目录
普通修改
使用loc或iloc修改
- loc:通过标签(列名)选择行或者列修改
- iloc:通过整数位置(索引下标)选择行和列进行修改
1)准备数据
import pandas as pd
data = {'Name': ['Alice', 'Bob', 'Charlie'],'Age': [25, 30, 35]}
df = pd.DataFrame(data)
df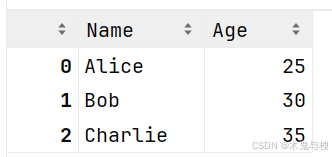
2)使用loc修改
# 修改第一行第二列的值
df.loc[0,'Age'] = 28
df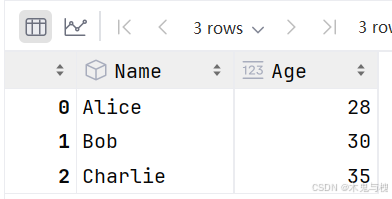
3)使用iloc修改
# 使用iloc用整数修改
df.iloc[1,1] = 25
df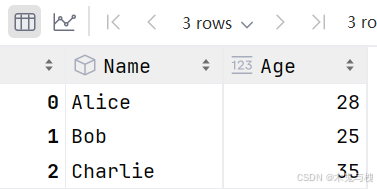
修改整列的值
# 将 Age 列的值都改为 30
df['Age'] = 30
df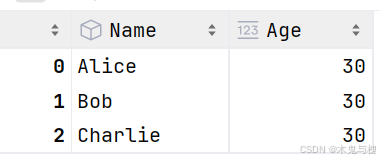
# 也可以使用条件赋值来修改部分值
# df['Name']=='Bob'
df.loc[df['Name']=='Bob', 'Age'] = 66
df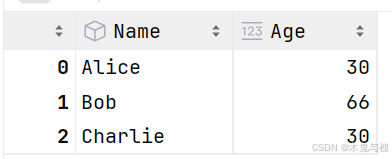
使用replace修改特定值
可以使用replace方法替换特定的值。
-
to_replace: 需要替换的数据
-
value: 替换后的数据
-
inplace: True或False, 是否在原数据上替换, 默认False
# 将 Name 列中的 Alice 替换为 Alice_new 方式一
df['Name'].replace(to_replace='Alice', value='Alice_new', inplace=True)
df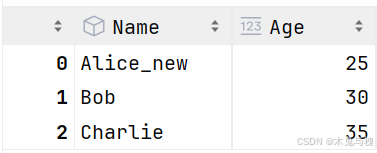
使用where和mask修改数据
-
where:保持满足条件的值不变,不满足条件的值进行修改。 -
mask:与where相反,保持不满足条件的值不变,满足条件的值进行修改。
1) 通过where将 Age 列中小于 30 的值改为 29
# 将 Age 列中小于 30 的值改为 29
df['Age'].where(df['Age']>=30, 29, inplace=True)
df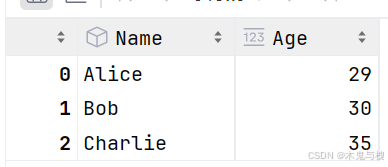
2) 通过mask将Age 列中大于等于 30 的值改为 66
# 将 Age 列中大于等于 30 的值改为 66
df['Age'].mask(df['Age']>=30, 66, inplace=True)
