数据结构:图
图
在生活中,常会遇到多个节点间的复杂关系,比如说一个学生的常见活动区域:
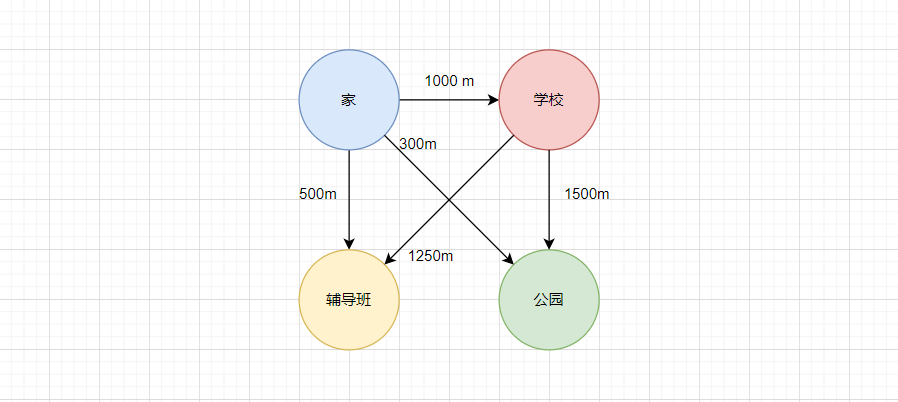
如果想要在计算机中保存这样结构,并不是顺序结构或者树形结构可以解决的,树中一个节点只有唯一的一个父亲,而此处一个节点可以有多个父亲。而且两个节点之间,还要考虑额外的路径长度问题,这是树难以做到的。
因此计算机需要一个既可以表示节点间的复杂关系,又可以表示节点之间路径的权值的结构,这就是图 Graph。
接下来讲解些图的相关术语,图是由顶点 vertex以及边 edge构成的一种数据结构,表示为
G
=
(
V
,
E
)
G = (V, E)
G=(V,E),其中V是多个顶点的集合,E是多条边的集合。
想要表示一条边,有两种表示方式:
(x, y):表示x到y的一条双向路径,即(x, y)是没有方向的,(x, y) = (y, x)path(x, y):表示x到y的一条单向路径,即path(x, y)是有方向的,path(x, y) != path(y, x)
- 有向图与无向图
如果一个图内部的边是有方向的,称为有向图,如果是没有方向的,则称为无向图。
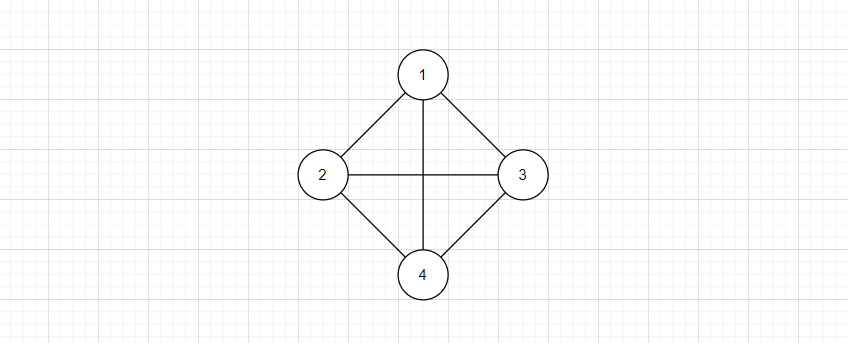
- 度
如果对于一个有n个顶点的无向图,有n * (n - 1) / 2条边,也就是任意两个顶点都有一个边,则称为无向完全图,如下图:
如果对于一个有n个顶点的有向图,有n * (n - 1)条边,也就是任意两个顶点都有两条边,则称为有向完全图,如下图:
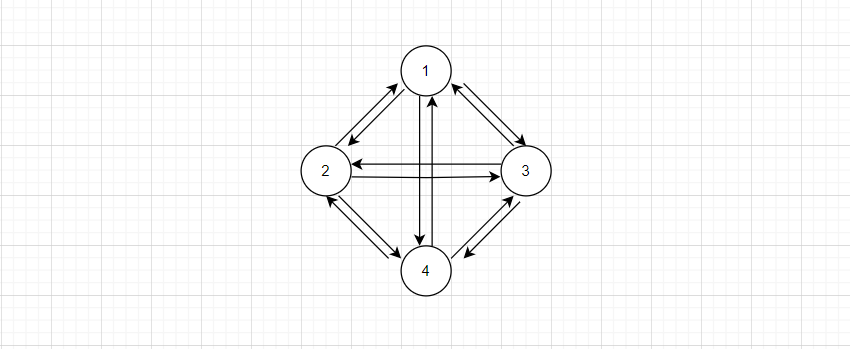
一个顶点的所有关联的边的总数,称为顶点的度,记作 deg(v)。对于无向图,一个顶点有多少条边,度就是多少。对于有向图,度分为出度 outdeg和入度 indeg,比如对于上图的4节点,其包含三条出度和三条入度。对于有向图来说,度为出度和入度的总和deg(v) = indeg(v) + outdeg(v),上图4节点的度为3 + 3 = 6。
- 路径
当从一个顶点vi出发,可以通过边到达另一个顶点vj,则这个过程中的所有顶点构成vi到vj的路径。
- 路径长度
对于带有权值的图,路径长度为所有边的权值总和,对于没有权值的图,路径长度为路径上边的个数。
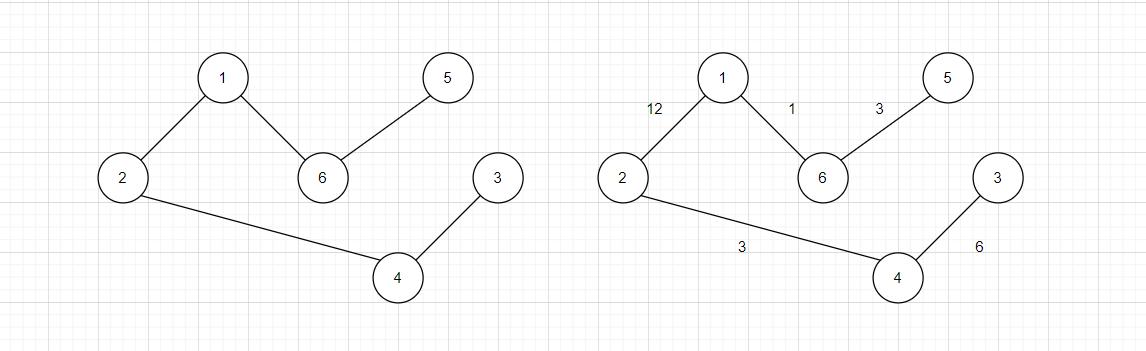
左侧的图3 - 5的路径长度为5,右侧的图3 - 5的路径长度为25。
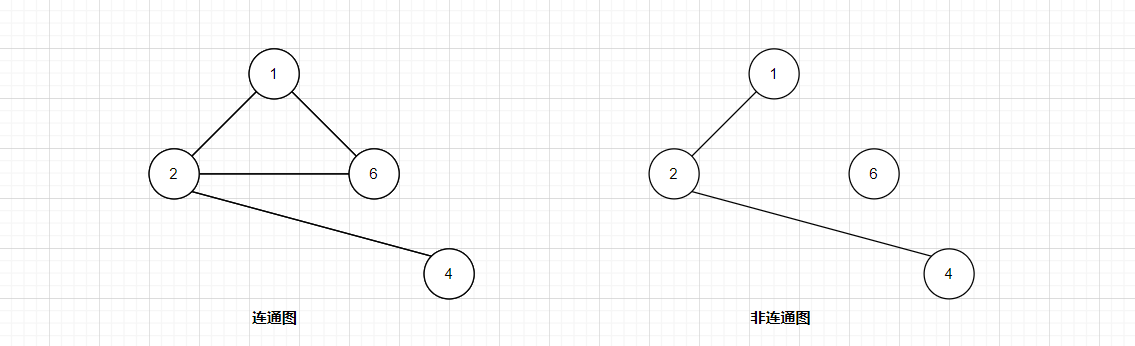
- 连通图
如果在图中,从顶点vi到vj是有路径的,称为两个顶点是连通的。
如果无向图中所有的顶点都是连通的,那么该图为连通图。
- 强连通图
如果在有向图中,所有顶点都是连通的,对于任意一对vi和vj,即存在path(vi, vj),也存在path(vj, vi),那么称该图为强连通图。
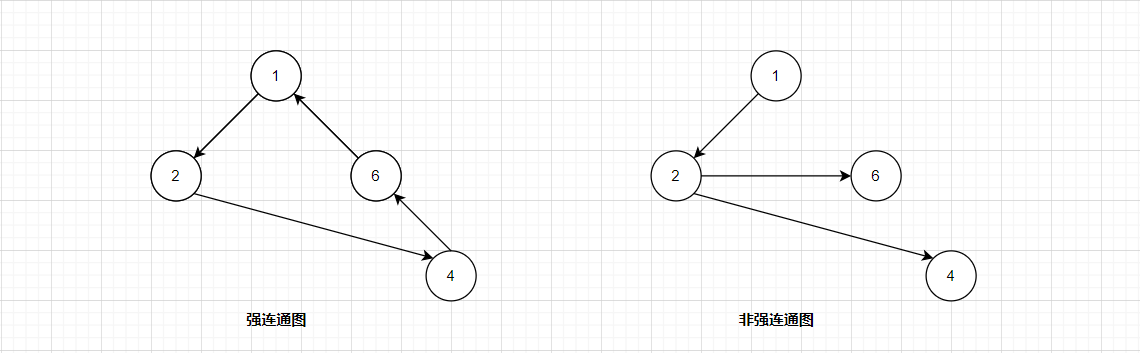
对于左侧的强连通图,由于构成一个环状结构,从1 - 4的唯一路径为1 2 4,从4 - 1的唯一路径为4 6 1,其它的同理,任何两个顶点都可以找到路径。
- 子图
如果一个图的所有顶点和边,都是另一个图的子集,称为该图为另一张图的子图。
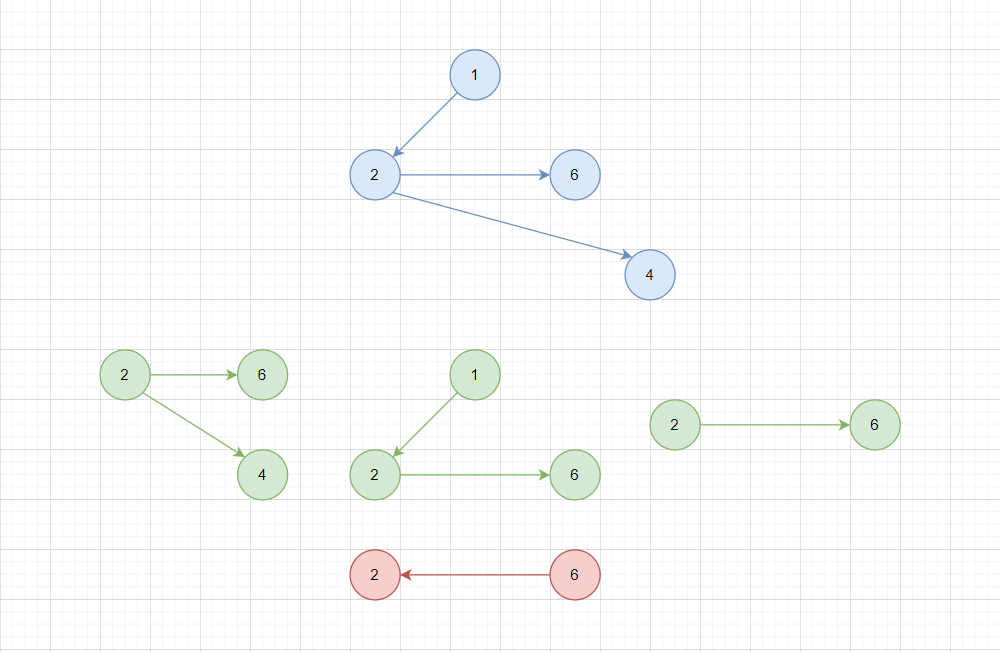
如图,所有绿色图都是蓝色图的子图,但是红色图不是蓝色图的子图,因为边6->2不在蓝色图中,蓝色图中只有2->6。
- 生成树
包含一个无向连通图所有节点的树,称为该图的生成树,对于一个n个节点的无向连通图,其生成树的边数为n - 1。
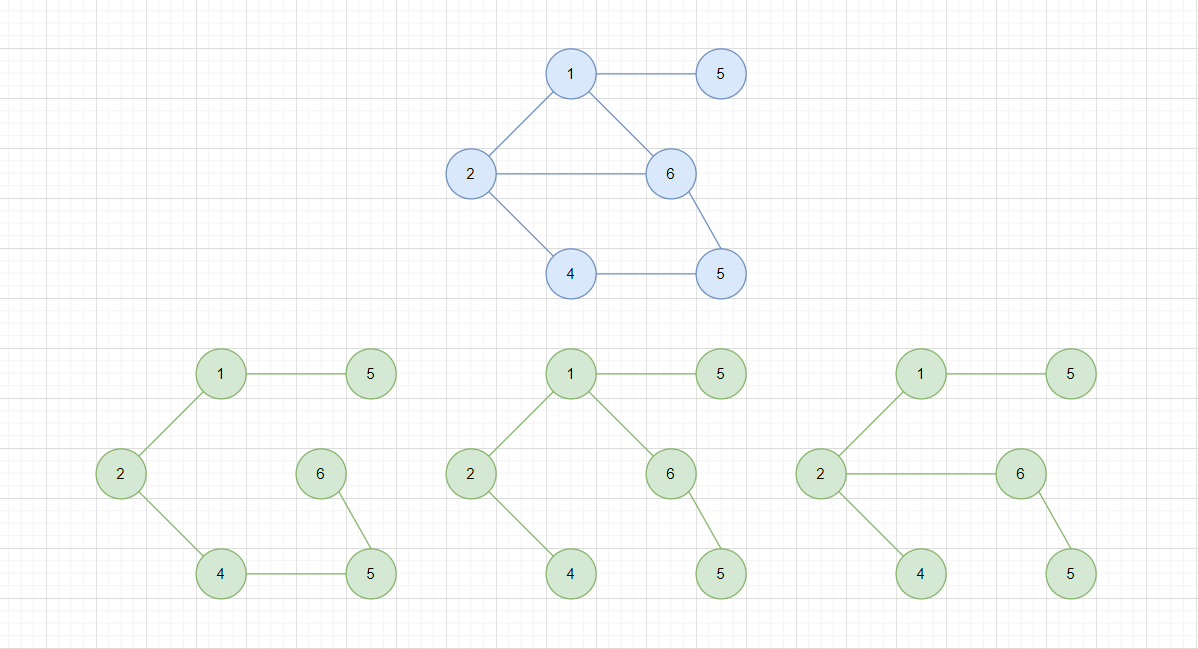
此处的三个绿色的树,都是蓝色图的生成树,它们任意一个节点都最多只有一个父节点,符合树的定义。另外的,树是一种特殊的图,所以生成树也是图。
- 最小生成树
对于一个带有权值的无向连通图,所有生成树中,权值总和最小的树,称为最小生成树。
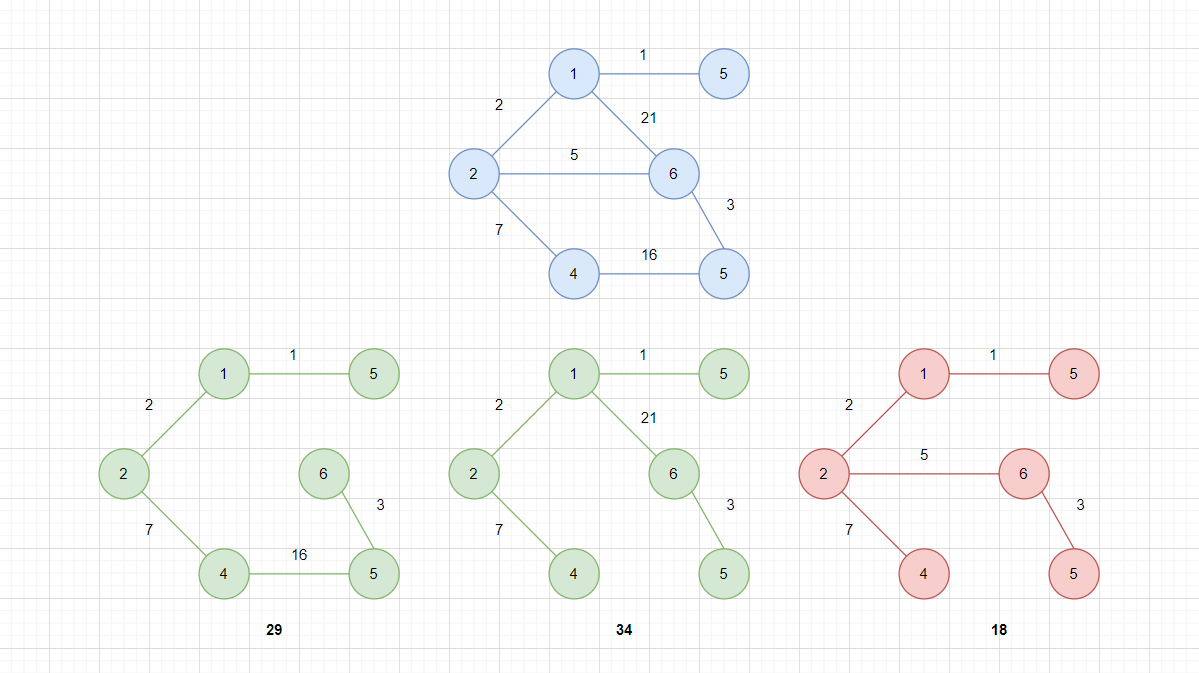
如图,只有红色的树是蓝色图的最小生成树,因为它的权值总和最小。一个图可能有多个最小生成树,不过这张蓝色的图确实只有红色这一个最小生成树。
讲完这些基本概念,接下来开始使用C++实现图Graph,图主要围绕三个问题展开:
- 图中有哪些节点,也就是如何遍历图
- 求两个节点之间的最短路径
- 求图的最小生成树
存储结构
想要存储一个图,那么就要存储图的顶点和边,想要存储顶点很简单,比如数组,集合等等。那么要如何存储边?
