B树
| 种类 | 时间复杂度 |
|---|---|
| 顺序查找 | O ( N ) O(N) O(N) |
| 二分查找 | O ( log 2 N ) O(\log_{2}{N} ) O(log2N) |
| 二叉平衡搜索树 | O ( log 2 N ) O(\log_{2}{N} ) O(log2N) |
| 哈希 | O ( 1 ) O(1) O(1) |
以上是常见的搜索结构,当时间复杂度进化到 O ( log 2 N ) O(\log_{2}{N}) O(log2N) 和 O ( 1 ) O(1) O(1),已经是非常高效的查找了,但是它们不太适合外查找,也就是当把数据存储在硬盘上。
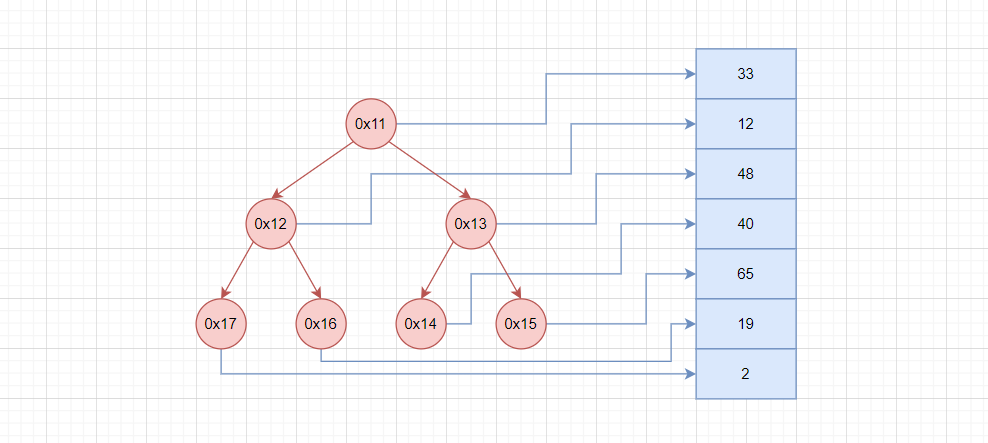
如果把数据存储在磁盘上,假设使用二叉平衡搜索树,每个节点存储硬件地址。此时进行搜索,每次到达一个节点,都要通过地址,把数据读出来进行比较,那么想要查询到数据,最多就会进行树高度次IO,也就是 log 2 N \log_{2}{N} log2N 次IO。
对于内存中的数据,进行 log 2 N \log_{2}{N} log2N 次计算,是非常高效的。但是进行 log 2 N \log_{2}{N} log2N 次IO,这就是很低效的。
如果使用哈希表,由于哈希冲突存在,复杂度会退化到 O ( N ) O(N) O(N),因此这些数据结构都不适合进行外查找。
如果想要提高外查找的效率,那么就要做到以下两点:
- 降低树高度,减少IO次数
- 让每个节点存储更多的值,一次IO可以读取更多的数据
基于以上两个特点,就产生了B树。
结构
B树是一个多路平衡搜索树,为了提高每个节点存储的数据数量,每个节点都会维护两个数组。
- 关键字数组
keys - 子节点数组
child
如图:
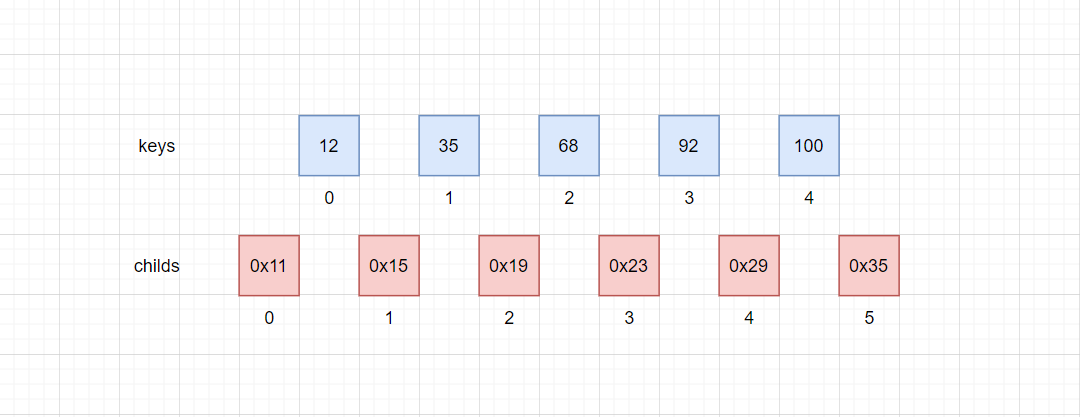
childs比keys多一个元素,在keys内存储元素,在childs存储指向子节点的指针。当查询时,遍历keys数组,如果找到相等的元素直接返回,如果没有找到相等的元素,那么去子节点找。
childs[i]之前的元素,存储的是小于keys[i]的元素,而childs[i+1]之后的元素,存储的是大于keys[i]的元素。比如说childs[1] = 0x16,这个地址指向的子节点,存储的元素值就介于(12, 35)。
查询70,其介于68与92之间,说明该元素存储在childs[3] = 0x23地址处,此时去读取地址拿到节点,然后重复查询过程。