df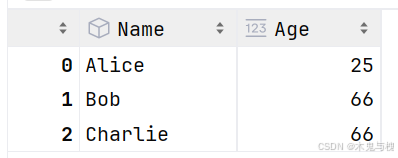
案列
准备数据
import pandas as pd
# 加载数据集 ../data/b_LJdata.csv
df = pd.read_csv('../data/b_LJdata.csv')
df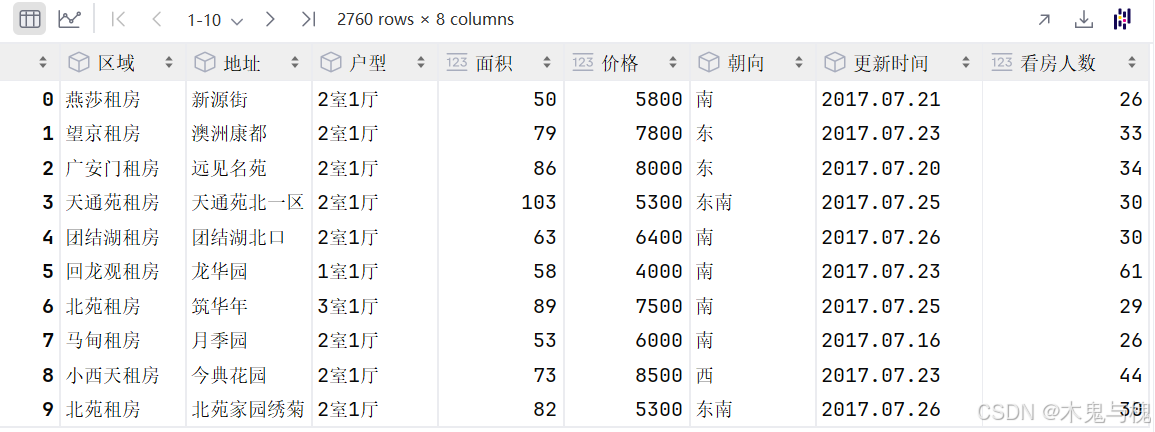
1) 将第一行的价格 设置成 8000
# 将第一行的价格 设置成 8000
copy_df = df.head().copy()
print('============修改前===================')
print(copy_df)
# copy_df.loc[0, '价格'] = 8000
# copy_df.iloc[0, 4] = 8000
price_index = df.columns.get_loc('价格')
copy_df.iloc[0, price_index] = 8000
print('价格下标: ', price_index) # 4
print('============修改后===================')
print(copy_df)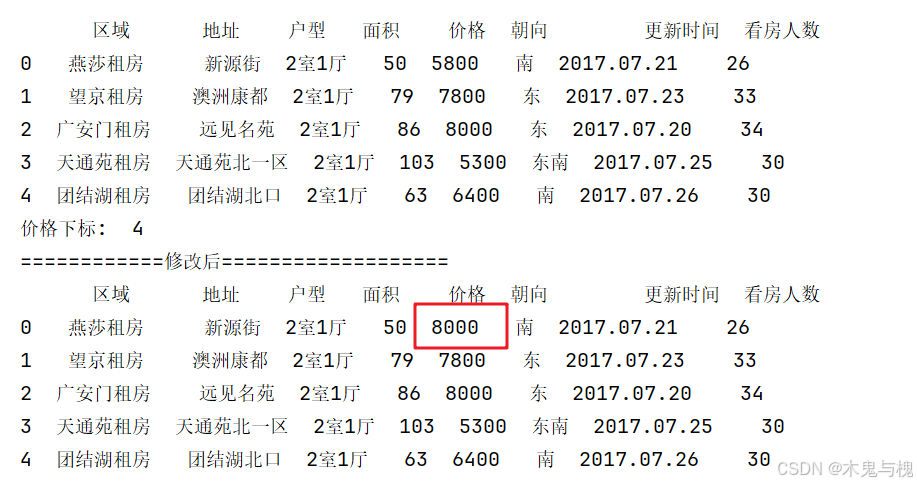
2) 将价格列 设置成 1000, 2000, 3000, 4000, 5000
# 将价格列 设置成 1000, 2000, 3000, 4000, 5000
copy_df = df.head().copy()
print('============修改前===================')
print(copy_df)
copy_df['价格'] = [1000, 2000, 3000, 4000, 5000]
print('============修改后===================')
print(copy_df)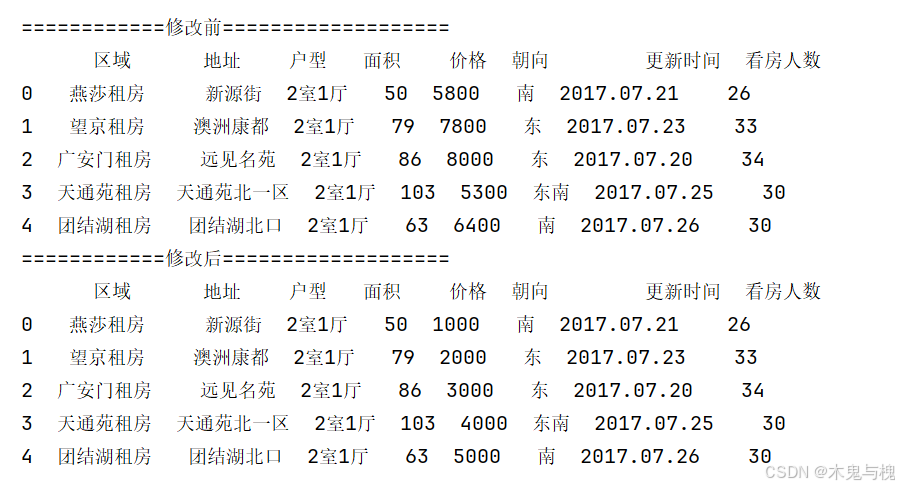
3) 将 价格 由 8000 替换成 6666
# 将 价格 由 8000 替换成 6666
copy_df = df.head().copy()
print('============修改前===================')
print(copy_df)
# 方式一
# copy_df['价格'].replace(to_replace=8000, value=6666, inplace=True)
# 方式二
copy_df['价格'] = copy_df['价格'].replace(to_replace=8000, value=6666)
# 类似与: copy_df['价格'] = [1000, 2000, 3000, 4000, 5000]
print('============修改后===================')