先来看看边有哪些属性:
- 起始顶点
- 目的顶点
- 权值
根据图是否有向,是否加权,上述属性会有所改动。
邻接矩阵
第一种存储方式是使用一个矩阵,也就是二维数组,利用数组下标作为起始顶点与目的顶点,用数组的元素值来表示路径的权值,这种方式称为邻接矩阵。
如下图:
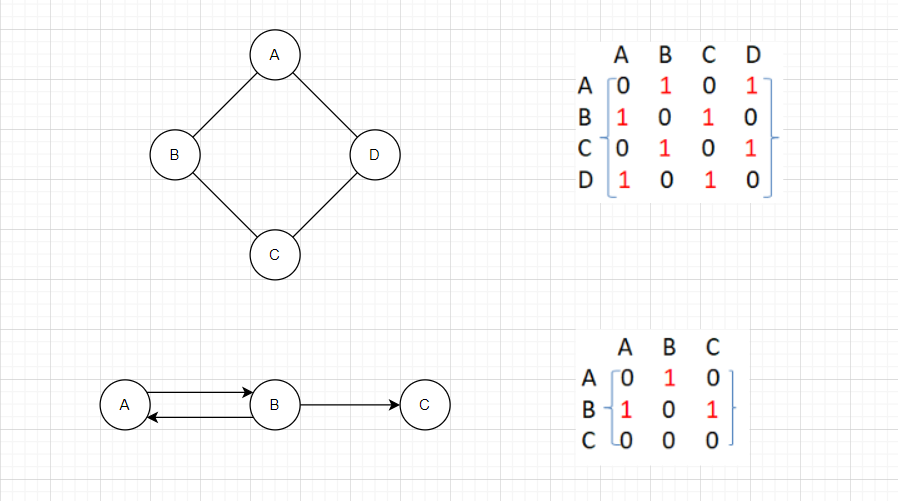
第一张图是不带权无向图,arr[A][B] = 1以及arr[B][A] = 1表示边A-B是存在的。对于无向图,其邻接矩阵是对称的。
第二张图是不带权的有向图,arr[B][C] = 1表示边B->C是存在的,而arr[C][B] = 0表示边C->B是不存在的。
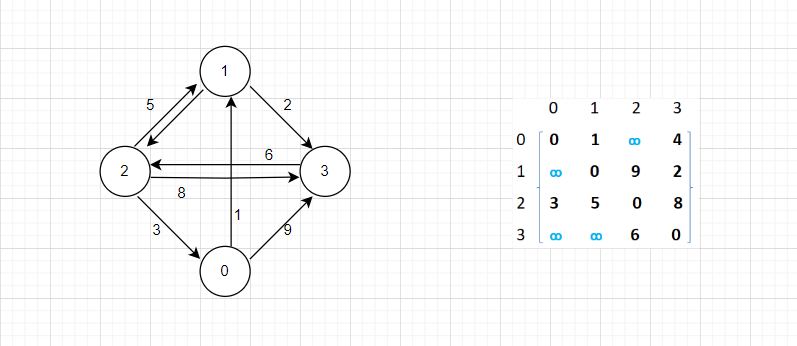
如果表示的是一个带权图,此时矩阵内部要存储的就是权值了,比如arr[2][1] = 5表示边2->1存在,并且权值为5。而arr[3][0]是无穷,表示3->0是不存在的边。
邻接矩阵的表示方法,适合稠密图,也就是边数目比较多的图。因为不论一张图有多少个边,存储这些边消耗的空间是一样大的。当要查找两个点之间的关系,可以通过下标直接查找矩阵的值,也就是以O(1)的时间复杂度进行查找两点关系。
但是如果要查找一个顶点i有哪些相连的边,此时就要遍历数组arr[i],由于起点确定,所以时间复杂度为O(N)。
邻接表
另一种方式是使用邻接表来表示边的关系,把边的信息放在一个结构体内存储起来,随后每个顶点都维护一个链表,链表的每个节点表示一个边。
如图所示:
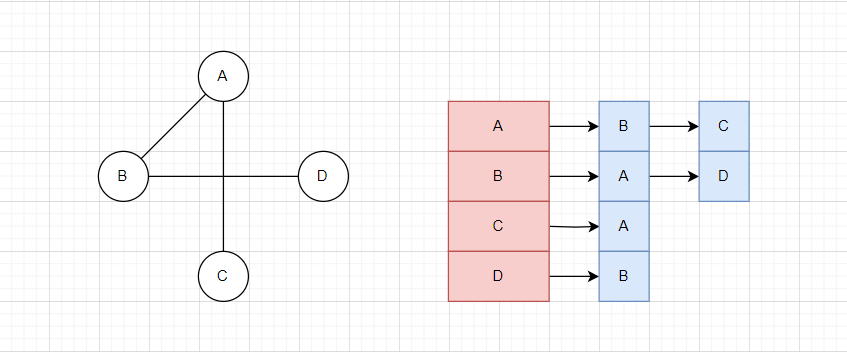
此处区分红色与蓝色节点的区别,红色节点表示起始顶点,而蓝色节点表示终止顶点。
比如第一个A开头的链表,其含义为,存在边:A->B,A->C,也就是说整个链表的头节点表示起始顶点,而后续的顶点表示终止顶点。
如果要存储边的权值,那么直接放在蓝色节点内部即可。
对于有向图,邻接表又分为入边表和出边表:
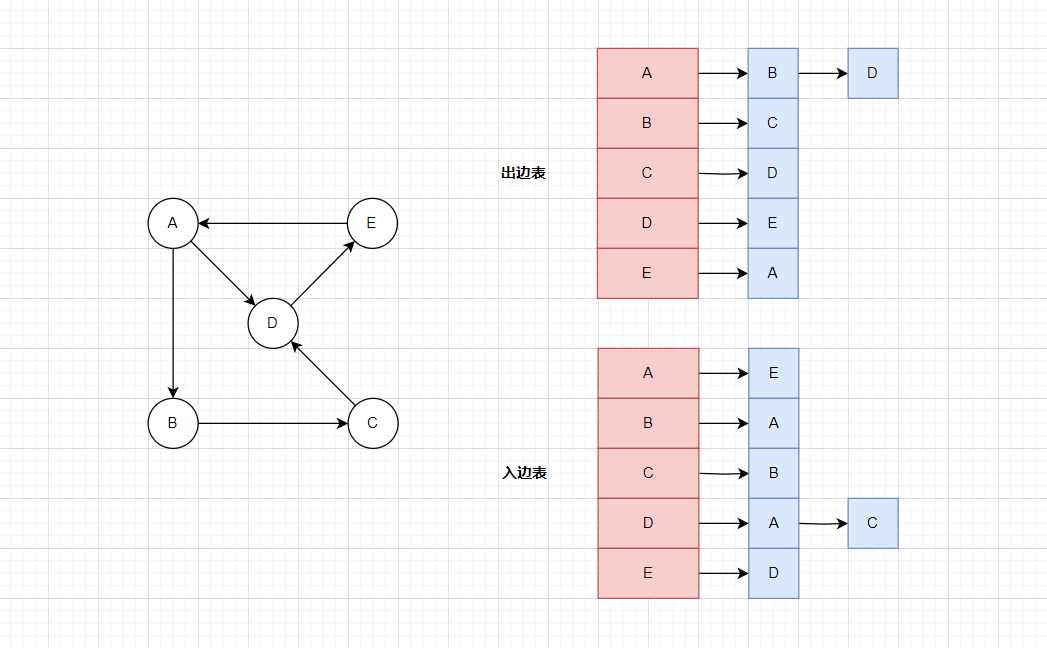
原理和刚才是一样的,对于出边表,头节点是起始节点,其余节点是目的节点。对于入边表,头节点是目的节点,其余节点是起始节点。
大部分情况下,就算是有向图也只需要存储一个出边表,如果要快速查询别的节点是否与自己连通,才会额外存储一个入边表。
对于无向图来说,出边表和入边表是完全一样的,所以不会区分这两个概念,都叫做邻接表。
对于邻接表形式的存储,适合稀疏图,也就是边比较少的图,每多一条边就多存储一个节点,只要边比较少,消耗的空间就少。
另外的,邻接表可以很快的查询到一个顶点与哪些顶点连通,只需要遍历对应的链表即可,每一个被遍历的数据都是有效的。而临界矩阵中,会遍历很多不连通的节点。
但是邻接表也有缺点,如果节点多起来,那么邻接表的空间消耗就会大幅增加。另外的,邻接表不适合查询确定的两个顶点是否连通,比如对于v1和v2,邻接矩阵只需要查看arr[v1][v2]即可,时间复杂度O(1)。而邻接表要去v1的链表中,遍历整个链表查看也没有v2,如果数据量大,时间复杂度会退化至O(N)。
可见,邻接表与邻接矩阵是各有优劣的,根据业务需求选择合适的存储结构。
本博客接下来讲解以C++实现的邻接矩阵的图。
Graph 类架构
类定义如下:
template <typename V, typename W = int, W MAX_W = INT_MAX, bool direction = false>
class Graph
{
using self = Graph<V, W, MAX_W, direction>;
private:
vector<V> _vertexs; // 节点
map<V, int> _indexMap; // 节点->下标 映射
vector<vector<W>> _matrix; // 邻接矩阵
};
模板参数:
V:存储的元素类型W:权值的类型,默认为intMAX_W:表示不连通的值,也就是无穷direction:是否有向,默认false表示无向图
回看之前的一些示例图片,你会发现图的节点可以存储字符ABCD,也可以存储整数1234等等信息。所以此处将其做成一个泛型,利用V表示存储元素的类型。
而不同需求下,用户需要表示的边的权值也不同,比如用int的大小表示边的权值,也可以是一个结构体进行多维度的权值判断。此处也把权值定义为模板参数W,供用户自己定义。
因为传入的W类型不确定,W作为权值,其实就是邻接矩阵内部的元素。如果两个顶点不连通,那么就要用无穷来表示,对于int来说,可以用INT_MAX这个宏,但是如果是一些其它的类型,无穷就不好定义了,所以这里也支持让用户自定义无穷的值。
最后一个模板参数表示是否有向,根据是否有向,内部的函数逻辑也要调整,后面会说明。
using self = Graph<V, W, MAX_W, direction>;
由于模板参数太多,类的类型就比较冗长,所以在类内部重定义了一个新的类型self来表示图,方便后续使用。
vector<V> _vertexs; // 节点
unordered_map<V, int> _indexMap; // 节点->下标 映射
vector<vector<W>> _matrix; // 邻接矩阵
类成员:
_vertexs:用数组存储所有顶点的值_indexMap:为了可以通过顶点值快速找到下标,建立一个map进行映射_matrix:临界矩阵本体,表示图的边,本质是一个二维数组
先前提及过,邻接矩阵中,用arr[A][B]来表示A-B是否连通,如下图:
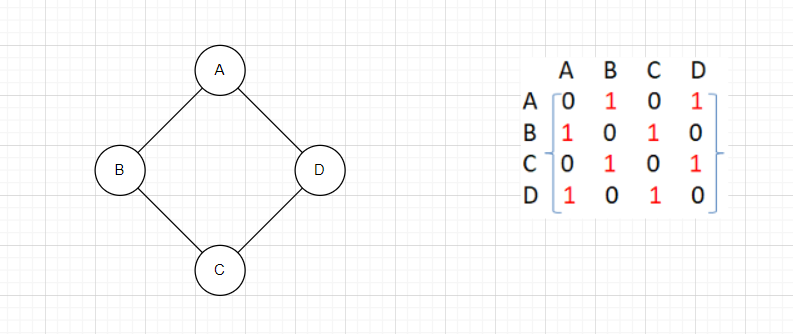
但是对于计算机,这不现实。因为计算机的二维数组,下标是整数,不可能用ABCD这样的字符做下标,更不要说此处是一个泛型V,它甚至可能是一个结构体。
因此要用具体的整数来表示一个个顶点,此处用一个std::vector来存储所有的元素,数组下标表示在邻接矩阵中的下标。
因为后面要频繁访问邻接矩阵,如果每次都去std::vector中遍历查找元素,进而找到该元素的下标,这样时间复杂度就非常高了。所以在用一个std::unordered_map维护顶点值->下标的映射关系,将查找下标的复杂度从O(N)降低至O(1)。
当然也可以使用std::map来减少空间消耗,这样查询下标的时间复杂度就是O(lgN),整体和O(1)差别不大。
基本接口
构造函数
由于图的结构比较复杂,此处的设计思路是:刚创建图时,用户传入所有的顶点,在构造时只能初始化顶点,如果要维护顶点之间的边关系,那要在构造好了对象之后,在构造时只初始化顶点。
- 基本构造:
Graph(const vector<V>& vertexs)
: _vertexs(vertexs)
{
int n = vertexs.size();
_matrix.resize(n);
for (int i = 0; i < n; i++)
{
_indexMap[vertexs[i]] = i; // 建立映射关系
_matrix[i].resize(n, MAX_W); // 初始化邻接矩阵
}
}
基本构造接收一个数组,这个数组存储所有的顶点值,: _vertexs(vertexs)直接在初始化列表中将用户传入的数据拷贝下来。
在函数体中,要处理的就是_indexMap的映射关系和_matrix邻接矩阵的初始化:
_indexMap[vertexs[i]] = i:表示_vertex第i个顶点的下标为i,建立映射。_matrix[i].resize(n, MAX_W):最开始图没有任何边,任意两个顶点都是不连通的,邻接矩阵的值为MAX_W表示无穷,不连通
- 指针数组版本
Graph(const V* vertex, int n)
{
_vertexs.reserve(n);
_matrix.resize(n);
for (int i = 0; i < n; ++i)
{
_vertexs.push_back(vertex[i]); // 初始化 _vertexs
_indexMap[vertex[i]] = i; // 建立映射关系
_matrix[i].resize(n, MAX_W); // 初始化邻接矩阵
}
}