如果查询元素小于keys[0]最小值,那么就去child[0]查找,如果大于keys[4]最大值,那么就去childs[5]查找。
也就是说,keys数组起到存储元素和索引节点两个作用。
当检测出被查询的元素介于某两个key之间,那么就通过childs找到节点,然后再在节点中查找目标值。
对于一颗M路的B树,满足以下特性:
- 该树可以是一颗空树
- 只在叶子节点插入新数据
- 分支节点的关键字个数在
[M/2, M - 1]之间,孩子比关键字多一个 - 每个节点中的关键字从小到大排列,对子节点进行值域划分
- 叶子节点的关键字个数在
[M/2, M - 1]之间,所有孩子都是空指针 - 所有叶子节点都在同一层,是一颗完全多叉树
以上规则,是基于分裂节点操作实现的。
分裂节点
为了方便讲解,现在将keys与childs表示如下:
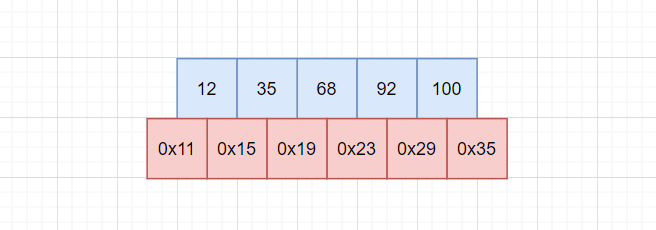
蓝色数组为keys,红色数组为childs,因为keys是对childs的值域进行划分,上图中每个蓝色元素相邻的两个红色元素,刚好是比当前key大和比当前key小的两个子节点。由于childs比keys多一个,形成错位关系。
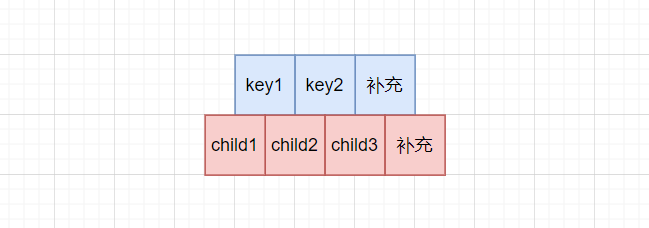
假设现有一棵M=3的B树,那么其最多有M-1 = 2个key,3个child。为了方便编程,常常会额外给keys和childs多开一个空间,如下:
先插入53和139:
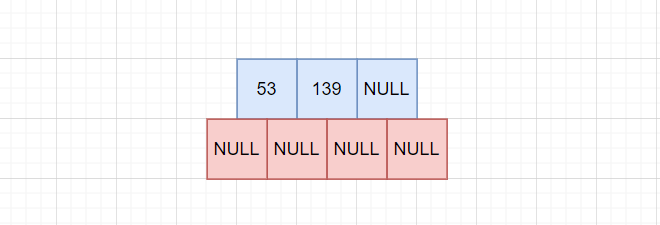
由于当前只有两个数据,根节点也是叶子节点,所有chidl都是NULL。
插入75:
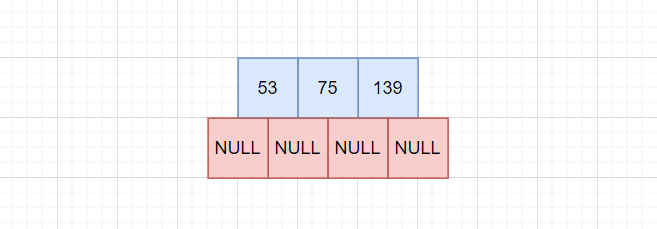
此时该节点共有三个key,超出了指定数目,要进行节点分裂:
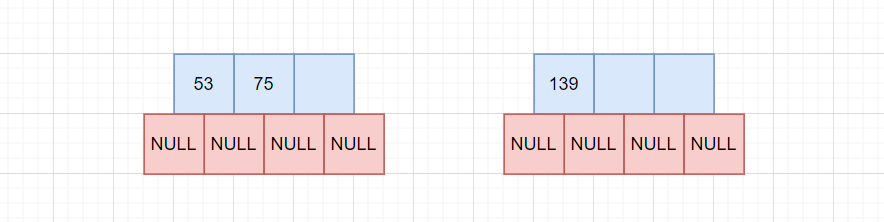
创建一个新的兄弟节点,将[M/2 + 1, M]的数据全部拷贝给兄弟节点。
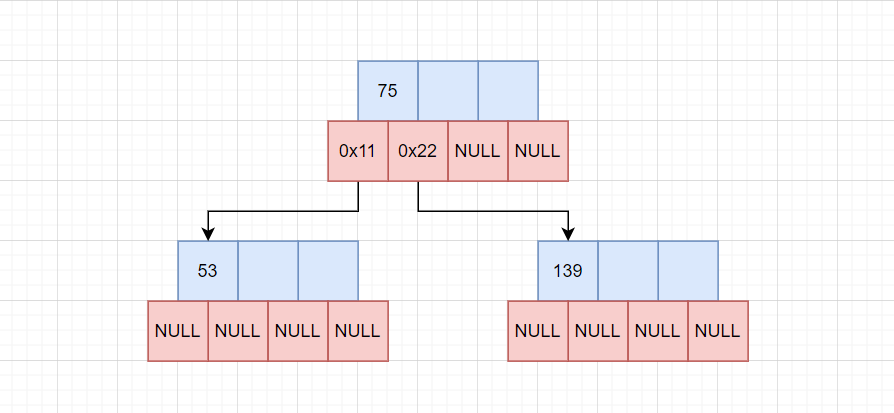
将[M/2]中间节点交给父亲节点,如果父节点不存在,此时创建新的父节点。
此处由于原先不存在父节点,所以创建了一个父节点,将中间数据75交给父节点。
这样就构成了初步的索引关系,大于75的值去0x22地址查询,小于75的值去0x11地址查询。
插入49和145:
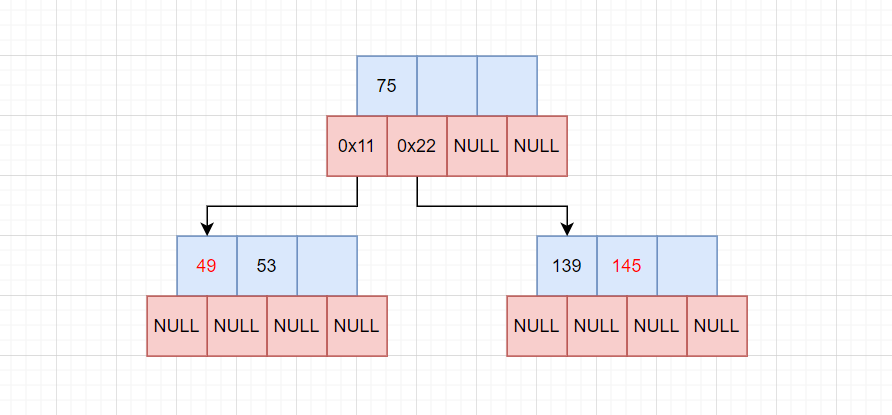
此时再插入新数据,就必须往叶子节点插入,比如49不能插在75前面,而是要插在75的左子树。145比75大,插入75的右子树。
