docker-compose中,指定一个固定ip地址;
2> fluent服务,请求cycle服务时,按照cycle那里固定的ip,进行访问,不再通过服务名访问了。
2.问题解决:
找到解决方案后,接下来便是在docker-compose.yml里面,给相应的docker容器,赋予特定的ip了。
也就是,给cycle服务,一个特定的服务ip, 比如8.8.6.140;
而fluent服务,在请求cycle的接口时,直接通过ip:port的方式请求,这样就绕过了DNS解析这步。
2.1 在docker-compose.yml中为服务设置固定ip
通过在devv.ai上面咨询,如何给docker-compose.yml中的服务,设置固定ip, 得到了回复。
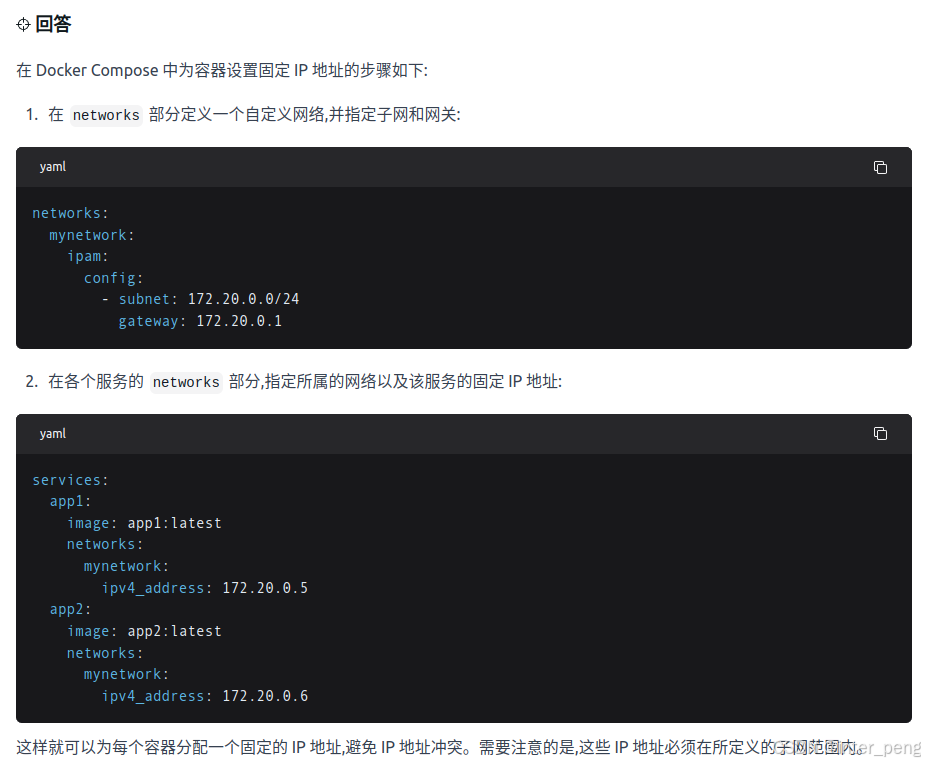
结合以上的回答,我将服务的ip设置好后,重新启动服务。结果服务一直处于无法启动的状态。
要不容器的状态是Create, 要不就是Restarting …, 总之就是无法正常的工作。


连续试了好几次都无法成功。
2.2 设置固定ip后,服务启动失败
正当愁眉不展时,咨询了研发部经理。他也感觉到很奇怪,因为修改容器的ip, 并不是什么大不了的事,设置固定ip导致容器无法启动,匪夷所思。
但是, 在启动时,docker是有一个提示的,它提示Alreay in use.
后来,我看经理把ip地址的最后一位设置得大了一些,比如之前我设置得是140。他先是修改成180, 结果还是提示Already in use.
然后又设置成222, 这次再启动,就不提示,可以正常启动了。
3. 复盘:
复盘一下,原来是由于我们的docker-compose.yml中的服务非常多。在docker-compose up -d的时候,docker会给里面的每个服务分配一个ip地址。而我提前设置好的ip地址,被docker自动提前分配给了其他服务。因此,当docker再启动我指定ip的服务时,发现这个ip, 已经被占用了,导致这个服务一直无法正常启动。
其实,我觉得docker可以有一个机制:就是先检测一下,当前的docker-compose.yml中,有没有已经被提前设置过ip的服务。如果有设置了ip地址的,那么这个ip地址,就要预留给这个服务,而不要再分配给其他的未分配ip地址的服务。
这样,可以有效地避免这个问题的发生。
希望以后高版本的docker, 可以优化这个机制。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【疑难杂症2024-005】docker-compose中设置容器的ip为固定ip后,服务无法启动

发表评论 取消回复