如果用户传入的是C风格的数组,或者一个字符串风格的数组,此时std::vector就不好处理了,所以重载一个指针版本,参数const V*是指向数组的指针,n是数组元素个数。
- 默认构造
Graph() = default;
另外还需要一个空的默认构造,也就是创建一个没有任何顶点的空图,这在后面的最小生成树有用。
添加边
该接口用于给两个顶点添加一条边,代码如下:
int getVertexIndex(const V& v)
{
return _indexMap.count(v) ? _indexMap[v] : -1; // 返回顶点下标
}
void addEdge(const V& src, const V& dst, const W& weight)
{
int srcIndex = getVertexIndex(src); // 获取起始顶点下标
int dstIndex = getVertexIndex(dst); // 获取目的顶点下标
if (srcIndex == -1 || dstIndex == -1) // 有某个顶点不在图中
return;
_matrix[srcIndex][dstIndex] = weight; // 添加权重
if (!direction) // 无向图,需要再添加一个反向的边
_matrix[dstIndex][srcIndex] = weight;
}
此处写了一个getVertexIndex函数,用于快速获取顶点v对应的下标。
_indexMap.count(v) ? _indexMap[v] : -1:如果顶点存在返回下标,如果不存在返回-1
获取到起始顶点和目的顶点的下标后,就可以去邻接矩阵中添加边了:
_matrix[srcIndex][dstIndex] = weight:表示src->dst连通,权重为weight
如果这是一个无向图,那么最后还需要建立一个dst->src的边。
遍历
想要遍历图,和树一样分为深度优先DFS和广度优先BFS。
DFS
如图所示:
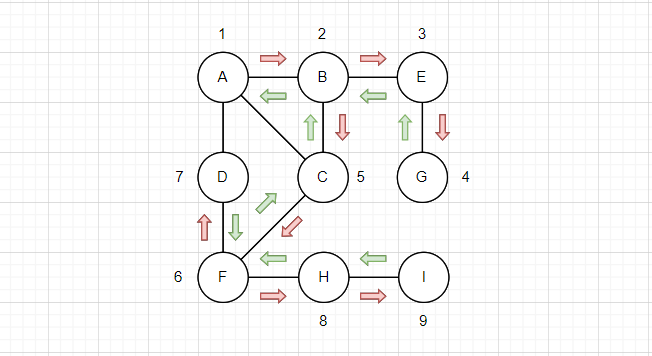
上图中,红色箭头是递归,绿色箭头是回溯。
深度优先遍历,就是优先将邻接顶点的所有其它邻接顶点都遍历完,再遍历下一个邻接顶点,其实和树是一样的。
比如对于F顶点,其有三个连通顶点,除去C比F先遍历,F首先遍历D连通的所有顶点,但是D连通的顶点都被遍历过了,所以没有继续深入。当绿色箭头返回到F,说明和D连通的所有顶点都被遍历完了,此时再去遍历H,H有一个连通的顶点I,所以先去遍历I,再回到F。
唯一不同的是,树有固定的根节点,每次都从根结点开始遍历,而图没有固定的根,用户传入任意一个顶点都可以开始遍历。
代码:
vector<V> DFS(const V& src)
{
vector<V> ret; // 返回值是一个数组
vector<bool> visited(_vertexs.size(), false); // 防止重复遍历
int srci = getVertexIndex(src);
if (srci == -1) // 确保src顶点存在
return ret;
_DFS(srci, ret, visited); // 深度优先遍历
return ret;
}
void _DFS(int srci, vector<V>& path, vector<bool>& visited)
{
visited[srci] = true; // 把当前节点src标记为已遍历
path.push_back(_vertexs[srci]); // 将当前节点尾插到返回值数组
for (int i = 0; i < _vertexs.size(); i++) // 循环遍历所有连通的顶点
{
if (!visited[i] && _matrix[srci][i] != MAX_W)
_DFS(i, path, visited);
}
}
DFS接口接收一个src,从该顶点开始遍历,将遍历结果按顺序放在数组ret中进行返回。
在递归本体_DFS中,每递归一个节点,将当前节点visited[srci] = true,表示已经遍历过,防止重复遍历。
!visited[i] && _matrix[srci][i] != MAX_W:只要下标i对应的顶点没有遍历过,并且和当前的srci是连通的,就进行递归遍历。
要注意的是,遍历不一定返回所有顶点,只有连通图可以通过一个顶点遍历所有的顶点。
BFS
如图所示:
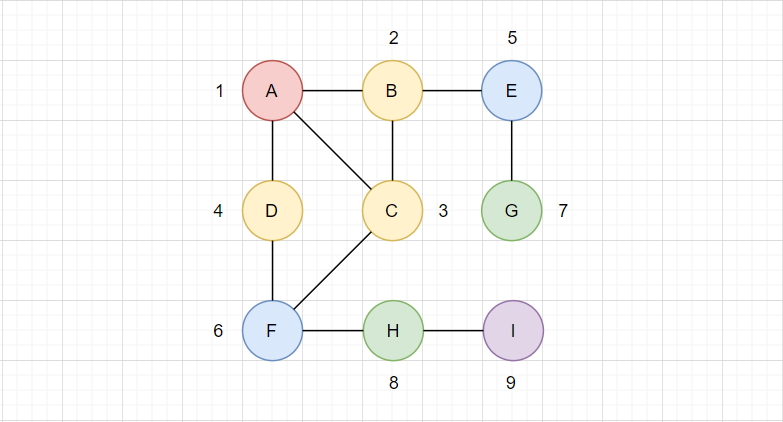
层序遍历也很好理解,以A为起点,图中相同颜色的顶点算作同一层,输出完上一层再输出下一层。
代码如下:
vector<V> BFS(const V& src)
{
vector<V> ret;
vector<bool> visited(_vertexs.size(), false); // 防止重复遍历
queue<int> q; // 队列,记录遍历顺序
int srci = getVertexIndex(src);
q.push(srci); // 先把源顶点src的下标入队列
visited[srci] = true; // 标识源顶点已经遍历
while (!q.empty())
{
int front = q.front(); // 拿到当前要遍历的节点
q.pop();
for (int i = 0; i < _vertexs.size(); i++)
{
if (!visited[i] && _matrix[front][i] != MAX_W) // 将该顶点的下一层顶点入队列
{
q.push(i); // 入队列
visited[i] = true; // 标识该顶点已经遍历
}
}
ret.push_back(_vertexs[front]); // 尾插至ret数组
}
return ret;
}
这个思路和树的层序遍历一致,维护一个队列。每当遍历一个顶点的时候,将其下一层的顶点入队列的尾部,一直输出到队列为空为止。
最小生成树
对于一个有n个顶点的连通图,其最小生成树的边数是n-1,也就是说构造最小生成树的本质,其实就是要选出n - 1条边。
想要求图的最小生成树,有两种算法:Kruskal和Prim。这两种算法的本质都是贪心策略,只不过贪心的形式略有不同。
Kruskal
Kruskal的核心是:每次选择所有边中权值最小的边,构成最小生成树。
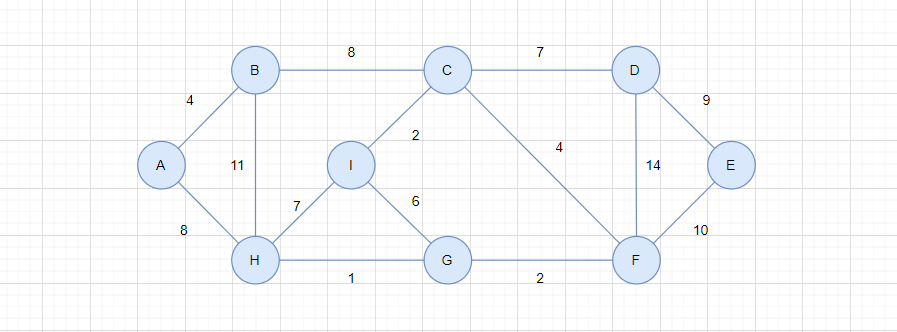
现求以上图的最小生成树。
- 选择整个图权值最小的边,如右上图,权值最小的边
H-G,权值为1,选择该边 - 选择剩下的边中的最小边,如左下图,权值最小的边
I-C,权值为2,选择该边 - 选择剩下的边中的最小边,如右下图,权值最小的边
G-F,权值为2,选择该边
此处的第二步和第三步可以交换,它们的权值都是2。
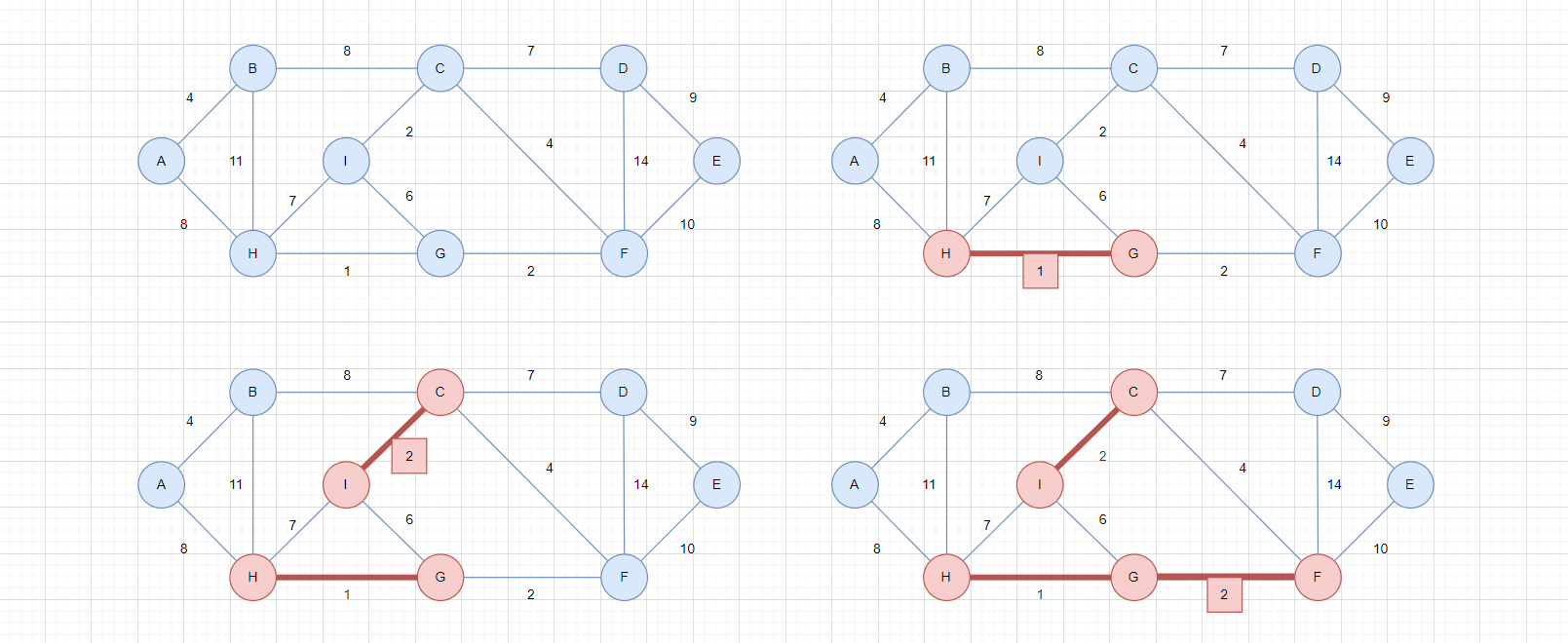
- 选择剩下的边中的最小边,如左上图,权值最小的边
A-B,权值为4,选择该边 - 选择剩下的边中的最小边,如右上图,权值最小的边
C-F,权值为4,选择该边 - 选择剩下的边中的最小边,如左下图,权值最小的边
G-I,权值为6,该边不能选择!
看到左下角的图,如果G-I是连通的,那么整个绿色的部分就会构成一个环,而树是不允许成环的,因此G-I不能选择。
由此可见,Kruskal算法,并不是简单的选出前n-1小的边,还要考虑成环问题,如果成环,就算这条边的权值小,也不能选择。
- 选择剩下的边中的最小边,如右下的图,权值最小的边
H-I,权值为7,该边不能选择!
同理,如果选择了H-I,会构成绿色的环。
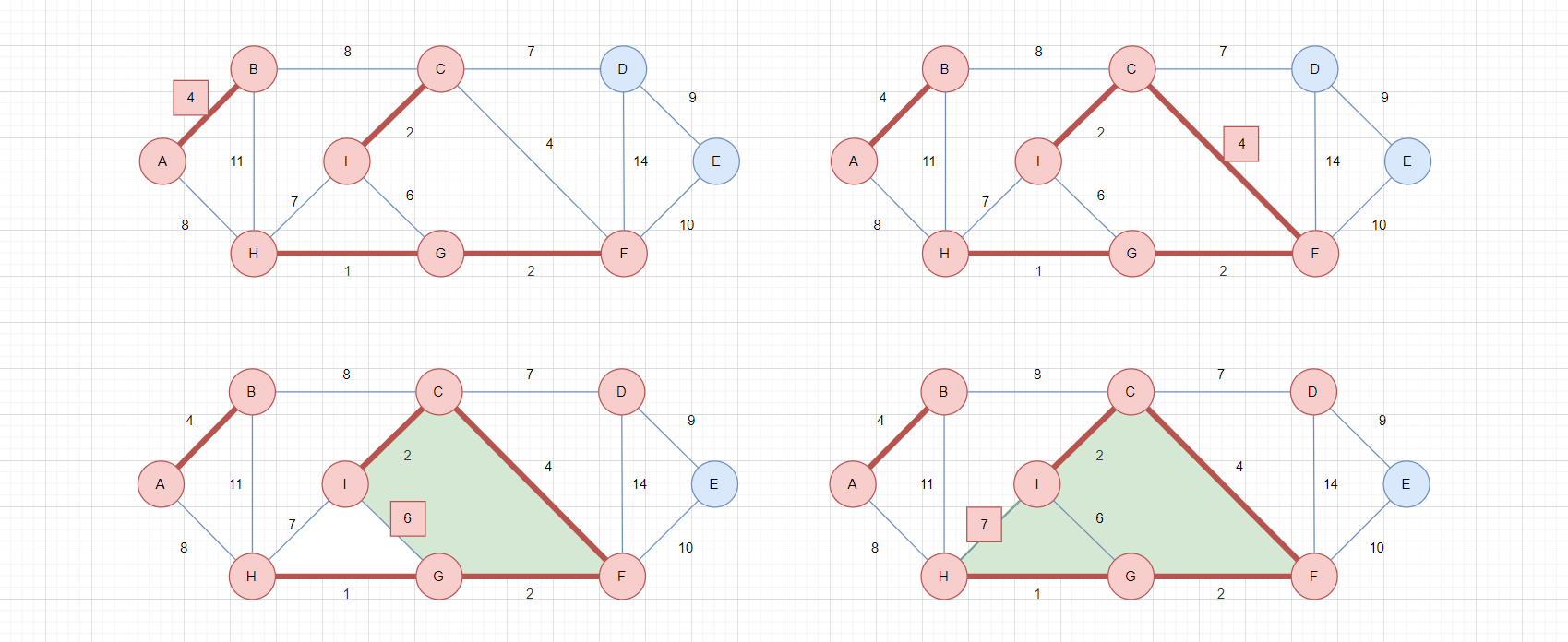
- 选择剩下的边中的最小边,如左上图,权值最小的边
C-D,权值为7,选择该边 - 选择剩下的边中的最小边,如右上图,权值最小的边
A-H,权值为8,选择该边 - 选择剩下的边中的最小边,如左下图,权值最小的边
D-E,权值为9,选择该边
至此,所有的顶点都被连通,生成最小生成树,总权值为37。
通过以上模拟,可见Kruskal有两个要点:
- 选出当前权值最小的边
- 判断边是否会成环
想要获取当前权值最小的边很简单,只需要维护一个小堆(优先级队列)即可,那么如何判断是否会成环?