插入36:
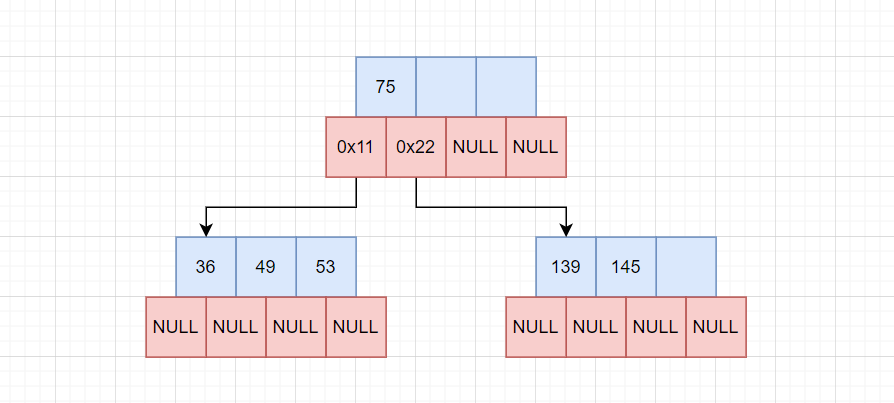
36 < 73,插入0x11节点,此时0x11节点满了,再次进行分裂:
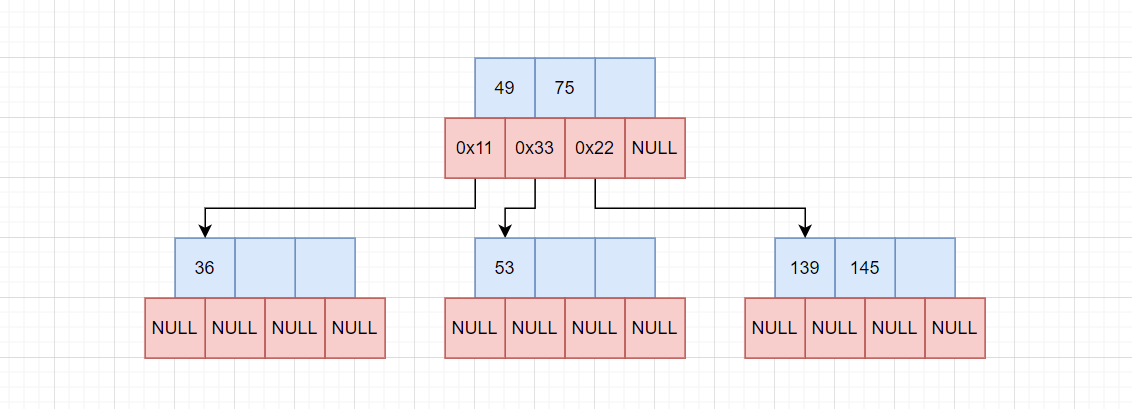
将53拷贝给兄弟节点,将中间值49交给父节点。此处注意,父节点的childs也要一起改变,因为49加入后,新增了一个值域(49, 75),这段值域由新节点0x33维护,要插入到childs数组中。
插入101:
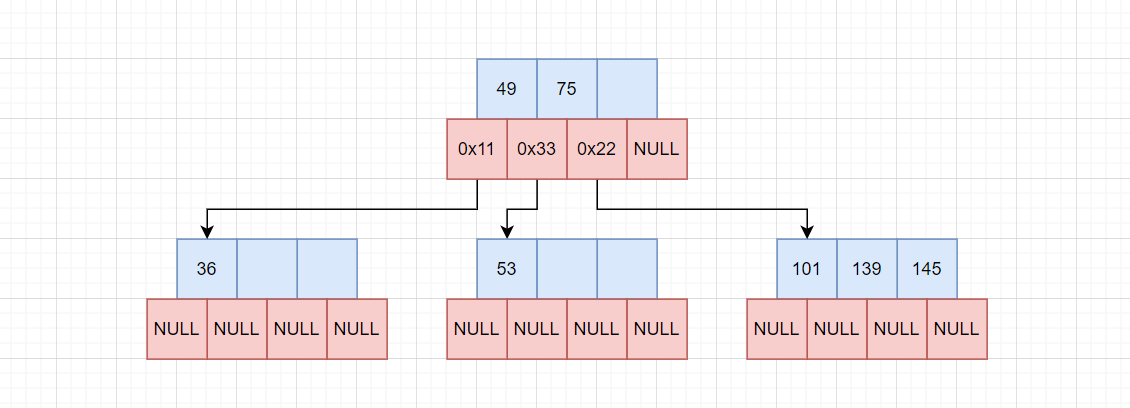
插入后0x22节点满了,再次执行分裂节点:
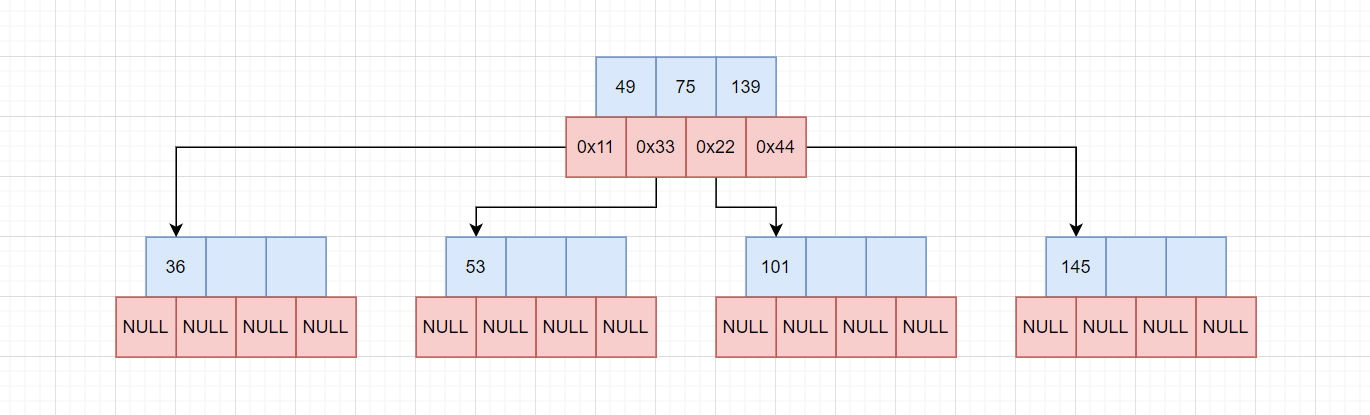
分裂节点后,由于139交给父节点,导致父节点也满了,此时要进行再次分裂节点:
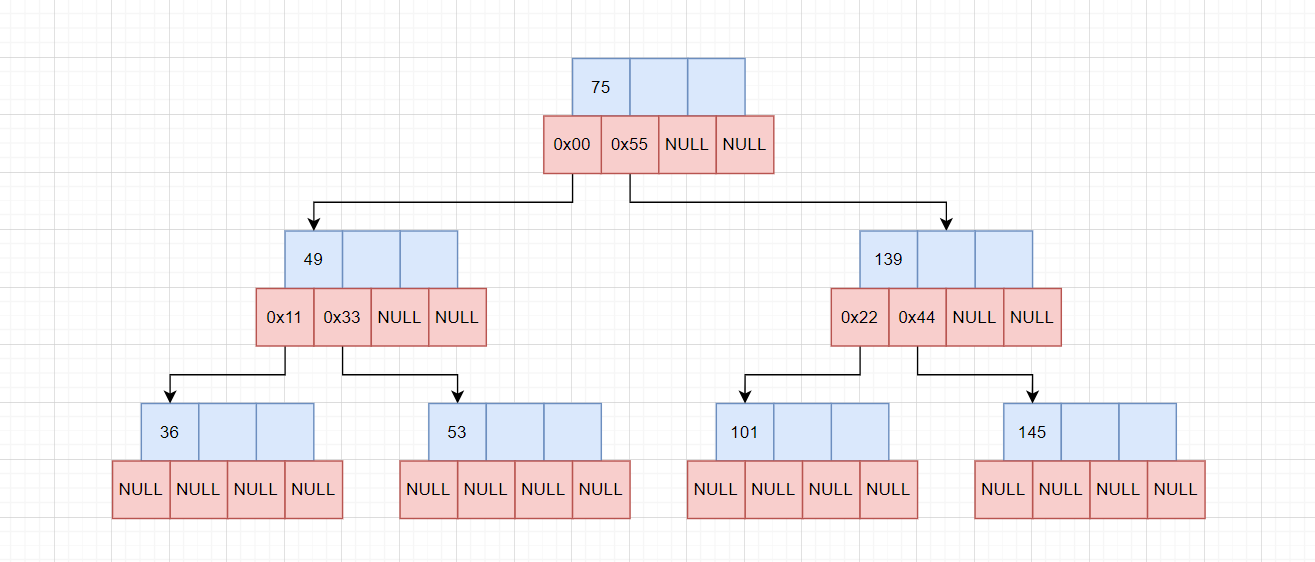
将139拷贝给兄弟节点0x55,将中间值75拷贝给父节点,由于父节点不存在,创建新的父节点。
至此,应该可以理解B树的实现原理了,每次都往叶子节点插入最新的数据。等到节点数据满时,分裂节点,将数据划分为三份,自己留M/2,给兄弟M/2,中间值给父节点,用于划分自己与兄弟节点的值域。因为刚好留下一半,新的兄弟节点也拿到一半,可以保证每个节点的数据范围都在[M/2, M-1]之间。
实现
接下来讲解以C++实现的B树。
BTree类架构
- 节点类:
template <typename K, size_t M>
struct BTreeNode
{
size_t _sz;
BTreeNode<K, M>* _parent;
vector<K> _keys;
vector<BTreeNode<K, M>*> _childs;
BTreeNode()
: _sz(0)
, _parent(nullptr)
, _keys(M, K())
, _childs(M + 1, nullptr)
{}
};
模板参数:
K:存储的元素类型M:B树的阶数
类成员:
-
_sz:当前B树存储key的个数 -
_parent:指向父节点的指针 -
_keys:存储元素的数组 -
_childs:存储指向子元素指针的数组 -
B树类:
template <typename K, size_t M>
class BTree
{
using Node = BTreeNode<K, M>;
private:
Node* _root;
};
在BTree中,将节点类型重命名为Node,存放一个根节点_root。
查找节点