print(copy_df)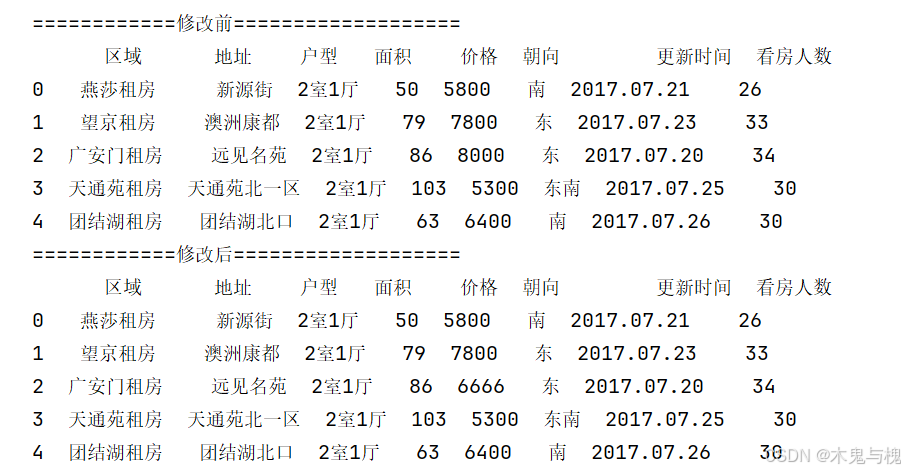
4) 将 朝向 由 东 替换成 南北
# 将 朝向 由 东 替换成 南北
copy_df = df.head().copy()
print('============修改前===================')
print(copy_df)
# 方式一
# copy_df['朝向'].replace(to_replace='东', value='南北', inplace=True)
# 方式二
copy_df['朝向'] = copy_df['朝向'].replace(to_replace='东', value='东北')
# 类似与: copy_df['价格'] = [1000, 2000, 3000, 4000, 5000]
print('============修改后===================')
print(copy_df)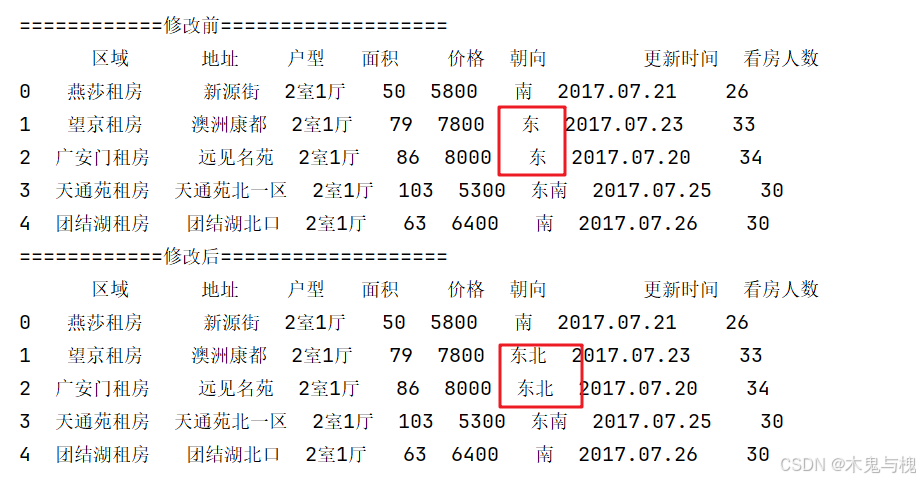
5) 将 户型 由 2室1厅 替换成 3室2厅
# 将 户型 由 2室1厅 替换成 3室2厅
copy_df = df.head().copy()
print('============修改前===================')
print(copy_df)
# 方式一
# copy_df['户型'].replace(to_replace='2室1厅', value='3室2厅 ', inplace=True)
# 方式二
copy_df['户型'] = copy_df['户型'].replace(to_replace='2室1厅', value='5室3厅 ')
# 类似与: copy_df['价格'] = [1000, 2000, 3000, 4000, 5000]
print('============修改后===================')
print(copy_df)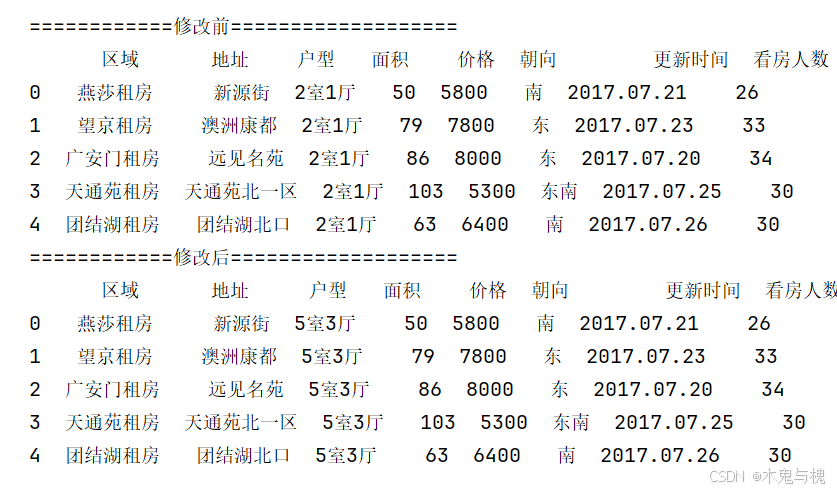
自定义函数Series.apply()
在pandas中,Series.apply(func)是一种非常有用的方法,用于对Series中的每个元素应用一个函数。
普通自定义
1) 普通定义
import pandas as pd
df = pd.DataFrame({'Age': [20, 25, 30, 35, 40]})
# 将age列加3
def add_three(x):
print('当前元素 --> ' ,x)
return x + 3
df['Age'] = df['Age'].apply(add_three)
print(df)
2)使用lambda
import pandas as pd