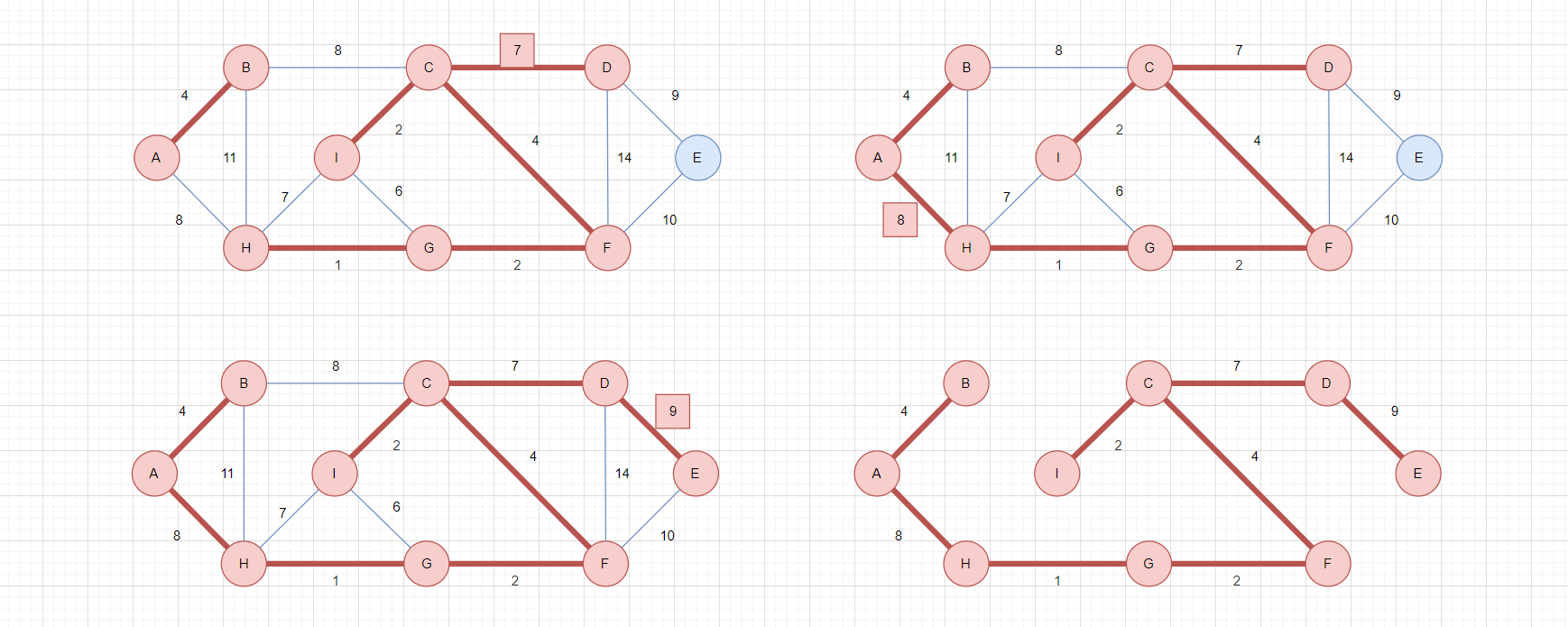
以下是Kruskal算法的中间过程:
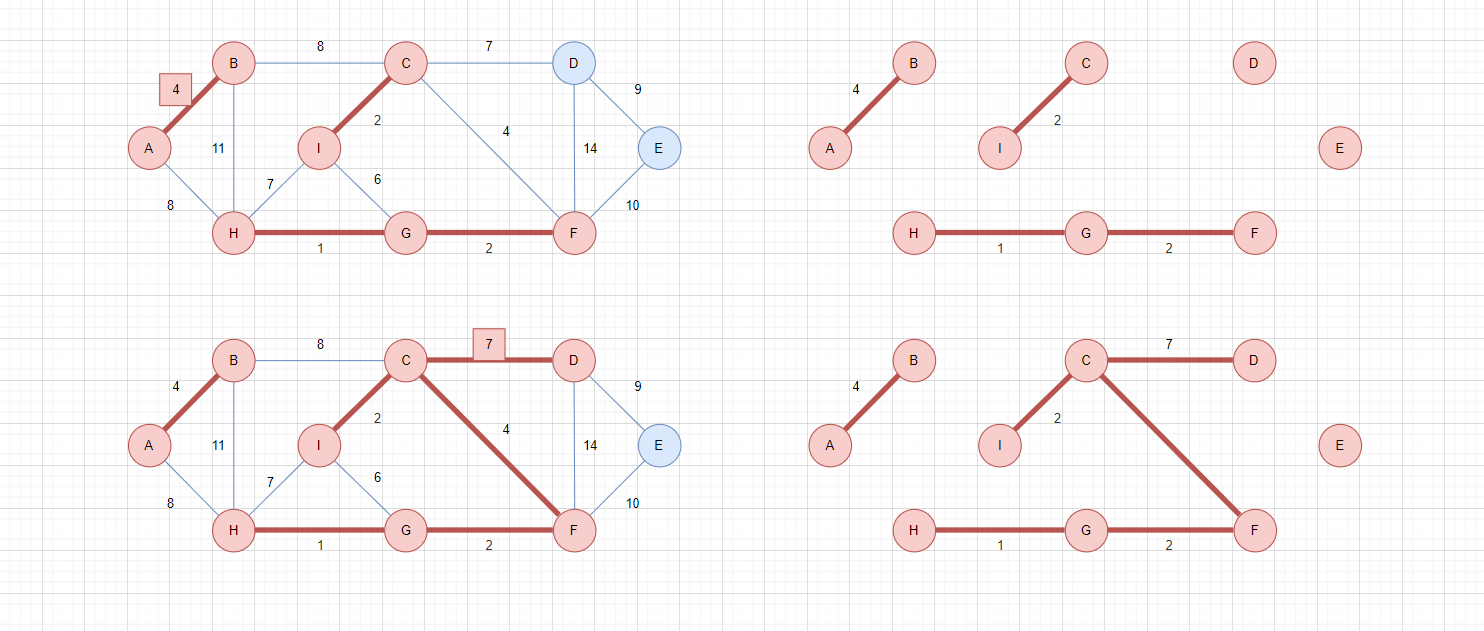
上图是之前的某两个中间图,如果去掉未选择的边,就会变成右边的形式。可以发现,由于Kruskal是在全局范围内,每次选择最小权值的边,所以就会有部分顶点先连通,把连通的顶点视为一个集合,整张图就被分为了多个集合。
比如右下图,整个图被分为三个集合:AB、CDFGHI、E。对于同一集合内的顶点,无需重复连接,否则就会成环!
如图,同一集合内,H-I和I-G都没必要在连通了,一旦连通,就会成环。如果往回翻阅之前的内容,你会发现这两条蓝色边,其实就是刚刚被排除的两条边。
也就是说,在选择边时,要判断边的两个顶点是否在同一个集合中!为了维护这样一个结构,可以使用并查集的数据结构,可见博客[数据结构:并查集]。
此时算法逻辑如下:
- 从小堆中拿出当前的最小边
- 判断边的两个顶点是否在同一个集合中
- 如果在,不选择该边
- 如果不在,选择该边,并把这两个顶点所处的集合合并为一个集合
代码:
struct Edge
{
int _srci;
int _dsti;
W _weight;
Edge(const int srci, const int dsti, const W& weight)
: _srci(srci)
, _dsti(dsti)
, _weight(weight)
{}
bool operator>(const Edge& e) const
{
return _weight > e._weight;
}
};
因为要保存边的概念,此处使用一个结构体来表示边。
_srci:起始顶点的下标_dsti:目的顶点的下标_weight:边的权值
另外的,还要重载一个operator>,因为边要被放在priority_queue中,这需要传入greater<Edge>,这依赖operator>的比大小,比大小的依据是边的权值_weight。
接下来实现Kruskal:
W kruskal(self& minTree)
{}
函数声明如上,此处给用户返回一个最小生成树,而生成树是一颗多叉树,这不好表示。而树是一种特殊的图,所以直接用图来表示最小生成树,也就是self& minTree,用户传入一给空图,直接在空图上构造最小生成树。
返回值W表示生成的最小生成树的总权值。
初始化最小生成树:
int n = _vertexs.size();
minTree._vertexs = _vertexs; // 拷贝_vertex
minTree._indexMap = _indexMap; // 拷贝_indexMap
minTree._matrix.resize(n); // _matrix纵向扩容
for (int i = 0; i < n; i++)
minTree._matrix[i].resize(n, MAX_W); // _matrix横向扩容,初始化为MAX_W
由于用户传的minTree是一个空图,要先将这个minTree扩容至与当前图一致。
优先级队列与并查集:
priority_queue<Edge, vector<Edge>, greater<Edge>> minEdgeHeap;
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
if (i < j && _matrix[i][j] != MAX_W)
minEdgeHeap.emplace(i, j, _matrix[i][j]);
}
}
int sz = 0;
W total = W();
UnionFindSet<V> ufs(_vertexs);
此处创建一个优先级队列minEdgeHeap,由于要建小堆,所以模板参数传入greater<Edge>。通过两层循环遍历_matrix获取所有的边,插入到minEdgeHeap中。
sz:被选中的边数,方便后续判断该图是否有生成树total:被选中边的总权值,做返回值ufs:并查集,维护集合关系,直接用_vertex初始化
Kruskal核心:
while (!minEdgeHeap.empty() && sz < n - 1)
{
Edge minEdge = minEdgeHeap.top(); // 获取当前最小边
minEdgeHeap.pop(); // 别忘了出队列
V& src = _vertexs[minEdge._srci]; // 获取起始顶点值
V& dst = _vertexs[minEdge._dsti]; // 获取目的顶点值
W& weight = minEdge._weight; // 获取边的权值
if (!ufs.inSet(src, dst)) // 判断两个顶点是否在同一个集合
{
minTree.addEdge(src, dst, weight); // 在最小生成树中添加这个边
ufs.unionSet(src, dst); // 将两个顶点所在集合合并
total += weight; // 增加总权值
sz++; // 当前选择的边总数+1
}
}
由于最小生成树最多有n - 1条边,所以一旦sz == n - 1,就没必要继续了,直接结束循环。另外的,如果优先级队列空了,说明已经没有边可以选了,也结束循环。
在循环内部,minEdge首先拿到当前的最小边,由于最小边存储的是顶点下标,所以要先去_vretex中拿到下标的具体值。
随后if (!ufs.inSet(src, dst))判断两个顶点是否在同一个集合中,防止成环。如果不在,那么添加这条边,此时要做的分别为:
- 在最小生成树中添加该边
- 将边的两个顶点所处的集合合并,认为这两个集合内的顶点相互连通
- 增加当前的总权值以及选择的边总数
返回值:
if (sz == n - 1)
return total;
else
return W();
由于最小生成树可能不在,返回时判断sz == n - 1,如果不是n - 1,说明无法构成最小生成树。
Prim
Prim也使用了贪心策略,但是其与Kruskal的不同是,Kruskal是全局的贪心,每次选择全局权值最小的边,而Prim从一个起始顶点出发,选择当前顶点可以连通的最小边。
用之前相同的图,Prim求最小生成树逻辑如下:
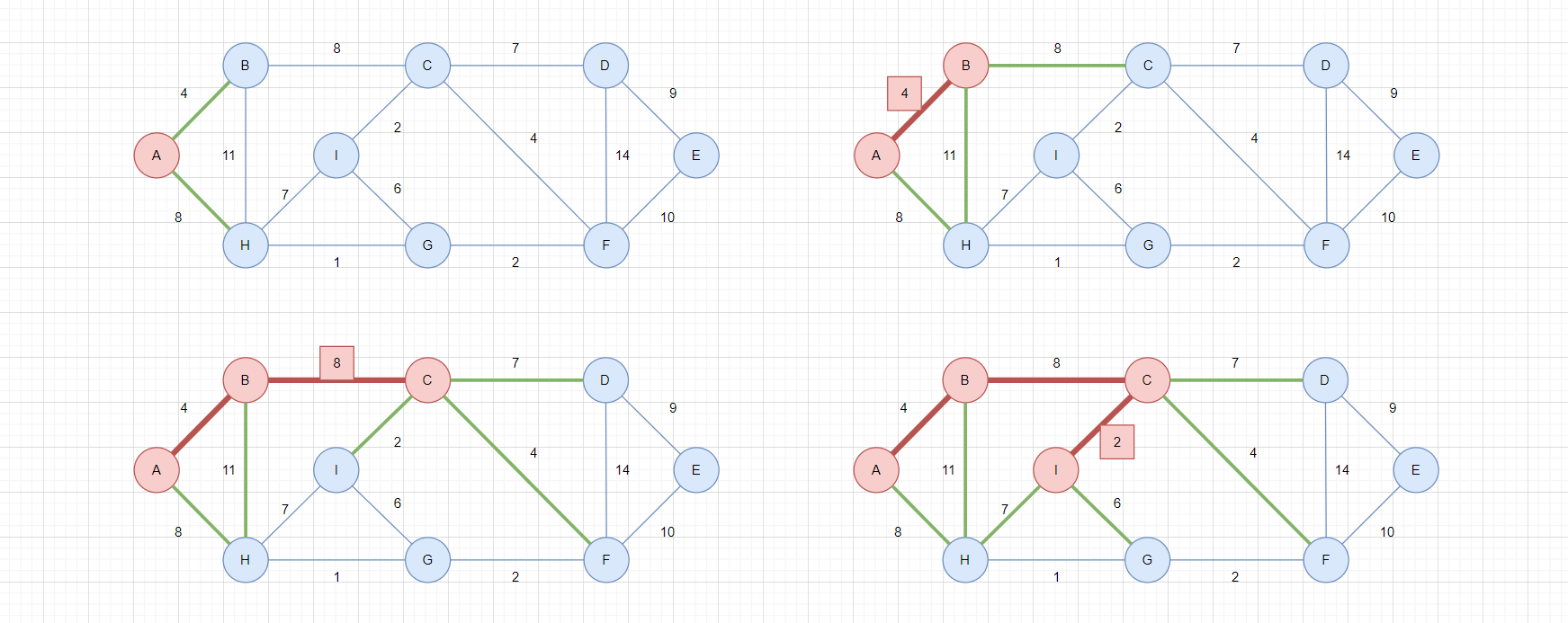
首先,Prim要求用户选定一个顶点,作为起始顶点,这个顶点可以任意,此处选用A顶点。
上图中,绿色的边代表可选边,红色的边代表已选边。
- 选择
A顶点,此时所有A的邻接边都变成可选边,如左上角图 - 在所有可选边中选择权值最小的边,选择
A-B权值为4,此时B被连通,所有B的邻接边变成可选边,如右上图 - 在所有可选边中选择权值最小的边,选择
B-C权值为8,此时C被连通,所有C的邻接边变成可选边,如左下图 - 在所有可选边中选择权值最小的边,选择
C-I权值为2,此时I被连通,所有I的邻接边变成可选边,如右下图
以上过程中,全局都有一个最短边H-G,但是它一直没有被选择,因为从A出发,它目前还是一个不可达的顶点,也就是这个边不是一个可选边。
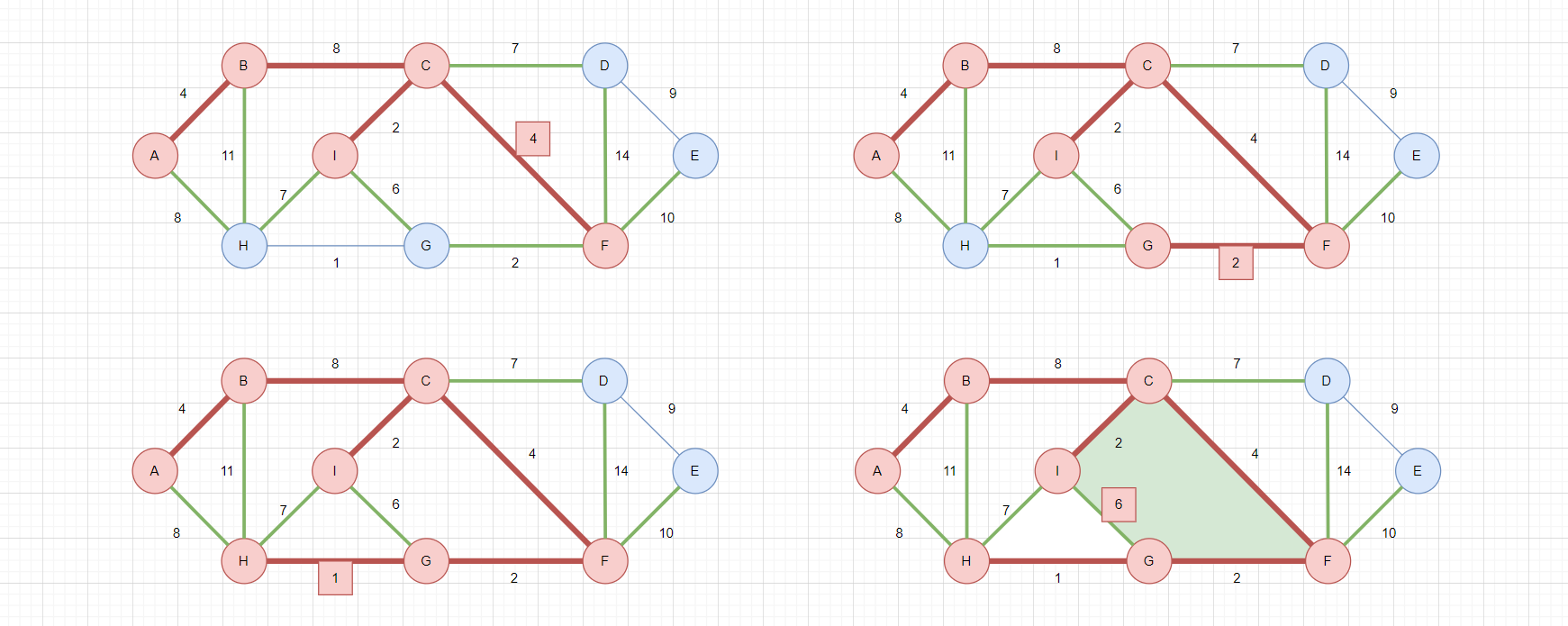
- 在所有可选边中选择权值最小的边,选择
C-F权值为4,此时F被连通,所有F的邻接边变成可选边,如左上图 - 在所有可选边中选择权值最小的边,选择
F-G权值为2,此时G被连通,所有G的邻接边变成可选边,如右上图 - 在所有可选边中选择权值最小的边,选择
G-H权值为1,此时H被连通,所有H的邻接边变成可选边,如左下图 - 在所有可选边中选择权值最小的边,选择
G-I权值为6,但是I已经被连通,成环,如右下图
与Kruskal一样,Prim也要考虑成环问题,在选边时要检测是否会成环,如果成环,那么这条边不能选择。同理,后续的I-H、H-A虽然是可选边,但是都不能选择。
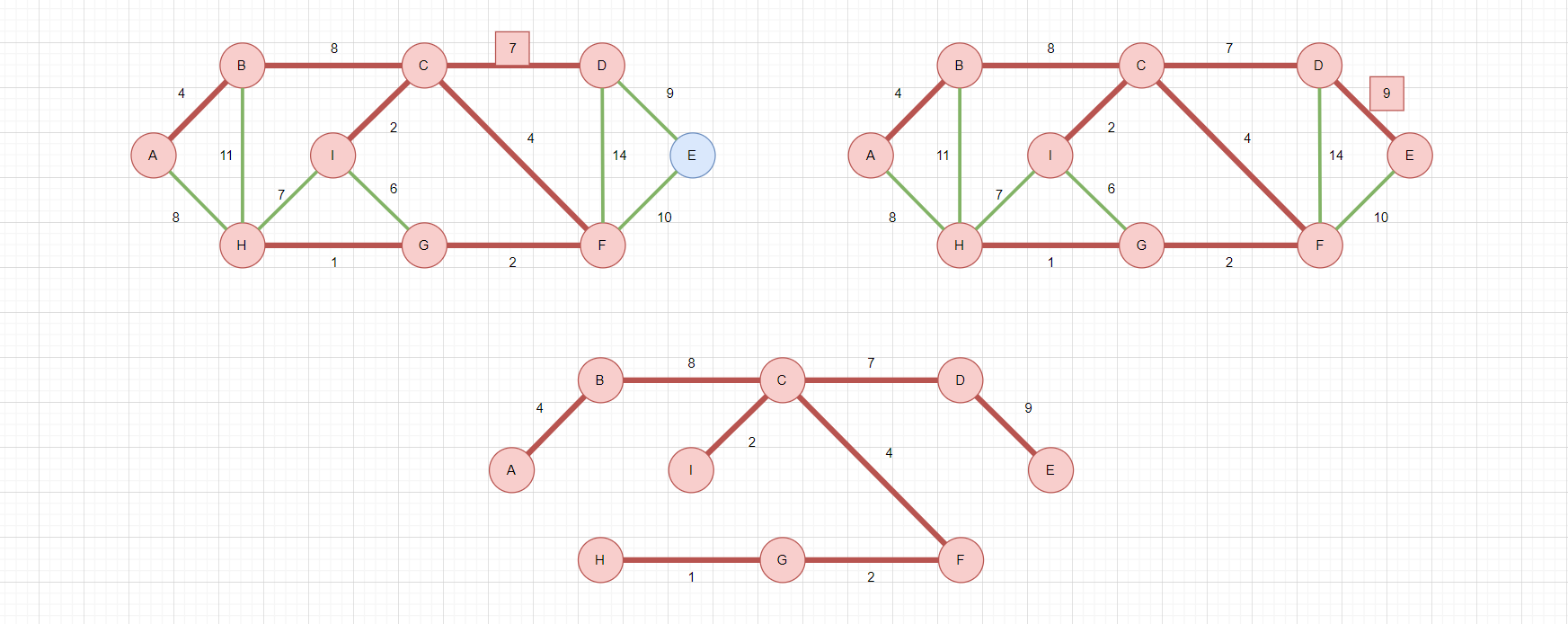
跳过成环的边后,继续选择:
- 在所有可选边中选择权值最小的边,选择
C-D权值为7,此时D被连通,所有D的邻接边变成可选边,如左上图 - 在所有可选边中选择权值最小的边,选择
D-E权值为9,此时E被连通,所有E的邻接边变成可选边,如右上图
至此,所有顶点都被连通,构成最小生成树,总权值为37。这个最小生成树和Kruskal的最小生成树不同,但是最后的总权值是一样的,因为最小生成树可能不止一个!