首先实现节点的查找,因为后续插入节点时,也需要先先查找节点是否存在,要调用这个函数。
查找70:
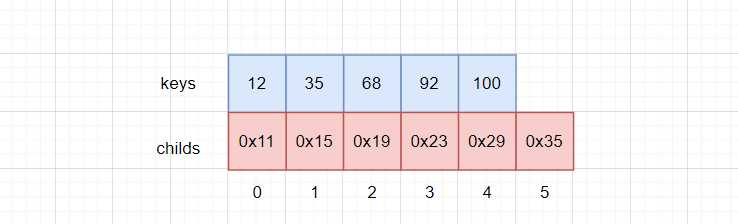
查找的过程中,遍历keys数组:
keys[i] < 70:i++往后查找keys[i] = 70:找到了,返回keys[i] > 70:说明keys[i - 1] < 70并且keys[i] > 70,此时70应该在这两个的值域内部,进入节点childs[i]
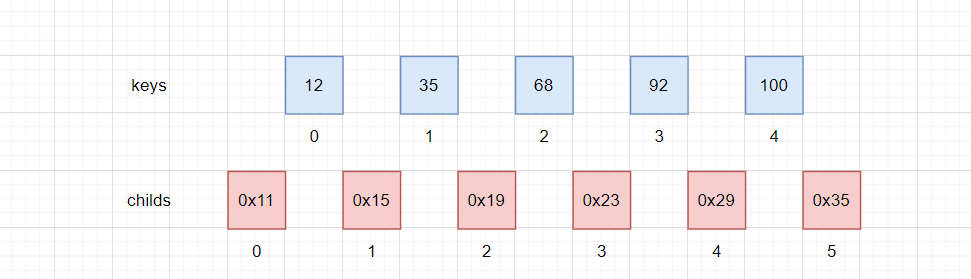
此处注意keys与childs之间的下标关系,对于keys[i],小于该元素的值域是childs[i],大于该元素的值域是childs[i + 1]。
可以通过这张错位版本的图理解:
函数声明:
pair<Node*, int> find(const K& key)
函数接收一个key,返回值是一个pair<Node*, int>,其中Node*是key所在的节点的指针,int表示key是该节点的第几个元素。
如果没有找到,那么返回值中int = -1表示不存在,Node*返回应该插入的位置。如果查找一个节点时,没有找到元素,那么一定查找到了叶子节点,这个叶子节点就是经过计算后,key应该所处的值域。此时把这个叶子节点的指针返回回来,方便后续插入这个key。
初始化:
Node* cur = _root;
Node* parent = nullptr;
定义cur指针,指向当前正在遍历的节点,parent是指向cur的父节点的指针。如果最后key不存在,那么cur = nullptr,此时cur->_parent会报错,所以要用一个额外的变量记录父节点。
while (cur)
{
int i;
for (i = 0; i < cur->_sz; i++)
{
if (key < cur->_keys[i])
break;
else if (key == cur->_keys[i])
return { cur, i };
}
parent = cur;
cur = cur->_childs[i];
}
return { parent, -1 };
在循环判断中,while(cur)只要cur为空指针,就说明没有找到key,跳出循环返回{ parent, -1 }表示是没找到。
循环体内部,每次for循环整个keys数组,如果找到和key一样的元素,那么返回{ cur, i }。如果key < cur->_keys[i],说明找到了key所处的值域,直接break出来,cur = cur->_childs[i]进入子节点进行查找。