df = pd.DataFrame({'Age': [20, 25, 30, 35, 40]})
df['Age'] = df['Age'].apply(lambda x : x + 3)
print(df)传递参数给函数
1)通过传参,一个是Series中的元素值x,另一个是通过apply方法传入的参数n。
def add_2(x,num):
print(f"x={x},num={num}")
return x + num
df['Age'] = df['Age'].apply(add_2,args = (3,))
print(df)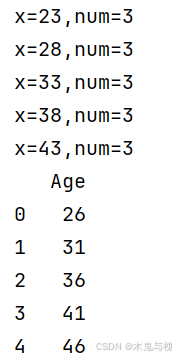
2)使用lambda
df['Age'] = df['Age'].apply(lambda x,num :x + num ,args = (3,))
print(df)apply方法与pandas方法结合
1) 输出偶数
import pandas as pd
df = pd.DataFrame({'Values': [15, 20, 33, 40, 50]})
def is_even(x):
return x % 2 == 0
even_mask = df['Values'].apply(is_even)
even_values = df[even_mask]['Values']
print(even_values)
2) lambda
# 目标:输出 偶数
import pandas as pd
df = pd.DataFrame({'vals': [15, 20, 33, 40, 50]})
returns = df['vals'].apply(lambda x : x % 2 == 0)
print(df[returns]['vals'])案列
准备数据
import pandas as pd
# 加载数据
df = pd.read_csv('../data/b_LJdata.csv')
copy_df = df.head().copy()
copy_df
1) 如果区域 是 天通苑租房 就改成 昌平区, 否则 保持不变(自定义函数)
# 1 如果区域 是 天通苑租房 就改成 昌平区, 否则 保持不变(自定义函数)
copy_df = df.head().copy()
def change_area(x):
if x == '天通苑租房':
return '昌平区'
else:
return x
copy_df['区域'] = copy_df['区域'].apply(change_area)
print(copy_df)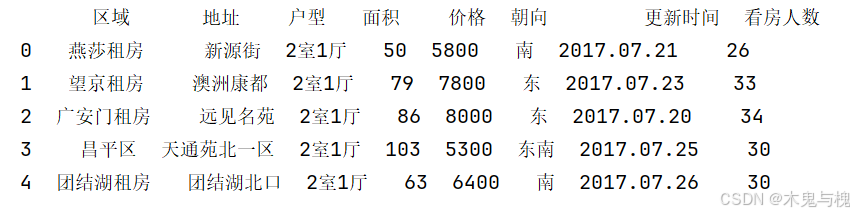
2) 如果区域 是 望京租房 就改成 朝阳区, 否则 保持不变(lambda表达式)
