1.K—近邻算法 的含义:
简单来说就是通过你的邻居的“类别”,来推测你的“类别”
定义:如果一个样本在特征空间中的k个最相似(即特征空间中最临近)的样本中大多数属于某一类别,则该样本也属于这个类别。
2.距离公式(欧式公式):
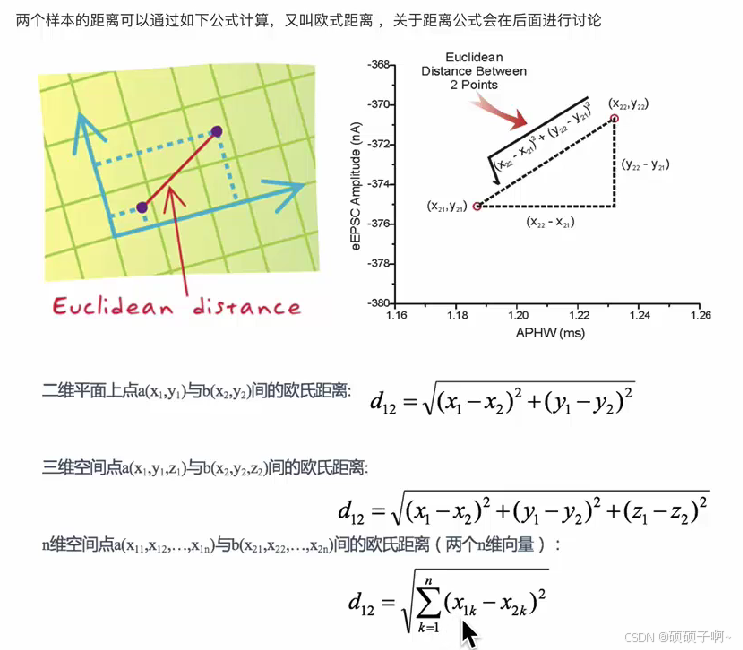
3.KNN算法的流程:
1>.计算已知类别数据集中的点 到 当前点 之间的距离
2>.按照距离递增的次序进行排序
3>.选取与当前最近的k个点
4>.统计k个点所在的类别 ,以及类别出现的频率
5>.返回4中频率出现最高的类别 作为当前点的预测分类
4.KNN算法API及简单代码
用到的库:scikit-learn
实例化分类器:
K=sklearn.neighbors.KNeighborsClassifier(n_neighbors=xx)
已知点:
X=【[1],[2],[3]...】 //注意这里是“二维”数组形式
对应的分类:
Y=【0,1,1...】 //对应的分类是“一维数组”形式
如何将X与Y对应起来:
K.fit(X,Y)
如何预测未知点
z=【[5],[6]...】:
K.predict(z)
5.代码:
import sklearn
from sklearn.neighbors import KNeighborsClassifier
#实例化“分类器”
K_NN=KNeighborsClassifier(n_neighbors=3)
#已知类别的点
x=[[1],[2],[3],[10],[20],[100]]
#对应的类别
y=[0,0,0,1,1,1]
#将点和类别一一对应
K_NN.fit(x,y)
#将要预测的点
z=[[1],[40]]
#预测
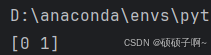
pre=K_NN.predict(z)
print(pre)结果:
6.K值大小说明:
k值过小,那么预测的点就会非常依赖相近的点,一旦相近的点出现错误或者选择的数据集不合适,那么就会产生错误预测,k值过小时往往近似误差比较小,因此他就可能会出现过拟合的现象。
k值过大,举一个夸张地例子来说,如果已知数据集的样本有n个,k=n,那么输出的结果很大程度上取决于已知数据集的类别,比如说一个班一共30个人,有2个女生,28个男生,新来一名同学(实际是女),k=30,那么预测值就会是男。所以,k值过大,容易发生欠拟合现象。
一般我们会取较小的数作为k值,使用交叉验证法找到最合适的k,具体步骤见后篇。
新名词:
近似误差:
主要注重的是训练集的误差,近似误差越小,不能说明模型越好,只能说是在训练集上表现良好,所以近似误差特别小时,很可能出现过拟合现象,并且此时的模型也不是最佳的。
估计误差:
主要关注的是训练集的误差,估计误差越小,说明预测能力越好,模型也接近最佳
因此我们一般看的是估计误差。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » yjs机器学习常见算法01——KNN(1)(K—近邻算法)

发表评论 取消回复