另外的,如果遍历完整个keys都没有找到key,说明key大于这里的所有值,那么进入childs的最后一个子节点。
插入排序
当已知要插入的节点,以及要插入的值,那么此时要通过插入排序,将目标值插入到合适的位置。
但是插入并不是简单的对key排序即可,key要带着自己的右子树一起排序。为什么是右子树?看一个案例:
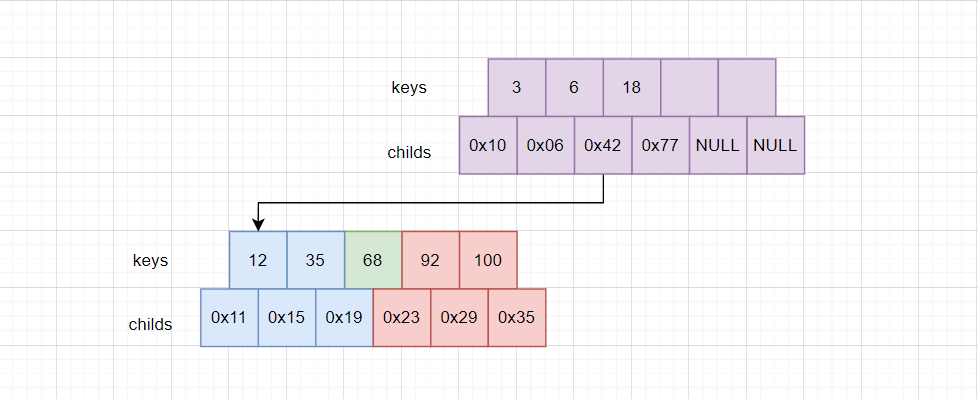
此处0x42节点满了,要进行分裂,分裂成蓝色、绿色、红色三部分。
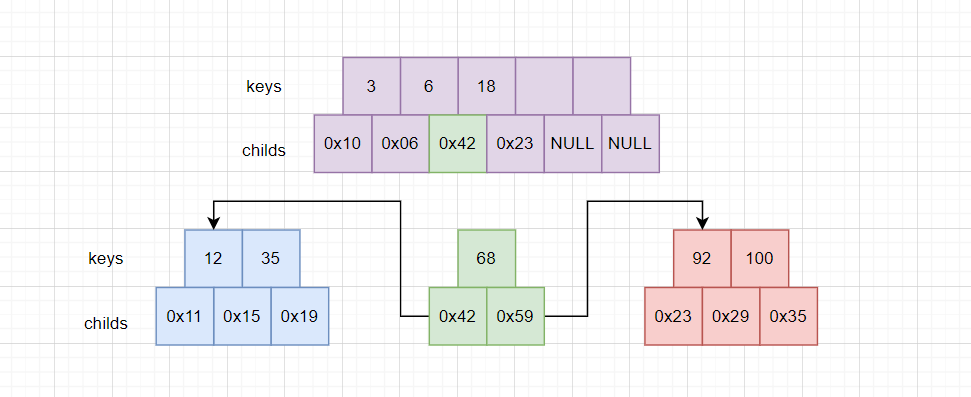
绿色的部分要维护左右子树的指针关系,左右指针分别指向左右子树。但是由于蓝色区域是原先就存在的节点,所以父节点中本身就有指向蓝色节点的指针(绿色部分0x42),绿色节点只需要带上新创建的右子树即可。
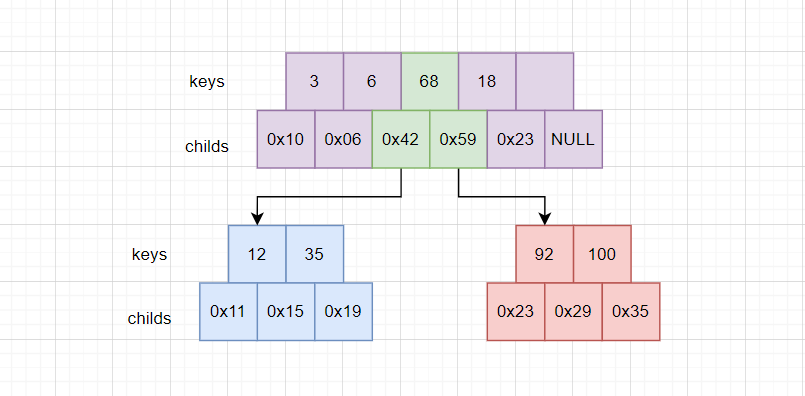
随后68带上指向右子树的0x59指针,进行插入排序,成功插入到父节点中。
这个过程你会发现,新的key被插入到下标为i的位置,那么新节点指针就被插入到i+1的位置。
函数声明:
void insertSort(Node* node, Node* child, const K& key)
node:在该节点进行插入操作key:要插入的值child:key的右子树指针
插入排序:
int end = node->_sz - 1;
while (end >= 0)
{
if (key < node->_keys[end])
{
node->_keys[end + 1] = node->_keys[end];
node->_childs[end + 2] = node->_childs[end + 1];
end--;
}
else
{
break;
}
}
node->_keys[end + 1] = key;
node->_childs[end + 2] = child;
if (child)
child->_parent = node;
node->_sz++;
从keys的末尾开始遍历,找到第一个比自己小的元素,就在该位置插入。
node->_keys[end + 1] = node->_keys[end]:将keys的元素向后移动一个位置,腾出位置进行插入node->_childs[end + 2] = node->_childs[end + 1]:将child的元素向后移动一个位置,腾出位置进行插入,注意此处下标比keys的下标后一个位置,也就是end+2