# 2 如果区域 是 望京租房 就改成 朝阳区, 否则 保持不变(lambda表达式)
copy_df = df.head().copy()
copy_df['区域'] = copy_df['区域'].apply(lambda x : '朝阳区' if x == '望京租房' else x)
print(copy_df)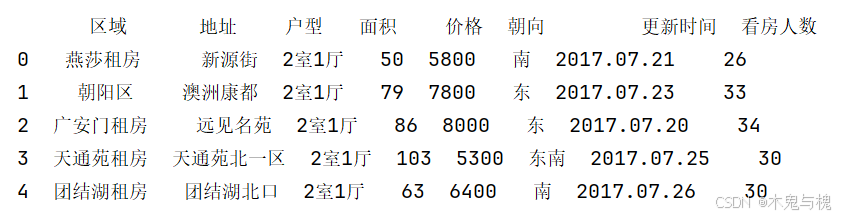
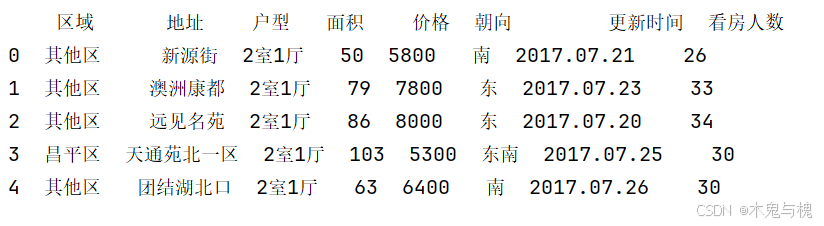
3) 如果区域是 天通苑租房 就设置成 昌平区, 否则 设置成 其他区(带参数版本 函数实现)
# 3 如果区域是 天通苑租房 就设置成 昌平区, 否则 设置成 其他区(带参数版本 函数实现)
copy_df = df.head().copy()
def change_area(x,arg1,arg2):
if x == '天通苑租房':
return arg1
else:
return arg2
copy_df['区域'] = copy_df['区域'].apply(change_area,args = ('昌平区','其他区'))
print(copy_df)
4) 4 如果区域是 天通苑租房 就设置成 昌平区, 否则 设置成 其他区(带参数版本 lambda表达式实现)
# 4 如果区域是 天通苑租房 就设置成 昌平区, 否则 设置成 其他区(带参数版本 lambda表达式实现)
copy_df = df.head().copy()
copy_df['区域'] = copy_df['区域'].apply(lambda x,arg1,arg2 : arg1 if x == '天通苑租房' else arg2 ,args = ('昌平区','其他区'))
print(copy_df)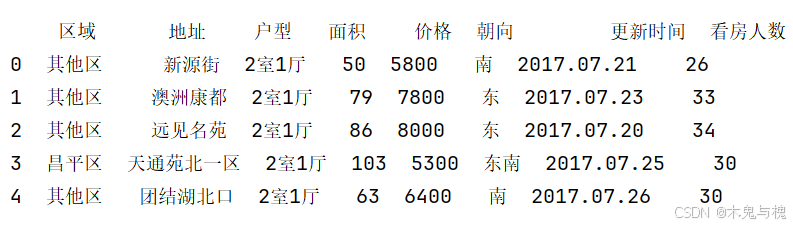
自定义函数 DataFrame.apply()
在 pandas 中,DataFrame.apply(func, axis=0/1) 方法用于沿指定轴应用函数。
axis =1 ,按行计算
1) 普通定义
import pandas as pd
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
print(df)
# 得到 A+ B
def func(objects):
result = objects['A'] + objects['B']
return result
# return objects['A'] + objects['B']
# axis=1 按行处理
df.apply(func, axis=1)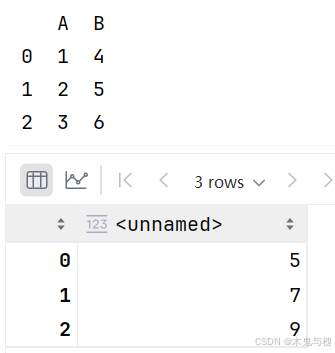
2) 使用lambda