通过以上模拟,可见Prim有两个要点:
- 选出可选边中权值最小的边
- 判断边是否会成环
这和Kruskal是类似的,但是Prim判断成环的方法会简单很多。
以下是Prim算法的中间过程:
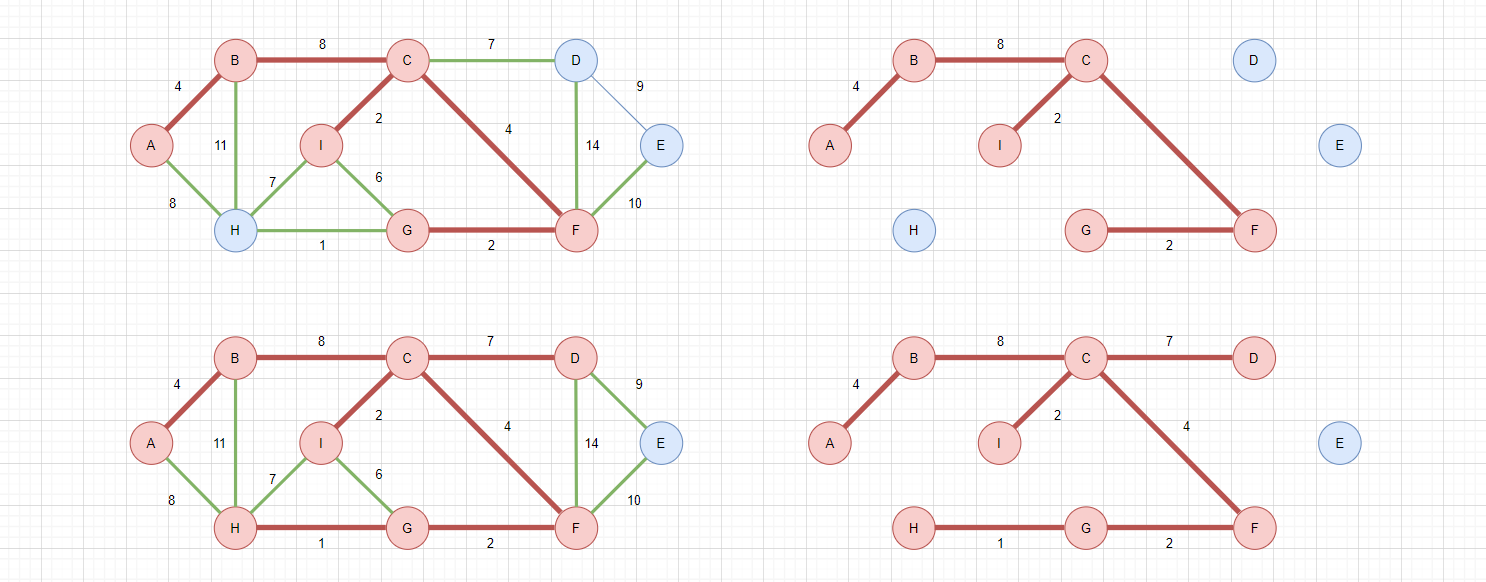
可以发现,在Prim算法过程中,所有已选边一定在同一个集合中,也就是右侧图的红色集合,不会出现多个集合都有已选边的情况,每次添加新的边,一定只增加了一个顶点!
所以只需要维护一个visited数组,每次选择边之前,判断目的顶点是否已经连通即可,无需维护并查集了!
此时算法逻辑如下:
- 从小堆中拿出当前的最小边
- 判断目的顶点是否已经连通
- 如果连通,不选择该边
- 如果不连通,选择该边,并把目的顶点的
visited设为true
Prim代码:
W prim(self& minTree, const V& src)
{}
由于Prim需要一个起始顶点,所以用户要传入第二个参数src,表示起始顶点。minTree和返回值W和Kruskal是一样的。
初始化minTree:
int n = _vertexs.size();
minTree._vertexs = _vertexs;
minTree._indexMap = _indexMap;
minTree._matrix.resize(n);
for (int i = 0; i < n; i++)
minTree._matrix[i].resize(n, MAX_W);
此处的初始化与之前相同,给传入的空图minTree进行扩容。
优先级队列与visited数组:
int srci = getVertexIndex(src);
priority_queue<Edge, vector<Edge>, greater<Edge>> minEdgeHeap; // 优先级队列
for (int i = 0; i < n; i++)
{
if (_matrix[srci][i] != MAX_W)
minEdgeHeap.emplace(srci, i, _matrix[srci][i]); // 初始化src邻接边
}
int sz = 0; // 当前选择的边数
W total = W(); // 当前总权值
vector<bool> visited(n, false);
visited[srci] = true; // 起始顶点视为已连通
此处逻辑与Kruskal不同,优先级队列只存储当前的可选边,起始顶点为src,所以遍历_matrix[srci],把src的邻接边加入minEdgeHeap即可。随后的sz和total与之前一样。
随后维护一个vector<bool> visited数组,全部初始化为false表示尚未连通,把visited[srci]设为true表示起始顶点连通。
Prim核心:
while (!minEdgeHeap.empty() && sz < n - 1)
{
Edge minEdge = minEdgeHeap.top(); // 获取可选边的最小权值
minEdgeHeap.pop();
V& src = _vertexs[minEdge._srci]; // 获取起始顶点值
V& dst = _vertexs[minEdge._dsti]; // 获取目的顶点值
W& weight = minEdge._weight; // 获取边的权值
if (!visited[minEdge._dsti]) // 判断目的顶点是否已经连通
{
minTree.addEdge(src, dst, weight); // 添加边到最小生成树
visited[minEdge._dsti] = true; // 将目的顶点视为连通
sz++; // 已经选择的边总数+1
total += weight; // 增加总权值
for (int i = 0; i < n; i++) // 将目的顶点的所有邻接边都加入可选边
{
if (_matrix[minEdge._dsti][i] != MAX_W && !visited[i])
minEdgeHeap.emplace(minEdge._dsti, i, _matrix[minEdge._dsti][i]);
}
}
}
获取到当前可选的最小边后,if (!visited[minEdge._dsti])判断目的顶点是否连通,如果没有连通,那么选择该边。随后将这条边添加到最小生成树中,visited数组标记目的顶点已连通。最后要把目的顶点的所有邻接边添加到可选边中。
返回值:
if (sz == n - 1)
return total;
else
return W();
由于最小生成树可能不在,返回时判断sz == n - 1,如果不是n - 1,说明无法构成最小生成树。
最短路径
最短路径问题,又分为单源最短路径和多源最短路径。
单源最短路径:给出一个起始顶点,求出该顶点到所有顶点的最短路,算法:Dijkstra和Bellman-Ford多源最短路径:求出任意两个顶点之间的最短路径,算法:Floyd-Warshall。
Dijkstra
Dijkstra:从起始顶点出发,每次选择当前路径最短的顶点,随后尝试其它顶点是否可以通过该顶点缩短路径
以下图为例:
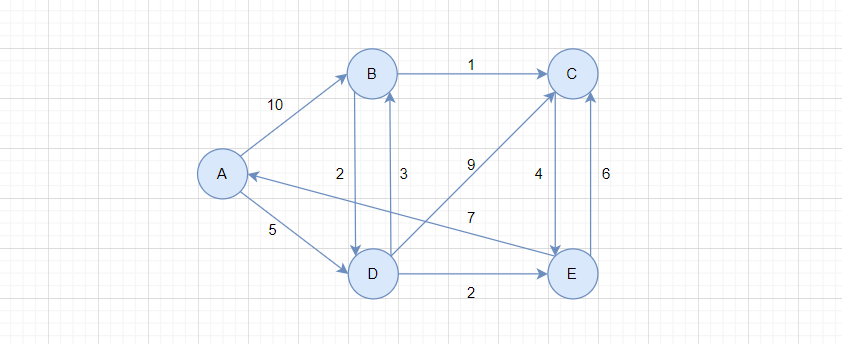
从A顶点出发,求所有顶点的最短路径:
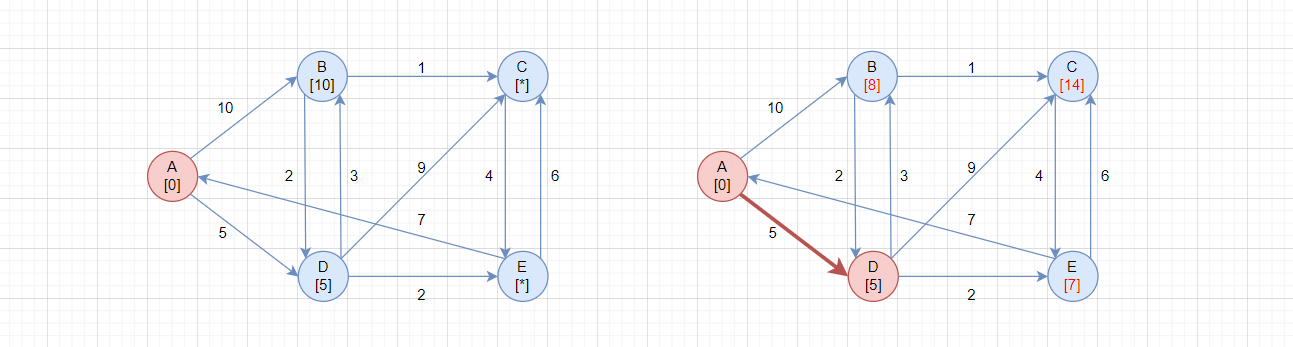
首先初始化所有顶点的最短路径,先初始化A的邻接顶点的路径长度,A[0]表示A到自己的距离为0,C[*]表示A无法到达C。
- 在所有未选顶点
BCDE中,选择路径最短的顶点,此处选择D[5],因为它路径最短 - 将所有与
D邻接的顶点进行松弛操作
松弛操作:
A->B = 10,A->D->B = 8,通过D可以更快到达B,更新B的最短路径为8A->C = *,A->D->C = 14,通过D可以更快到达C,更新C的最短路径为14A->E = *,A->D->E = 7,通过D可以更快到达E,更新C的最短路径为7
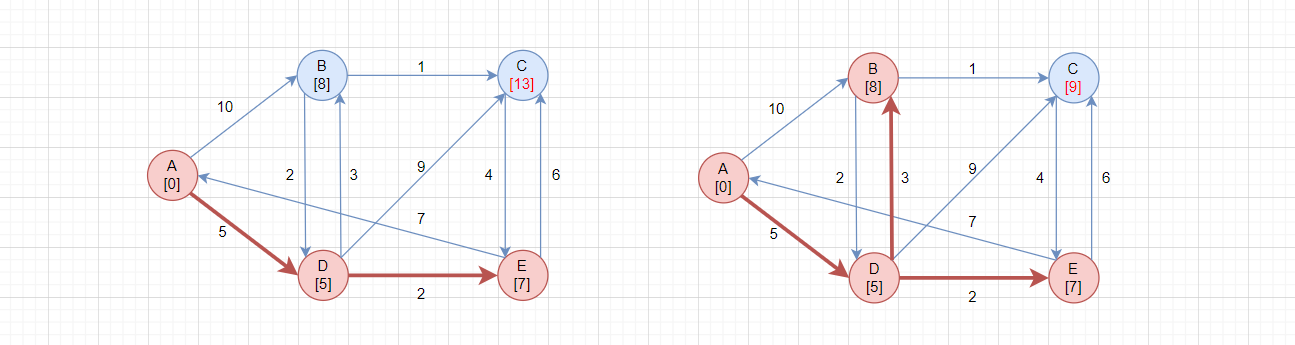
- 在所有未选顶点
BCE中,选择路径最短的顶点,此处选择E[7],因为它路径最短 - 将所有与
E邻接的顶点进行松弛操作
松弛操作:
E->A,由于A已选,不进行松弛A->C = 14,A->E->C = 13,通过E可以更快到达C,更新C的最短路径为13A->B = 8,A->E->B = *,通过E无法更快到达B,不更新
随后在BC中选择路径在最短的顶点,选择B[8],再对C进行松弛操作,如右图。
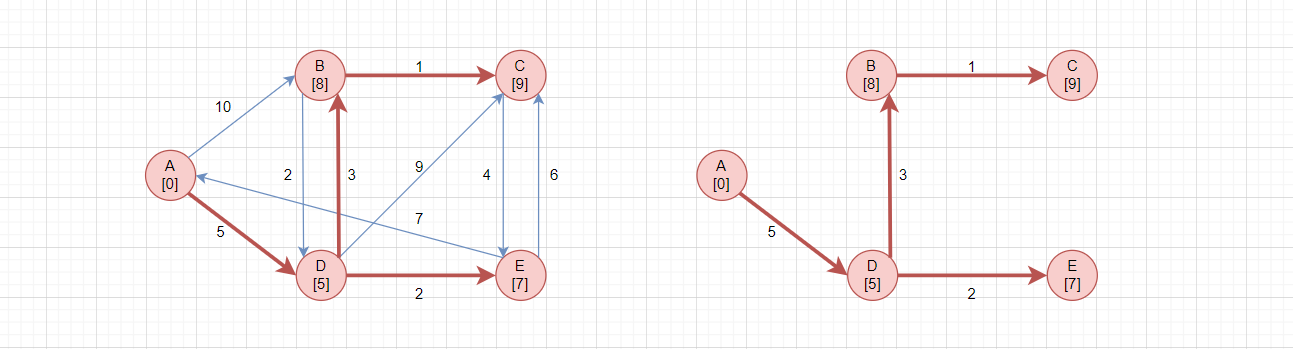
最后只能选择C,选择完毕后,所有节点都选择完毕,完成最短路径的计算,如右图。
其实Dijkstra算法就是每次都找到一个顶点,并且尝试能否通过这个顶点来缩短其他顶点的路径。
但是Dijkstra无法处理带有负数权值的图,其得不到最短路径。
如图所示:
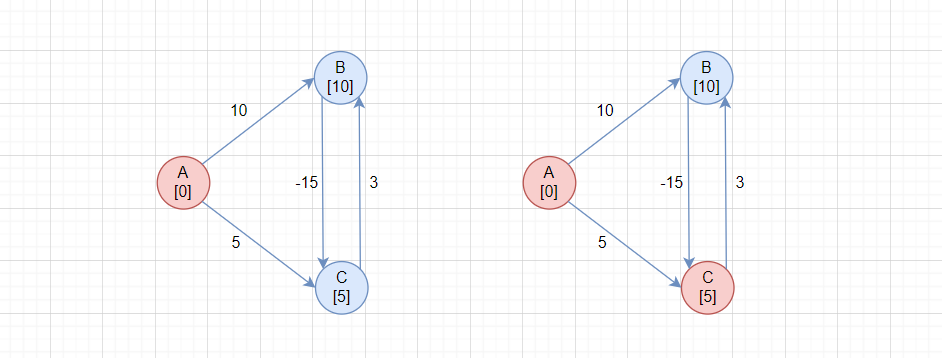
此处以A为起始顶点求最短路径,C[5]小于B[10],所以先确定了C,再确定B。当确定B后,进行松弛操作,发现A->B->C的路径为-5,更短。但是由于松弛操作不会更新已经被确定的顶点,导致最短路径错误。
Dijksta算法逻辑如下:
- 选择所有未选顶点中,路径最短的顶点
- 对该顶点进行松弛操作,也就是尝试通过该顶点缩短其它顶点的路径
接下来实现代码。
函数声明:
void dijkstra(const V& src, vector<W>& distance, vector<int>& parentPath)
src:起始顶点,求其他顶点到该顶点的最短路径distance:到每个顶点的最短路径的距离parentPath:存储路径的上一个顶点
此处后两个参数需要额外讲解一下。
既然要求最短路径,那么就要同时同时返回路径关系,和最短路径长度,它们分别由parentPath和distance数组维护。
如下:
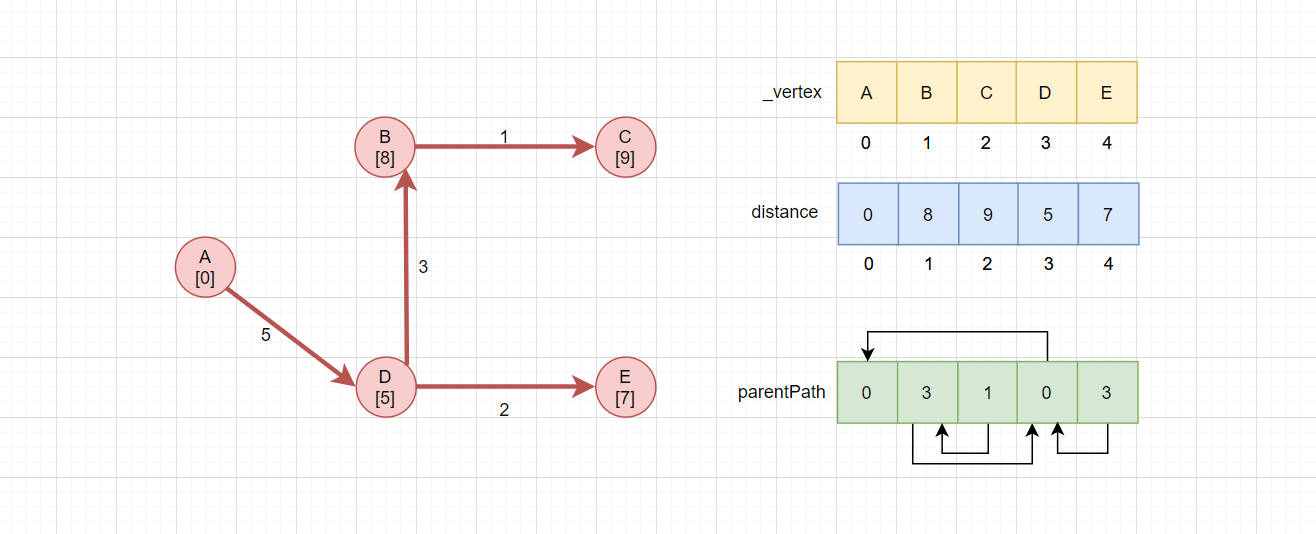
_vertex:维护了顶点值与下标的映射关系,每个下标代表一个具体的顶点。distance:维护起始顶点到其他顶点的最短距离,比如distance[1] = 8,意味着B->A的最短距离为8,因为下标1代表B。parentPath:记录顶点到达起始顶点的最短路径的上一个顶点
这个parentPath比较复杂,因为是求最短路径,起始顶点那么到达另一个顶点,必然只有一条路径!比如A->C只有A->D->B->C这一条路径,如何存储A->C的路径?因为A->B的路径也是唯一的,那么只需要存储C的上一个顶点是B,那么就可以通过A->B的最短路径加上B->C这个关系,就是C的最短路径。
因此parentPath[2] = 1,表示C(下标为2)的上一个顶点为B(下标为1)。而parentPath[1] = 3,表示B的上一个顶点为D。parentPath[3] = 0表示D的上一个顶点为A。这样通过parentPath,就可以一层层反向找到路径C<-B<-D<-A。
另外的,对于A节点本身,parentPath[0] = 0,表示A->A上一节点就是自己,也就是说当parentPath[i] = i,说明i是起始顶点。当然也可以使用-1之类的值,只需要可以辨识出起始顶点即可。
初始化:
int n = _vertexs.size();
int srci = getVertexIndex(src);
distance.resize(n, MAX_W);
parentPath.resize(n, -1);
distance[srci] = W();
parentPath[srci] = srci;
vector<bool> visited(n, false);
首先要把distance和parentPath进行初始化,distance扩容至n,所有值初始化为MAX_W表示刚开始所有顶点不可达,parentPath扩容至n,所有至初始化为-1表示没有上一个顶点。
随后初始化起始顶点,distance[srci] = W()即初始化起始顶点到自己的距离为0,如果W是其它泛型,这取决于默认构造。parentPath[srci] = srci将起始顶点的上一个顶点设为自己,表示这个顶点是起始顶点。
最后创建一个visited数组,表示已经确定最短路径的顶点,此处注意不要初始化visited[srci],因为还没有把srci的
邻接顶点加入到distance中,这一步其实与松弛操作的行为一样,可以使用后面的循环统一处理。
初始化完后,状态如下:
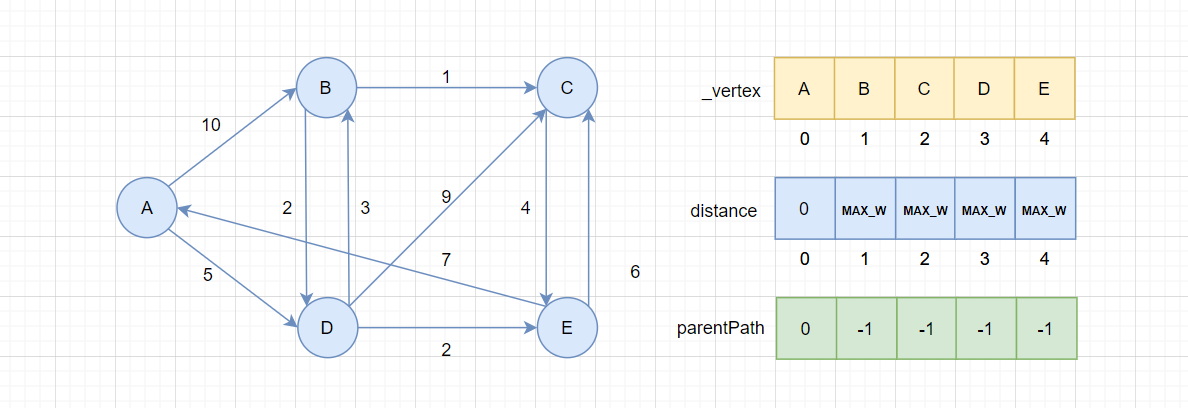
此处注意,A的颜色是蓝色,表示A还没有选中。由于算法每次选择当前最小距离的节点,其他节点的距离都是MAX_W,只有起始顶点是0,所以第一次操作一定处理了起始顶点。
经过第一次操作,状态如下:
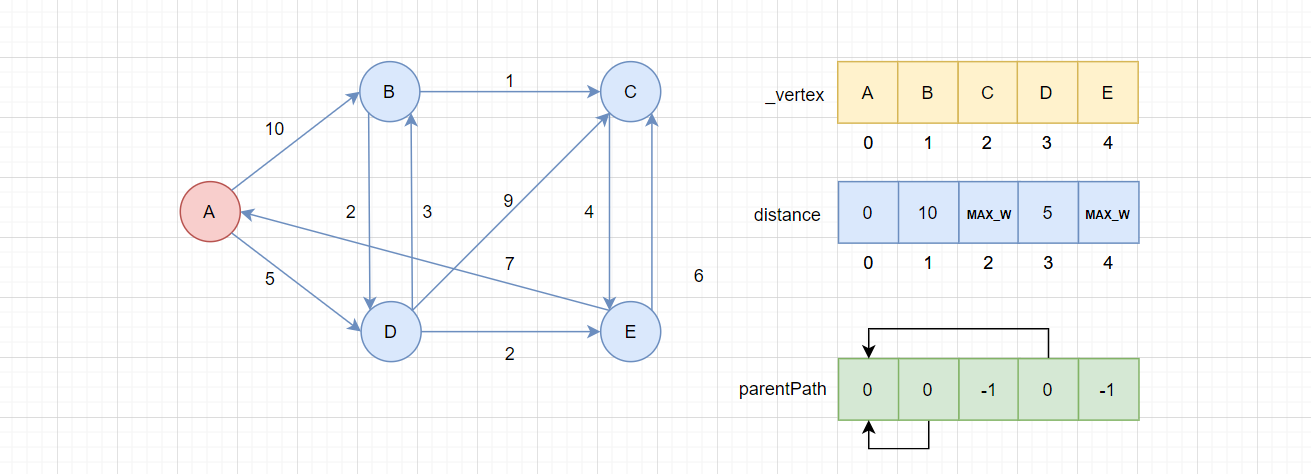
此时A才算是被确定的顶点,因为要处理B和D的distance和parentPath数组,这个如果单独初始化会比较麻烦,可以通过Dijkstra算法内部一起完成。
Dijkstra核心:
for (int i = 0; i < n; i++)
{
W minDist = MAX_W; // 当前最短距离的顶点
int minIndex = -1; // 当前最短距离的顶点的下标
for (int j = 0; j < n; j++) // 循环遍历所有顶点,找到当前最短距离的顶点
{
if (!visited[j] && distance[j] < minDist) // 只有该顶点没有被确定,并且距离小于当前的minDist,更新
{
minDist = distance[j];
minIndex = j;
}
}
visited[minIndex] = true; // 确定当前的minDist后,将其visited标识为已经确定的顶点
// 松弛操作
for (int j = 0; j < n; j++) // 循环遍历所有顶点,进行松弛操作
{
if (!visited[j] && _matrix[minIndex][j] != MAX_W && // 被松弛的顶点还没有被确定,并且是minIndex的邻接顶点
distance[j] > minDist + _matrix[minIndex][j]) // 如果通过minIndex到达j距离更短,更新
{
parentPath[j] = minIndex; // 上一个顶点设为 minIndex
distance[j] = minDist + _matrix[minIndex][j]; // 距离设为 src->minIndex + minIndex->j
}
}
}
以上for循环n次,每次确定一个顶点的最短路径,等到n个顶点都确定了,那么最短路径就生成完毕了。
上半部分是在完成选择当前的距离最短的顶点,其下标为minIndex。
下半部分是在完成松弛操作,所有和minIndex邻接的顶点,并且该顶点没有被确定,并且通过minIndex到达j距离更短,那么更新到达j在最短路径。
-
distance[j] > minDist + _matrix[minIndex][j]:distance[j]是src->j的距离,minDist + _matrix[minIndex][j]是src->minIndex + minIndex->j的1距离,如果条件成立,说明通过minIndex到达j,比当前的距离更短,此时进行更新。 -
parentPath[j] = minIndex:将j的上一个顶点更新为minIndex -
distance[j] = minDist + _matrix[minIndex][j]:将src->j的最短距离设置为src->minIndex的距离加上minIndex->j
Bellman-Ford
相比于Dijkstra,Bellman-Ford是更加暴力的做法,每次确定两个顶点i和j,查看src->i->j是否比src->j更短。并且图中有几个顶点,这个过程最多就会执行多少次,因此其复杂度到达了
O
(
N
3
)
O(N^{3})
O(N3)。虽然复杂度高了,但是Bellman-Ford可以处理负数权值。
通过Bellman-Ford求下图从A出发的最短路径:
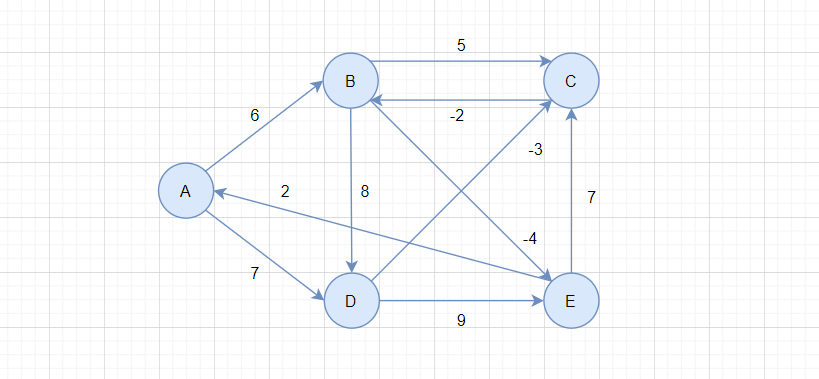
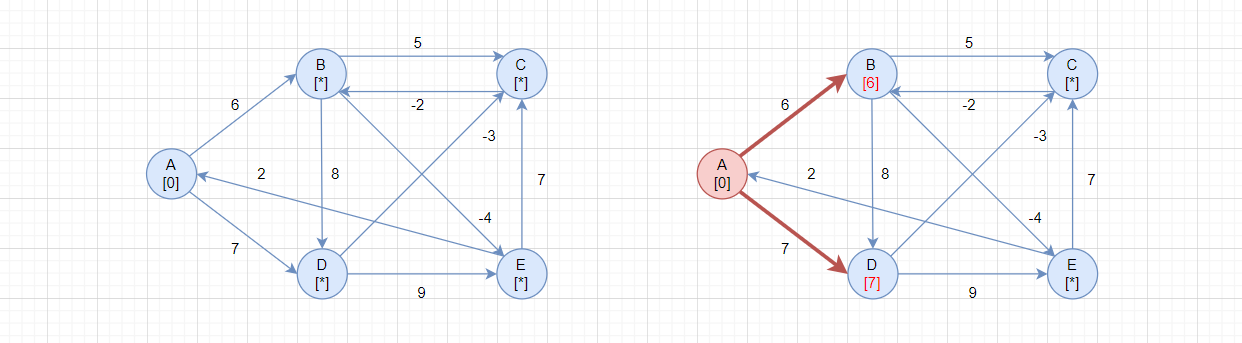
刚开始,BCDE的路径长度都是*,即不可达,src为A。
第一轮检测,第一轮循环,i = A:
- 当