当循环结束,end+1就是key的插入位置,end+2是child的插入位置。如果child不是空指针,那么child->_parent = node。
最后node节点存储的值多一个,那么node->_sz++。
插入
有了前面的铺垫,此时才能进行插入元素的操作。
插入逻辑如下:
- 如果树为空,构造一个新的
root节点 - 树不为空,通过
find查找key是否存在- 如果存在,直接返回
false表示插入失败 - 如果不存在,开始插入
- 如果存在,直接返回
- 通过
insertSort,将元素插入到节点中 - 判断插入后节点是否满了
- 没满:返回
true,插入成功 - 满了:进行分裂操作
- 没满:返回
- 开始分裂操作
- 创建兄弟节点
- 拷贝
[M/2 + 1, M-1]元素给兄弟节点 - 重复第三步,将
[M/2]元素插入到父节点,判断父节点是否满了…
函数声明:
bool insert(const K& key)
参数key为要插入的值,返回值bool表示是否插入成功。
树为空:
if (_root == nullptr)
{
_root = new Node; // 构造新节点
_root->_keys[0] = key; // 插入key
_root->_sz = 1; // 当前_root有一个元素
return true;
}
如果树为空,直接构造一个节点给_root,并且直接把key插入到新节点。
树不为空,判断key是否已经存在:
pair<Node*, int> exist = find(key);
if (exist.second != -1)
return false; // key 已经存在
之前写find函数时说过,如果返回值为-1表示不存在,如果exist.second != -1直接返回false。
初始化插入节点:
K newKey = key; // 要插入的key
Node* child = nullptr; // 要插入key的右子树
Node* node = exist.first; // 在该节点进行插入
因为后面要循环更新,此处将这三个值存储在新的变量里面。
插入节点:
while (true)
{
insertSort(node, child, newKey); // 向node插入key和它的右子树child
if (node->_sz < M) // 无需分裂
break;
// 分裂节点...
// 更新...
}
首先调用insertSort(node, child, newKey)完成插入操作,随后判断插入后node是否满了,如果没满直接退出,如果满了进行分裂。
分裂节点:
