1. 挑战/问题
在开放词汇表图像分类中,随着时间的推移,模型需要不断学习新的标签,同时保留对旧标签的记忆。这导致几个挑战:
- 数据增量学习:模型需要在任意时间点有效地吸收新的训练样本。
- 模型持续改进:模型应在接收到新样本时不断更新和提高。
- 存储与计算效率:随着数据量的增加,如何高效存储和计算成为问题。
2. Contribution:
- 提出了一个新的开放词汇持续学习方法:anytime continual learning,目标是在收到新示例时高效改进,并保持随时预测任意标签集的能力。
- 动态权重调整:在部分微调模型和固定开放词汇表模型的预测之间动态调整权重。
- PCA压缩:引入了一种基于注意力加权的PCA压缩方法,减少存储和计算负担
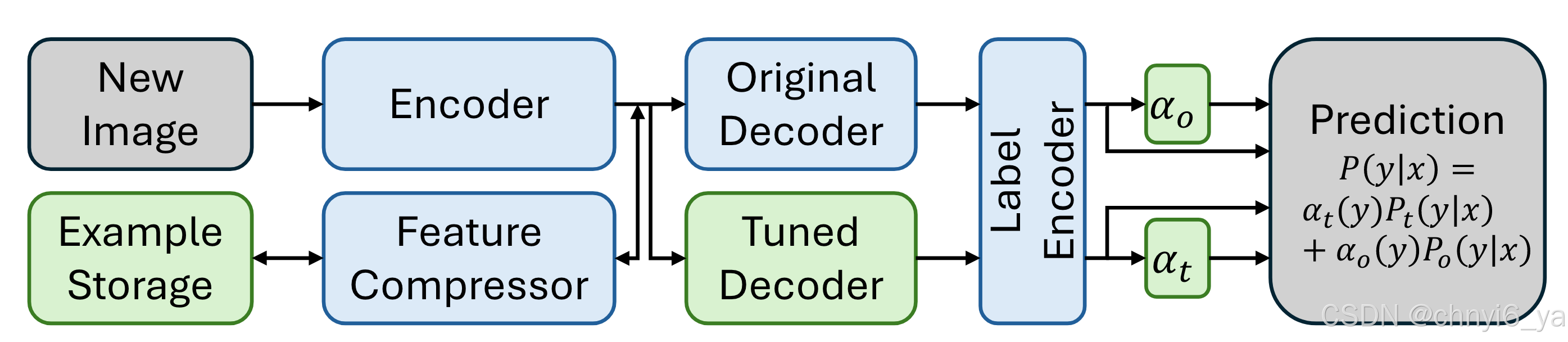
3. Method
- 对具有固定标签嵌入的特征进行部分微调;
- 在线训练,每批次由新训练样本和类平衡存储样本组成;
- 在线学习每个标签的准确性,以有效组合原始模型预测和调整后的模型预测;
- 损失修改以实现“以上都不是”预测,这也稳定了开放词汇训练;
- 中间层特征压缩可减少训练样本的存储并提高速度,而不会造成太大的准确性损失。
4. results of evaluation/experiments
论文通过一系列实验验证了提出方法的有效性:
- 灵活的学习与推理:在数据增量、类别增量和任务增量学习中均优于现有方法。
- 零样本预测:在没有训练样本的情况下,模型也能进行有效的预测。
- 存储效率:压缩方法减少了30倍的数据存储需求,同时对预测精度的影响很小。
论文还探讨了该方法在不同设置下的性能,包括任务增量、类别增量和数据增量学习,以及灵活的推理设置。实验结果表明,AnytimeCL方法在所有设置和阶段中均优于现有技术,特别是在早期阶段,当有限的数据用于类别或任务时,该方法显示出显著的性能提升
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 论文笔记:Anytime Continual Learning for Open Vocabulary Classification

发表评论 取消回复