i = A、j = B:src->A = 0、A->B = 6,所以src->A->B = 6,当前src->B = *,更新路径 - 当
i = A、j = C:src->A = 0、A->C = *,所以src->A->B = *,当前src->B = *,不更新路径 - 当
i = A、j = D:src->A = 0、A->D = 7,所以src->A->D = 7,当前src->D = *,更新路径 - 当
i = A、j = E:src->A = 0、A->E = *,所以src->A->E = *,当前src->B = *,不更新路径
此处第一轮循环,src->A其实就是A->A,所以看起来有一点点迷惑性。
更新完成后,从左图变成右图。
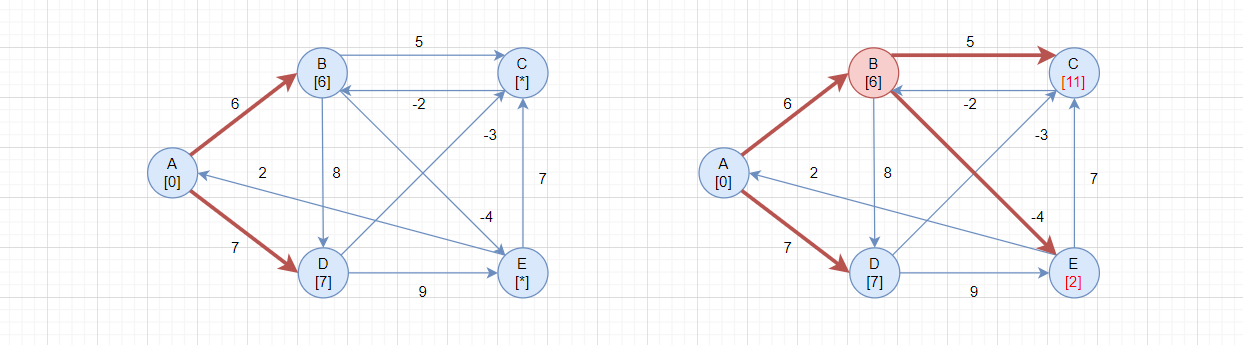
第一轮检测,第二轮循环,i = B:
- 当
i = B、j = A:src->B = 6、B->A = *,所以src->B->A = * + 6,当前src->A = 0,不更新路径 - 当
i = B、j = C:src->B = 6、B->C = 5,所以src->B->C = 11,当前src->C = *,更新路径 - 当
i = B、j = D:src->B = 6、B->D = 8,所以src->B->D = 12,当前src->D = 7,不更新路径 - 当
i = B、j = E:src->B = 6、B->E = -4,所以src->D->E = 2,当前src->E = *,更新路径
更新完成后,从左图变成右图。
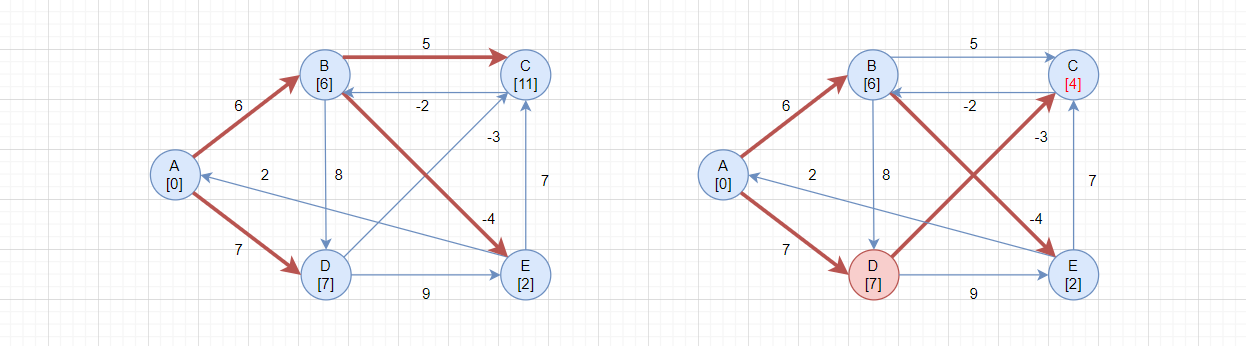
第一轮检测,第三轮循环,i = C,这一轮没有更新任何节点,略。
第一轮检测,第四轮循环,i = D:
- 当
i = D、j = C:src->D = 7、D->C = -3,所以src->D->C = 4,当前src->C = 11,更新路径
这轮循环只更新了一个路径,其它没更新的就不列举了。
由于之前通过src->B->C,现在改为src->D->C,那么B->C这条路径就被淘汰了,右图中不再标红。
当第一轮检测结束,进行第二轮检测:
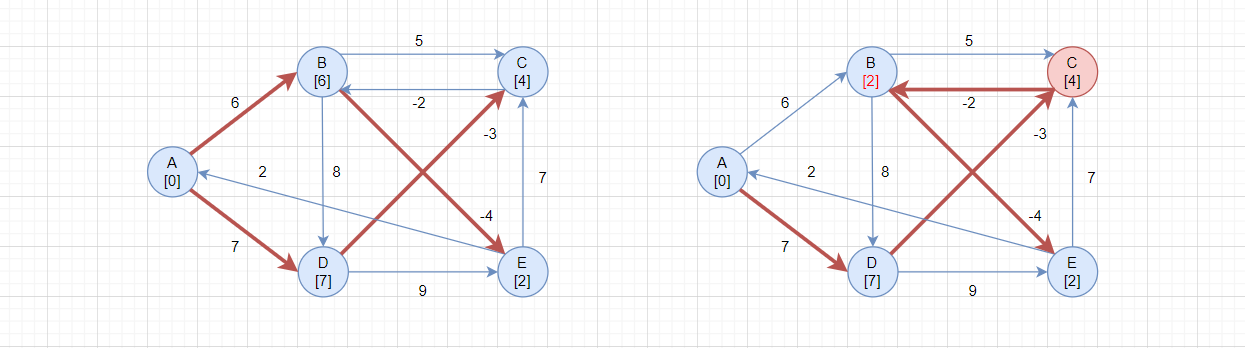
第二轮检测,第一轮循环,i = A:没有任何顶点更新
第二轮检测,第二轮循环,i = B:没有任何顶点更新
第二轮检测,第三轮循环,i = C:
- 当
i = C、j = B:src->C = 4、C->B = -2,所以src->C->B = 2,当前src->B = 6,更新路径
第二轮检测,第四轮循环,i = D:没有任何顶点更新
第二轮检测,第五轮循环,i = E:没有任何顶点更新
随后进入第三轮检测:
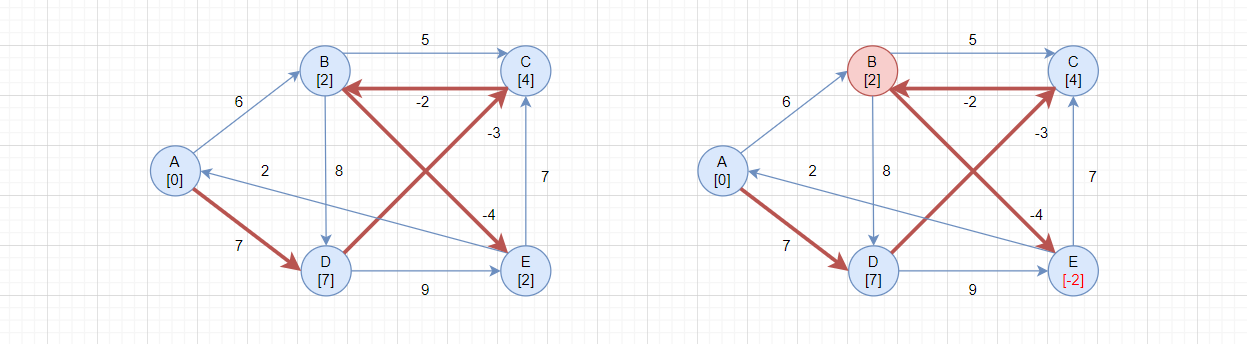
第三轮检测,第一轮循环,i = A:没有任何顶点更新
第三轮检测,第二轮循环,i = B:
- 当
i = B、j = E:src->B = 2、B->E = -4,所以src->B->E = -2,当前src->E = 2,更新路径
第三轮检测,第三轮循环,i = C:没有任何顶点更新
第三轮检测,第四轮循环,i = D:没有任何顶点更新
第三轮检测,第五轮循环,i = E:没有任何顶点更新
其实第三轮检测之后,已经是最短路径了,后续的检测都没有顶点更新。
最终最短路径如下:
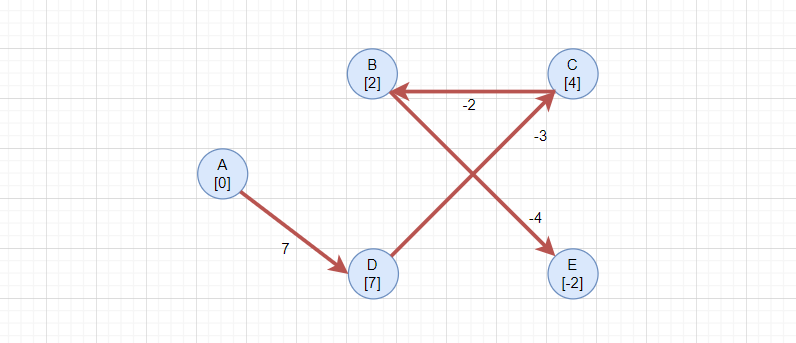
其实这个 Bellman-Ford就是个暴力算法。
但是这个算法也会无法处理的情况,负权回路问题:
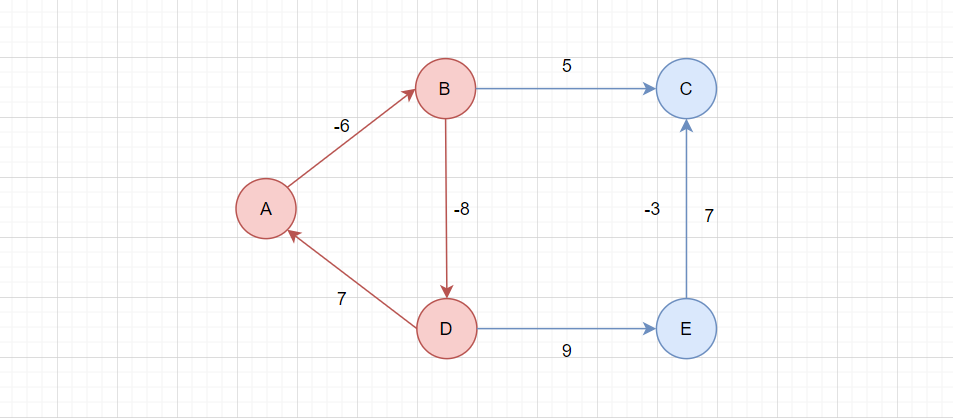
图中,红色的回路称为负权回路,这个回路的所有边权值总和为负数。
这就会导致一个问题:回路中的顶点,可以找到一个无穷小的到达自己的路径。
比如:A->A = 0,但是A->B->C->A = -7,A->B->C->A->B->C->A = -14,永远都可以找到一条更短的路径。对于这种情况,根本就求不出最短路径。
接下来实现代码:
函数声明:
bool bellmanFord(const V& src, vector<W>& distance, vector<int>& parentPath)
此处的所有参数都和之前相同,唯一不同的是返回值,返回值变成一个bool值,用于判断负权回路,如果存在负权回路,根本没有最短路径,此时直接返回false。
初始化:
int n = _vertexs.size();
distance.resize(n, MAX_W);
parentPath.resize(n, -1);
int srci = getVertexIndex(src);
distance[srci] = W();
parentPath[srci] = srci;
与之前相同,不赘述。
bellmanFord核心:
int k = n;
bool flag = true;
while(k-- && flag)
{
flag = false; // 更新flage为false,表示本轮没有更新顶点
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
if (distance[i] != MAX_W && _matrix[i][j] != MAX_W
&& distance[j] > distance[i] + _matrix[i][j]) // 判断 src -> i - > j 是否更短
{
flag = true;
parentPath[j] = i;
distance[j] = distance[i] + _matrix[i][j];
}
}
}
}
由于bellmanFord算法最多经过n次一定可以找到最短路径,所以设置一个k记录循环次数,超出n次跳出循环。另外的,如果某一轮没有任何一个顶点更新,说明已经提前找到了最短路径,此时也终止循环。
内部两层for循环枚举i、j,判断src->i->j是否比src->j更短,如果更短那么更新。
flag = true:本轮循环更新了最短路径parentPath[j] = i:更新j的上一个顶点为idistance[j] = distance[i] + _matrix[i][j]:更新src->j的距离为src->i + i->j
判断负权回路:
// 负权回路
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
// src -> i - > j 是否更短?
if (distance[i] != MAX_W && _matrix[i][j] != MAX_W
&& distance[j] > distance[i] + _matrix[i][j])
{
return false;
}
}
}
return true;
想要判断负权回路很简单,n轮循环后,只需要再进行一轮bellmanFord算法,如果还有路径可以缩短,说明这个路径可以无限缩短,也就是负权回路,此时返回false。
Floyd-Warshall
之前的最短路径都是求以某个顶点出发的最短路径,称为单源最短路径。而多源最短路径,就是求任意两点之间的最短路径。
其实可以用非常暴力的解法,那就是利用一层循环枚举所有的顶点,以该顶点出发进行一次bellmanFord算法。但是时间复杂度已经到达了惊人的
O
(
N
4
)
O(N^{4})
O(N4)。
因此需要额外的算法专门计算多源最短路径问题。Floyd-Warshall算法使用了动态规划思想,如果没有学过动态规划,其实还是有点难以理解的。
假设某图有ABCDE五个顶点。
如图:
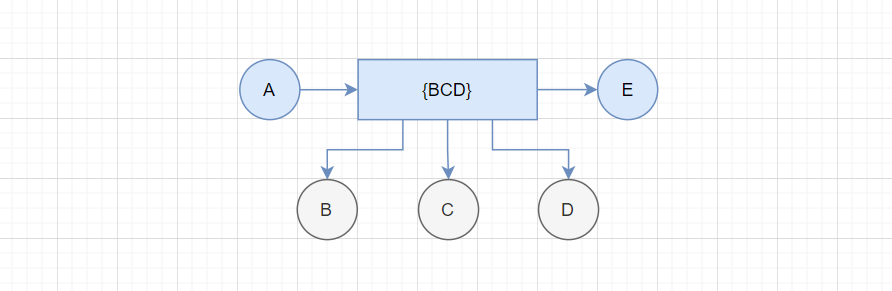
假设要求A->E的最短路径,那么最短路径应该为A->{BCD}->E,此处的{BCD}代表BCD中的任意顶点组合,比如A->B->E、A->B->D->E,A->E等等。
因为除了A->E,只有BCD三个顶点,所以A->{BCD}->E一定可以组成A->E的最短路径。
如果已知A->{BC}->E的最短路径,也就是假设图中没有D顶点,那么可以推断出从A->{BC}->E到A->{BCD}->E的转移方程:

如图,A->{BC}->E到A->{BCD}->E,无非就是多个一个D顶点,而这个D顶点可能在最短路径中,也可能不在最短路径中。右侧的红色路径,一定是左侧蓝色路径的某一种。哪一个蓝色路径比较短,那么红色路径就是哪一个。
如果包含D,那么:A->{BCD}->E = A->{...}->D + D->{..}->E
如果不包含D,那么:A->{BCD}->E = A->{BC}->E
只需要比较两者大小即可。
假设dp(i,j,k)表示路径i->{...}->j,{...}中间包含{0, 1, 2 .... , k}的任意顶点组合,那么状态转移方程为:
d p ( i , j , k ) = m i n ( d p ( i , j , k − 1 ) , d p ( i , k , k − 1 ) + d p ( k , j , k − 1 ) ) dp(i, j, k) = min(dp(i, j, k - 1), dp(i, k, k - 1) + dp(k, j, k - 1)) dp(i,j,k)=min(dp(i,j,k−1),dp(i,k,k−1)+dp(k,j,k−1))
这是一个三维的动态规划,编程中可以降成二维。
注意,后续dp[][]表示实际编程的二维数组,而dp()表示数学上的状态转移方程。
假设维护一个二维动态规划数组dp,dp[i][j]表示i->j的最短路径长度,当前引入[0, k]的顶点,那么:
dp[i][j] = min(dp[i][j], dp[i][k] + dp[k][j])
左侧的dp[i][j]表示dp(i,j,k),而右侧的dp[i][j]表示dp(i,j,k-1),因为编程中,此处存储的是上一轮k-1的数据。
dp[i][k]和dp[k][j]同理:
- 如果
k > i,j,那么此处dp[i][j]其实是k-1轮的数据 - 如果
i,j > k,那么dp[i][j]就已经被更新为了第k轮的数据,但是根据状态转移方程,dp(i,j,k) <= dp(i,j,k-1),所以这反而能更快找到最短路径
代码:
函数声明:
void FloydWarshall(vector<vector<W>>& distance, vector<vector<int>>& parentPath)
此处的distance和parentPath都升至二维,因为要求任意两个顶点间的最短路径。distance[0]存储下标为0的顶点到其他所有顶点的最短路径,parentPath同理。
此处distance[i][j]表示i->j的最短路径,这和dp[i][j]功能相同,所以后续直接在distance上进行动态规划。
初始化:
int n = _vertexs.size();
// 初始化容积
distance.resize(n);
parentPath.resize(n);
for (int i = 0; i < n; i++)
{
distance[i].resize(n, MAX_W);
parentPath[i].resize(n, -1);
}
首先将distence和parentPath的容积初始化为n*n。
初始化邻接顶点:
for (int i = 0; i < n; i++)
{
parentPath[i][i] = i; // 自己到自己,上一顶点的下标就是自己的下标
distance[i][i] = W(); // 自己到自己,距离为0
for (int j = 0; j < n; j++)
{
if (_matrix[i][j] != MAX_W) // 判断 i->j 可达
{
parentPath[i][j] = i; // j的上一个顶点更新为i
distance[i][j] = _matrix[i][j]; // 更新i->j的距离
}
}
}
FloydWarshall核心:
for (int k = 0; k < n; k++) // 中间插入第n个节点
{
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++) // 到k为止,i -> j 的最短路径
{
if (distance[i][k] != MAX_W && distance[k][j] != MAX_W
&& distance[i][j] > distance[i][k] + distance[k][j])
{
parentPath[i][j] = parentPath[k][j];
distance[i][j] = distance[i][k] + distance[k][j];
}
}
}
}
这三层循环,表示:包含顶点{0, 1, 2 ... k}的任意组合,i->j的最短路径。
if条件判断:
distance[i][k] != MAX_W:i->k路径存在distance[k][j] != MAX_W:k->j路径存在distance[i][j] > distance[i][k] + distance[k][j]:i->{...}->j与i->{...}->k->{...}->j哪一个更短,如果加入k后变短了,进行更新
更新:
distance[i][j] = distance[i][k] + distance[k][j]:更新i->j的最短路径为i->{...}->k->{...}->j。parentPath[i][j] = parentPath[k][j]:j的前一个顶点,更新为k->j中j的前一个顶点。
此处注意不是 parentPath[i][j] = k,k不一定是j的上一个顶点,路径为i->{...}->k->{...}->j,{...}中可能有其他顶点。
总代码
UnionFindSet.hpp:
#pragma once
#include <iostream>
#include <vector>
#include <map>
#include <stdexcept>
using namespace std;
template <typename T>
class UnionFindSet
{
public:
UnionFindSet(vector<T>& source)
: _ufs(source.size(), -1)
{
for (int i = 0; i < source.size(); i++)
_mp[source[i]] = i;
}
int findRoot(T x)
{
if (_mp.count(x) == 0)
throw runtime_error("value does not exist"); // 值不存在
