1 介绍
本文使用数据集,对三个模型进行了对比,代码使用python完成,通过对比,发现lstm>gru>informer.
2 数据读取
使用降水量数据集,第一列表示降水,第二列表示出水量。
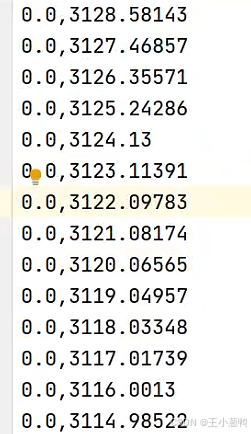
- 输入是两个特征
- 输出是一个特征
- 输入是多时间步,例如,用1-12做输入。
- 输出也是多时间步,例如,预测13-18时间段。
lstm和gru的数据读取代码是一样的,如下所示:
class MyDatasetLstm(Dataset):
def __init__(self, df, seq_len=96, pred_len=24):
self.seq_len = seq_len
self.pred_len = pred_len
self.__read_data__(df=df)
def __read_data__(self, df):
self.data_x = df
self.data_y = df[:,-1]
def __getitem__(self, index):
s_begin = index
s_end = s_begin + self.seq_len
r_begin = s_end
r_end = r_begin + self.pred_len
seq_x = self.data_x[s_begin:s_end]
seq_y = self.data_y[r_begin:r_end]
return seq_x, seq_y
def __len__(self):
return len(self.data_x) - self.seq_len - self.pred_len + 1
但是informer的数据读取不一样,因为加入了label维度,所以代码如下所示:
class MyDatasetInformer(Dataset):
def __init__(self, df, seq_len=96, label_len=48, pred_len=24):
self.seq_len = seq_len
self.label_len = label_len
self.pred_len = pred_len
self.__read_data__(df=df)
def __read_data__(self, df):
self.data_x = df
self.data_y = df
def __getitem__(self, index):
s_begin = index
s_end = s_begin + self.seq_len
r_begin = s_end - self.label_len
r_end = r_begin + self.label_len + self.pred_len
seq_x = self.data_x[s_begin:s_end]
seq_y = self.data_y[r_begin:r_end]
return seq_x, seq_y
def __len__(self):
return len(self.data_x) - self.seq_len - self.pred_len + 1
3 搭建模型
这一块主要参考了github上的代码,做了些修改,因为原来的informer有timebedding这个维度,但是我们的数据没有这个维度,所以把这个去掉就行,剩下的就是encoder和decoder,然后再拼接。
lstm和gru就用很简单的搭建方式就行,torch自带的,很容易。
4 训练和预测
训练和预测时,informer就是因为多了个label,所以读取方式有点不一样,代码如下所示,并且再测试时,要取label之后的,才是真正的预测值。
if model_name == "informer":
# Informer训练方式
batch_x = batch_x.float().to(device)
batch_y = batch_y.float()
dec_inp = torch.zeros([batch_y.shape[0], pred_len, batch_y.shape[-1]]).float()
dec_inp = torch.cat([batch_y[:, :label_len, :], dec_inp], dim=1).float().to(device)
pred = model(batch_x, dec_inp)
pred = pred[:, -pred_len:, :].to(device)
true = batch_y[:, -pred_len:, :].to(device)
loss = criterion(pred, true)
else:
# lstm \ gru 训练方式
batch_x = batch_x.float().to(device)
batch_y = batch_y.float().to(device)
pred = model(batch_x)
loss = criterion(pred, batch_y)
# 如有需要,添加qq 964083210
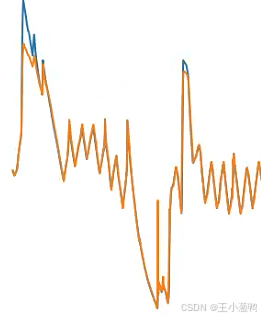
5 结果对比
还有mse、rmse、r2等指标,还有多种预测方式。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » lstm和informer和gru模型对比

发表评论 取消回复