# 2.使用lamdba处理
import pandas as pd
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
new_df = df.apply(lambda objects:objects['A'] + objects['B'] , axis=1)
new_df3) 在最后新建一列
# 3.在最后新建一列
import pandas as pd
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
def func(objects):
objects['C'] = objects['A'] + objects['B']
return objects
df.apply(func, axis=1)
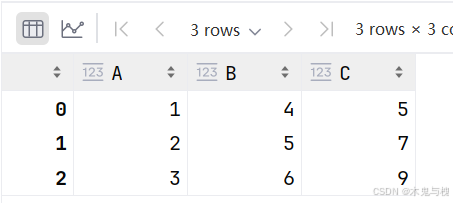
axis = 0 , 按列计算
1) 普通定义
import pandas as pd
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
print(df)
print("=====================")
def process_column(col):
return col.sum()
result = df.apply(process_column, axis=0)
print(result)
2) 使用lambda
import pandas as pd
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
print(df)
print("=====================")
result = df.apply(lambda col : col.sum(), axis=0)
print(result)案例
1) 行处理
import pandas as pd
# 加载数据
df = pd.read_csv('../data/b_LJdata.csv')
copy_df = df.head().copy()
print(copy_df)
print("===============================")
# 目标1:将 天通苑租房 提高 2000
def price_func(objects):
if objects['区域'] == '天通苑租房':
objects['价格'] += 2000
return objects
copy_df = copy_df.apply(price_func, axis=1)
print(copy_df)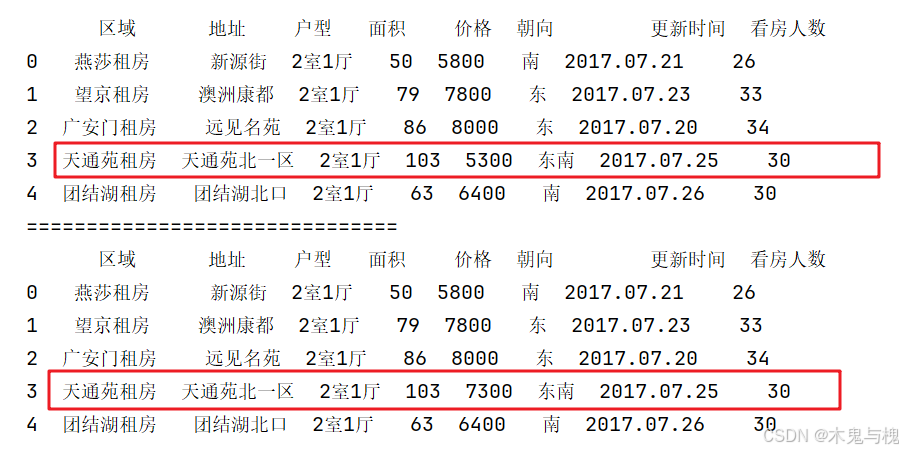
2) 列处理
import pandas as pd