int root = _mp[x];
while (_ufs[root] >= 0 && _ufs[_ufs[root]] >= 0)
{
_ufs[root] = _ufs[_ufs[root]]; // 压缩路径
root = _ufs[root];
}
if (_ufs[root] >= 0)
root = _ufs[root];
return root;
}
void unionSet(T x1, T x2)
{
int root1 = findRoot(x1);
int root2 = findRoot(x2);
if (root1 == root2)
return;
// 按秩合并
if (_ufs[root1] < _ufs[root2])
{
_ufs[root1] += _ufs[root2];
_ufs[root2] = root1;
}
else
{
_ufs[root2] += _ufs[root1];
_ufs[root1] = root2;
}
}
bool inSet(T x1, T x2)
{
return findRoot(x1) == findRoot(x2);
}
size_t count()
{
size_t size = 0;
for (auto& num : _ufs)
{
if (num < 0)
size++;
}
return size;
}
size_t size(T x)
{
return abs(_ufs[findRoot(x)]);
}
vector<T> getMembers(T x)
{
vector<T> members;
int root = findRoot(x);
for (const auto& pair : _mp)
{
if (findRoot(pair.first) == root)
members.push_back(pair.first);
}
return members;
}
private:
vector<int> _ufs;
map<T, int> _mp;
};
Graph.hpp:
#pragma once
#include <string>
#include <vector>
#include <queue>
#include <unordered_map>
#include <set>
#include "UnionFindSet.hpp"
using namespace std;
namespace matrix
{
// 顶点 边 最大权值 是否有向
template <typename V, typename W = int, W MAX_W = INT_MAX, bool direction = false>
class Graph
{
using self = Graph<V, W, MAX_W, direction>;
public:
Graph() = default;
Graph(const V* vertex, int n)
{
_vertexs.reserve(n);
_matrix.resize(n);
for (int i = 0; i < n; ++i)
{
_vertexs.push_back(vertex[i]);
_indexMap[vertex[i]] = i;
_matrix[i].resize(n, MAX_W);
}
}
Graph(const vector<V>& vertexs)
: _vertexs(vertexs)
{
int n = vertexs.size();
_matrix.resize(n);
for (int i = 0; i < n; i++)
{
_indexMap[vertexs[i]] = i;
_matrix[i].resize(n, MAX_W);
}
}
int getVertexIndex(const V& v)
{
return _indexMap.count(v) ? _indexMap[v] : -1;
}
void addEdge(const V& src, const V& dst, const W& weight)
{
int srcIndex = getVertexIndex(src);
int dstIndex = getVertexIndex(dst);
if (srcIndex == -1 || dstIndex == -1)
return;
_matrix[srcIndex][dstIndex] = weight;
if (!direction)
_matrix[dstIndex][srcIndex] = weight;
}
// --------------------- 遍历 ---------------------
// 深度优先
vector<V> DFS(const V& src)
{
vector<V> ret;
vector<bool> visited(_vertexs.size(), false);
int srci = getVertexIndex(src);
if (srci == -1)
return ret;
_DFS(srci, ret, visited);
return ret;
}
void _DFS(int srci, vector<V>& path, vector<bool>& visited)
{
visited[srci] = true;
path.push_back(_vertexs[srci]);
for (int i = 0; i < _vertexs.size(); i++)
{
if (!visited[i] && _matrix[srci][i] != MAX_W)
_DFS(i, path, visited);
}
}
// 广度优先
vector<V> BFS(const V& src)
{
vector<V> ret;
vector<bool> visited(_vertexs.size(), false);
queue<int> q;
int srci = getVertexIndex(src);
q.push(srci);
visited[srci] = true;
while (!q.empty())
{
int front = q.front();
q.pop();
for (int i = 0; i < _vertexs.size(); i++)
{
if (!visited[i] && _matrix[front][i] != MAX_W)
{
q.push(i);
visited[i] = true;
}
}
ret.push_back(_vertexs[front]);
}
return ret;
}
// --------------------- 最小生成树 ---------------------
struct Edge
{
int _srci;
int _dsti;
W _weight;
Edge(const int srci, const int dsti, const W& weight)
: _srci(srci)
, _dsti(dsti)
, _weight(weight)
{}
bool operator>(const Edge& e) const
{
return _weight > e._weight;
}
};
// kruskal算法
W kruskal(self& minTree)
{
int n = _vertexs.size();
minTree._vertexs = _vertexs;
minTree._indexMap = _indexMap;
minTree._matrix.resize(n);
for (int i = 0; i < n; i++)
minTree._matrix[i].resize(n, MAX_W);
priority_queue<Edge, vector<Edge>, greater<Edge>> minEdgeHeap;
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
if (i < j && _matrix[i][j] != MAX_W)
minEdgeHeap.emplace(i, j, _matrix[i][j]);
}
}
int sz = 0;
W total = W();
UnionFindSet<V> ufs(_vertexs);
while (!minEdgeHeap.empty() && sz < n - 1)
{
Edge minEdge = minEdgeHeap.top();
minEdgeHeap.pop();
V& src = _vertexs[minEdge._srci];
V& dst = _vertexs[minEdge._dsti];
W& weight = minEdge._weight;
if (!ufs.inSet(src, dst))
{
minTree.addEdge(src, dst, weight);
ufs.unionSet(src, dst);
total += weight;
sz++;
}
}
if (sz == n - 1)
return total;
else
return W();
}
// prim算法
W prim(self& minTree, const V& src)
{
int n = _vertexs.size();
minTree._vertexs = _vertexs;
minTree._indexMap = _indexMap;
minTree._matrix.resize(n);
for (int i = 0; i < n; i++)
minTree._matrix[i].resize(n, MAX_W);
int srci = getVertexIndex(src);
priority_queue<Edge, vector<Edge>, greater<Edge>> minEdgeHeap;
for (int i = 0; i < n; i++)
{
if (_matrix[srci][i] != MAX_W)
minEdgeHeap.emplace(srci, i, _matrix[srci][i]);
}
int sz = 0;
W total = W();
vector<bool> visited(n, false);
visited[srci] = true;
while (!minEdgeHeap.empty() && sz < n - 1)
{
Edge minEdge = minEdgeHeap.top();
minEdgeHeap.pop();
V& src = _vertexs[minEdge._srci];
V& dst = _vertexs[minEdge._dsti];
W& weight = minEdge._weight;
if (!visited[minEdge._dsti])
{
minTree.addEdge(src, dst, weight);
visited[minEdge._dsti] = true;
sz++;
total += weight;
for (int i = 0; i < n; i++)
{
if (_matrix[minEdge._dsti][i] != MAX_W && !visited[i])
minEdgeHeap.emplace(minEdge._dsti, i, _matrix[minEdge._dsti][i]);
}
}
}
if (sz == n - 1)
return total;
else
return W();
}
// --------------------- 最短路径 ---------------------
// dijkstra算法
void dijkstra(const V& src, vector<W>& distance, vector<int>& parentPath)
{
int n = _vertexs.size();
int srci = getVertexIndex(src);
distance.resize(n, MAX_W);
parentPath.resize(n, -1);
distance[srci] = W();
parentPath[srci] = srci;
vector<bool> visited(n, false);
for (int i = 0; i < n; i++)
{
W minDist = MAX_W;
int minIndex = -1;
for (int j = 0; j < n; j++)
{
if (!visited[j] && distance[j] < minDist)
{
minDist = distance[j];
minIndex = j;
}
}
visited[minIndex] = true;
// 松弛操作
for (int j = 0; j < n; j++)
{
if (!visited[j] && _matrix[minIndex][j] != MAX_W &&
distance[j] > minDist + _matrix[minIndex][j])
{
parentPath[j] = minIndex;
distance[j] = minDist + _matrix[minIndex][j];
}
}
}
}
// bellman-ford算法
bool bellmanFord(const V& src, vector<W>& distance, vector<int>& parentPath)
{
int n = _vertexs.size();
distance.resize(n, MAX_W);
parentPath.resize(n, -1);
int srci = getVertexIndex(src);
distance[srci] = W();
parentPath[srci] = srci;
int k = n;
bool flag = true;
while(k-- && flag)
{
flag = false;
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
// src -> i - > j 是否更短?
if (distance[i] != MAX_W && _matrix[i][j] != MAX_W
&& distance[j] > distance[i] + _matrix[i][j])
{
flag = true;
parentPath[j] = i;
distance[j] = distance[i] + _matrix[i][j];