while (true)
{
// 插入节点...
// 分裂节点
Node* brother = new Node; // 创建兄弟节点
int mid = M / 2; // 中间元素
int j = 0;
for (int i = mid + 1; i < M; i++) // 把 [mid + 1, M - 1]拷贝给兄弟节点
{
brother->_keys[j] = node->_keys[i]; // 拷贝key
brother->_childs[j] = node->_childs[i]; // 拷贝child
if (brother->_childs[j])
brother->_childs[j]->_parent = brother; // 如果child不为空,更改child的父节点
j++;
}
brother->_childs[j] = node->_childs[M]; // 插入最后一个child
if (brother->_childs[j])
brother->_childs[j]->_parent = brother;
brother->_sz = j; // 兄弟节点获得到的元素数量
node->_sz = mid; // [0, mid - 1] 是node的剩余元素,共 mid 个
// 更新...
}
分裂节点时,先创建一个兄弟节点brother,记录中间元素下标mid。
随后通过for循环,把 [mid + 1, M - 1]的元素拷贝给兄弟节点,此处注意要同时拷贝keys和childs,并且拷贝完child,还要更新child的父亲节点为brother。
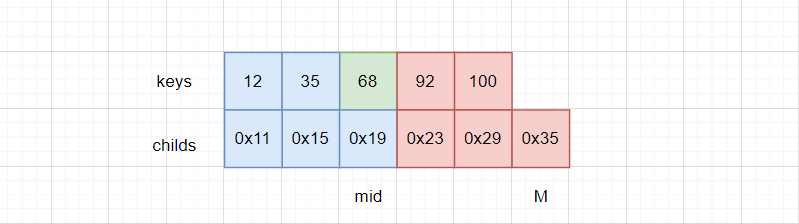
看这张图,可以看到,由于keys比childs少一个元素,所以下标只到M-1,还要进行一次额外的childs[M]的拷贝。
brother->_childs[j] = node->_childs[M]; // 插入最后一个child
if (brother->_childs[j])
brother->_childs[j]->_parent = brother;
也就是说这一段代码是在处理最后一段边界child。
最后更新node和brother的剩余元素数量。
当分裂完成后,最后一步就是把mid节点以及它的右子树插入到父节点中,插入父节点后,又要考虑节点是否已满,然后进行分裂操作。
此处的策略是,更新newKey、node、child三个变量的值,让它们进入下一轮循环,完成插入,分裂等操作。
更新值:
while (true)
{
// 插入节点...
