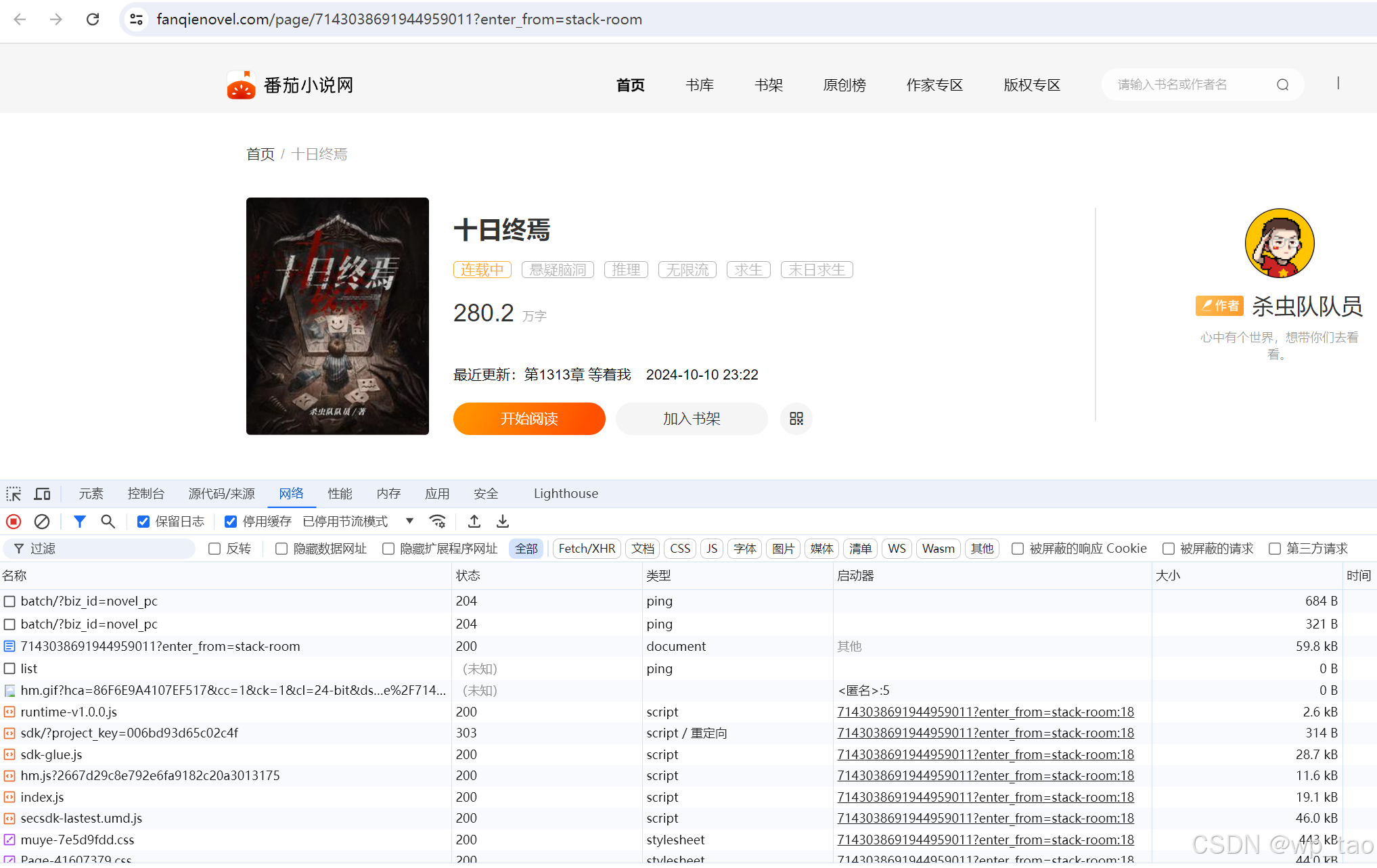
进入小说页面,打开开发者工具,刷新页面: 找到数据接口,为网页文件。
数据提取使用的是python的第三方库parsel。
import random import time import requests import parsel # 2. 番茄小说中的乱码字典,用于解码网页中的特定编码字符 dict_data = { '58670'
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » python爬虫--采集番茄小说网小说
微信公众账号
微信扫一扫加关注

发表评论 取消回复