}
}
}
if (!flag) break;
}
// 负权回路
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++)
{
// src -> i - > j 是否更短?
if (distance[i] != MAX_W && _matrix[i][j] != MAX_W
&& distance[j] > distance[i] + _matrix[i][j])
{
return false;
}
}
}
return true;
}
// FloydWarshall算法
void FloydWarshall(vector<vector<W>>& distance, vector<vector<int>>& parentPath)
{
int n = _vertexs.size();
// 初始化容积
distance.resize(n);
parentPath.resize(n);
for (int i = 0; i < n; i++)
{
distance[i].resize(n, MAX_W);
parentPath[i].resize(n, -1);
}
// 初始化直接相邻路径
for (int i = 0; i < n; i++)
{
parentPath[i][i] = i;
distance[i][i] = W();
for (int j = 0; j < n; j++)
{
if (_matrix[i][j] != MAX_W)
{
parentPath[i][j] = i;
distance[i][j] = _matrix[i][j];
}
}
}
// 动态规划
for (int k = 0; k < n; k++) // 中间插入第n个节点
{
for (int i = 0; i < n; i++)
{
for (int j = 0; j < n; j++) // 到k为止,i -> j 的最短路径
{
if (distance[i][k] != MAX_W && distance[k][j] != MAX_W
&& distance[i][j] > distance[i][k] + distance[k][j])
{
parentPath[i][j] = parentPath[k][j];
distance[i][j] = distance[i][k] + distance[k][j];
}
}
}
}
}
void print()
{
for (int i = 0; i < _vertexs.size(); i++)
cout << "[" << i << "]:" << _vertexs[i] << endl;
printf("\n ");
for (int i = 0; i < _vertexs.size(); i++)
printf("%4d", i);
printf("\n");
for (int i = 0; i < _vertexs.size(); i++)
{
printf("%d", i);
for (int j = 0; j < _vertexs.size(); j++)
{
if (_matrix[i][j] == INT_MAX)
printf("%4c", '*');
else
printf("%4d", _matrix[i][j]);
}
printf("\n");
}
}
void prinrtShotPath(const V& src, const vector<W>& dist, const vector<int>& parentPath)
{
size_t n = _vertexs.size();
size_t srci = getVertexIndex(src);
cout << "从 " << src << "出发的最短路径: " << endl;
for (size_t i = 0; i < n; ++i)
{
if (i == srci)
continue;
vector<int> path;
int parenti = i;
while (parenti != srci)
{
path.push_back(parenti);
parenti = parentPath[parenti];
}
path.push_back(srci);
reverse(path.begin(), path.end());
cout << "最短距离: " << dist[i] << " 最短路径: ";
for (auto pos : path)
{
cout << _vertexs[pos] << "->";
}
cout << "\b\b " << endl;
}
}
private:
vector<V> _vertexs; // 节点
unordered_map<V, int> _indexMap; // 节点->下标 映射
vector<vector<W>> _matrix; // 邻接矩阵
};
}
-test.cpp:
#include <iostream>
#include "Graph.hpp"
using namespace matrix;
void testGraph()
{
vector<string> v{ "张三", "李四", "王五", "赵六", "孙七" };
Graph<string, int, INT_MAX, true> g(v);
g.addEdge("张三", "李四", 1);
g.addEdge("张三", "王五", 1);
g.addEdge("李四", "赵六", 1);
g.addEdge("李四", "孙七", 1);
cout << "--------------------------------------------" << endl;
cout << "DFS:" << endl;
vector<string> dfs = g.DFS("张三");
for (auto& str : dfs)
cout << str << " ";
cout << endl;
cout << "BFS:" << endl;
vector<vector<string>> bfs = g._BFS("张三");
for (auto& vct : bfs)
{
for (auto& str : vct)
cout << str << " ";
cout << endl;
}
}
void TestKruskalAndPrim()
{
cout << "--------------------------------------------" << endl;
const char* str = "abcdefghi";
Graph<char, int> g(str, strlen(str));
g.addEdge('a', 'b', 4);
g.addEdge('a', 'h', 8);
// g.addEdge('a', 'h', 9);
g.addEdge('b', 'c', 8);
g.addEdge('b', 'h', 11);
g.addEdge('c', 'i', 2);
g.addEdge('c', 'f', 4);
g.addEdge('c', 'd', 7);
g.addEdge('d', 'f', 14);
g.addEdge('d', 'e', 9);
g.addEdge('e', 'f', 10);
g.addEdge('f', 'g', 2);
g.addEdge('g', 'h', 1);
g.addEdge('g', 'i', 6);
g.addEdge('h', 'i', 7);
Graph<char, int> kminTree;
cout << "Kruskal:" << endl;
cout << "总权值:" << g.kruskal(kminTree) << endl;
cout << "最小生成树:" << endl;
kminTree.print();
cout << endl;
cout << "--------------------------------------------" << endl;
Graph<char, int> pminTree;
cout << "Prim:" << endl;
cout << "总权值:" << g.prim(pminTree, 'a') << endl;
cout << "最小生成树:" << endl;
pminTree.print();
cout << endl;
}
void TestGraphDijkstra()
{
cout << "--------------------------------------------" << endl;
const char* str = "syztx";
Graph<char, int, INT_MAX, true> g(str, strlen(str));
g.addEdge('s', 't', 10);
g.addEdge('s', 'y', 5);
g.addEdge('y', 't', 3);
g.addEdge('y', 'x', 9);
g.addEdge('y', 'z', 2);
g.addEdge('z', 's', 7);
g.addEdge('z', 'x', 6);
g.addEdge('t', 'y', 2);
g.addEdge('t', 'x', 1);
g.addEdge('x', 'z', 4);
vector<int> dist;
vector<int> parentPath;
g.dijkstra('s', dist, parentPath);
cout << "Dijkstra: " << endl;
g.prinrtShotPath('s', dist, parentPath);
}
void TestGraphBellmanFord()
{
cout << "--------------------------------------------" << endl;
{
cout << "BellmanFord:不带负权回路 " << endl;
const char* str = "syztx";
Graph<char, int, INT_MAX, true> g(str, strlen(str));
g.addEdge('s', 't', 6);
g.addEdge('s', 'y', 7);
g.addEdge('y', 'z', 9);
g.addEdge('y', 'x', -3);
g.addEdge('z', 's', 2);
g.addEdge('z', 'x', 7);
g.addEdge('t', 'x', 5);
g.addEdge('t', 'y', 8);
g.addEdge('t', 'z', -4);
g.addEdge('x', 't', -2);
vector<int> dist;
vector<int> parentPath;
g.bellmanFord('s', dist, parentPath);
if (g.bellmanFord('s', dist, parentPath))
g.prinrtShotPath('s', dist, parentPath);
else
cout << "存在负权回路" << endl;
}
{
cout << "BellmanFord:带负权回路 " << endl;
//微调图结构,带有负权回路的测试
const char* str = "syztx";
Graph<char, int, INT_MAX, true> g(str, strlen(str));
g.addEdge('s', 't', 6);
g.addEdge('s', 'y', 7);
g.addEdge('y', 'x', -3);
g.addEdge('y', 'z', 9);
g.addEdge('y', 'x', -3);
g.addEdge('y', 's', 1); // 新增
g.addEdge('z', 's', 2);
g.addEdge('z', 'x', 7);
g.addEdge('t', 'x', 5);
g.addEdge('t', 'y', -8); // 更改
g.addEdge('t', 'z', -4);
g.addEdge('x', 't', -2);
vector<int> dist;
vector<int> parentPath;
if (g.bellmanFord('s', dist, parentPath))
g.prinrtShotPath('s', dist, parentPath);
else
cout << "存在负权回路" << endl;
}
}
void TestFloydWarShall()
{
cout << "--------------------------------------------" << endl;
cout << "FloydWarShall: " << endl;
const char* str = "12345";
Graph<char, int, INT_MAX, true> g(str, strlen(str));
g.addEdge('1', '2', 3);
g.addEdge('1', '3', 8);
g.addEdge('1', '5', -4);
g.addEdge('2', '4', 1);
g.addEdge('2', '5', 7);
g.addEdge('3', '2', 4);
g.addEdge('4', '1', 2);
g.addEdge('4', '3', -5);
g.addEdge('5', '4', 6);
vector<vector<int>> vvDist;
vector<vector<int>> vvParentPath;
g.FloydWarshall(vvDist, vvParentPath);
// 打印任意两点之间的最短路径
for (size_t i = 0; i < strlen(str); ++i)
{
g.prinrtShotPath(str[i], vvDist[i], vvParentPath[i]);
cout << endl;
}
}
int main()
{
testGraph();
TestKruskalAndPrim();
TestGraphDijkstra();
TestGraphBellmanFord();
TestFloydWarShall();
return 0;
}
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 数据结构:图

发表评论 取消回复