# 加载数据
df = pd.read_csv('../data/b_LJdata.csv')
copy_df = df.head().copy()
print(copy_df)
# 目标2:将所有的房租 涨1000 块
def change_price(objects):
if objects._name == '价格':
objects += 1000
return objects
copy_df.apply(change_price, axis=0)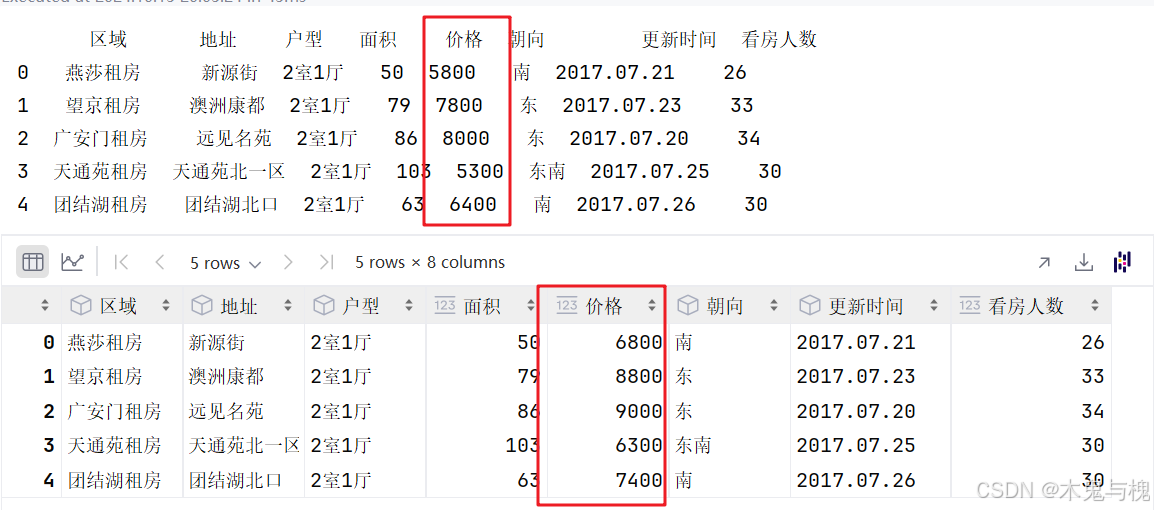
自定义函数 DataFrame.applymap()
-
applymap:对整个DataFrame的每个元素应用函数进行修改。
1) 准备数据
import pandas as pd
# 创建一个示例数据框
data = {'Col1': [10, 20, 30],
'Col2': [40, 50, 60],
'Col3': [70, 80, 90]}
df = pd.DataFrame(data)
df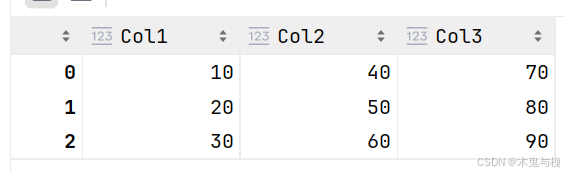
2) 给每个单元格元素乘以2倍
# 目标:每个元素 * 2
def fn(x):
return x * 2
df = df.applymap(fn)
print(df)
# 使用lambda
df = df.applymap(lambda x : x*2)
df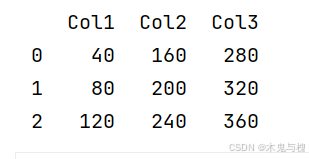
案例
准备数据
import pandas as pd
# 加载数据
df = pd.read_csv('../data/b_LJdata.csv')
copy_df = df.head().copy()
print(copy_df)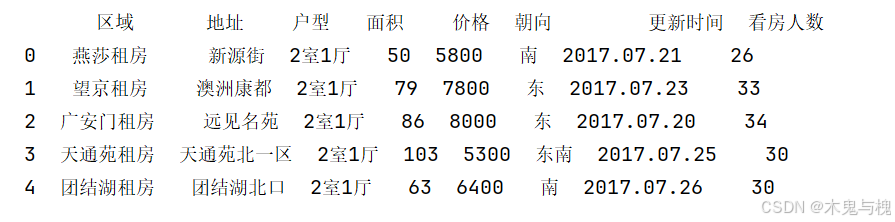
1) 只要值是 '2室1厅' 就改成 '3室2厅'(函数版)
#%%
# 目标: 只要值是 '2室1厅' 就改成 '3室2厅'(函数版)
def fn(x):
if x == '2室1厅':
return '3室2厅'
else:
return x
copy_df = copy_df.applymap(fn)
print(copy_df)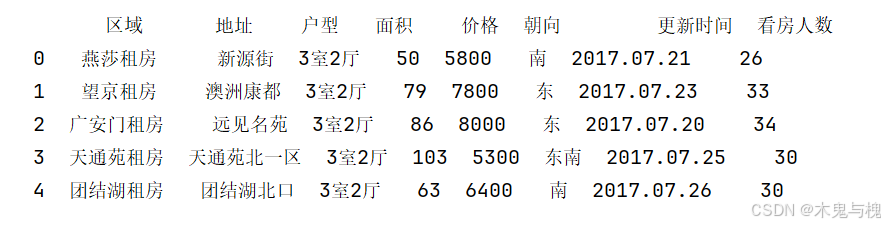
2) 使用lambda
# 使用lambda
copy_df = copy_df.applymap(lambda x :'3室2厅' if x == '2室1厅' else x)
print(copy_df)
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Series或DataFrame数据修改

发表评论 取消回复