// 分裂节点...
if (node == _root) // 当前节点是根节点
{
_root = new Node; // 创建新的根节点
_root->_keys[0] = node->_keys[mid]; // 根节点插入mid
_root->_childs[0] = node; // 左子树为node
_root->_childs[1] = brother; // 右子树为 brother
_root->_sz = 1; // 更新元素个数
brother->_parent = _root; // 更新brother的父节点指针
node->_parent = _root; // 更新node的父节点指针
break;
}
else
{
newKey = node->_keys[mid];
child = brother;
node = node->_parent;
}
}
return true;
首先,如果当前节点node已经是_root根节点了,那么它没有父节点,此时直接创建一个新的根节点,然后将mid插入到新根中。
如果当前节点还有父节点,那么 newKey = node->_keys[mid],child = brother,node = node->_parent,其实这三个值,就是while循环最开头调用的insertSort函数的三个参数。下一轮循环向 node->_parent节点中插入node->_keys[mid]以及右子树brother。
遍历
与二叉搜索树一样,B树的中序遍历也可以得到有序的数据,代码如下:
void _inOrder(Node* root, vector<K>& ret)
{
if (root == nullptr)
return;
for (size_t i = 0; i < root->_sz; i++)
{
_inOrder(root->_childs[i], ret);
ret.push_back(root->_keys[i]);
}
_inOrder(root->_childs[root->_sz], ret); // 遍历最后一个子节点
}
vector<K> inOrder()
{
vector<K> ret;
_inOrder(_root, ret);
return ret;
}
析构
析构函数的思路,与中序遍历完全一致:
void delBTree(Node* root)
{
for (int i = 0; i <= root->_sz; i++)
{
if (root->_childs[i] != nullptr)
delBTree(root->_childs[i]);
}
delete root;
}
~BTree()
{
delBTree(_root);
}
总代码
BTree.hpp:
#include <vector>
using namespace std;
template <typename K, size_t M>
struct BTreeNode
{
size_t _sz;
BTreeNode<K, M>* _parent;
vector<K> _keys;
vector<BTreeNode<K, M>*> _childs;
BTreeNode()
: _sz(0)
, _parent(nullptr)
, _keys(M, K())
, _childs(M + 1, nullptr)
{}
};
template <typename K, size_t M>
class BTree
{
using Node = BTreeNode<K, M>;
public:
pair<Node*, int> find(const K& key)
{
Node* cur = _root;
Node* parent = nullptr;
while (cur)
{
int i;
for (i = 0; i < cur->_sz; i++)
{
if (key < cur->_keys[i])
break;
else if (key == cur->_keys[i])
return { cur, i };
}
parent = cur;
cur = cur->_childs[i];
}
return { parent, -1 };
}
void insertSort(Node* node, Node* child, const K& key)
{
int end = node->_sz - 1;
while (end >= 0)
{
if (key < node->_keys[end])
{
node->_keys[end + 1] = node->_keys[end];
node->_childs[end + 2] = node->_childs[end + 1];
end--;
}
else
{
break;
}
}
node->_keys[end + 1] = key;
node->_childs[end + 2] = child;
if (child)
child->_parent = node;
node->_sz++;
}
bool insert(const K& key)
{
if (_root == nullptr)
{
_root = new Node;
_root->_keys[0] = key;
_root->_sz = 1;
return true;
}
pair<Node*, int> exist = find(key);
if (exist.second != -1)
return false; // key 已经存在
K newKey = key;
Node* child = nullptr;
Node* node = exist.first;
while (true)
{
insertSort(node, child, newKey);
if (node->_sz < M) // 无需分裂
break;
// 分裂节点
Node* brother = new Node;
int mid = M / 2;
// [0, mid - 1] [mid] [mid + 1, M - 1]
// node parent brother
int j = 0;
for (int i = mid + 1; i < M; i++)
{
brother->_keys[j] = node->_keys[i];
brother->_childs[j] = node->_childs[i];
if (brother->_childs[j])
brother->_childs[j]->_parent = brother;
j++;
}
brother->_childs[j] = node->_childs[M];
if (brother->_childs[j])
brother->_childs[j]->_parent = brother;
brother->_sz = j;
node->_sz = mid; // [0, mid - 1] 有 mid 个数据
if (node == _root)
{
_root = new Node;
_root->_keys[0] = node->_keys[mid];
_root->_childs[0] = node;
_root->_childs[1] = brother;
_root->_sz = 1;
brother->_parent = _root;
node->_parent = _root;
break;
}
else
{
newKey = node->_keys[mid];
child = brother;
node = node->_parent;
}
}
return true;
}
void _inOrder(Node* root, vector<K>& ret)
{
if (root == nullptr)
return;
for (size_t i = 0; i < root->_sz; i++)
{
_inOrder(root->_childs[i], ret);
ret.push_back(root->_keys[i]);
}
_inOrder(root->_childs[root->_sz], ret);
}
vector<K> inOrder()
{
vector<K> ret;
_inOrder(_root, ret);
return ret;
}
void delBTree(Node* root)
{
for (int i = 0; i <= root->_sz; i++)
{
if (root->_childs[i] != nullptr)
delBTree(root->_childs[i]);
}
delete root;
}
~BTree()
{
delBTree(_root);
}
private:
Node* _root;
};
test.cpp:
#include <iostream>
#include <vector>
#include "BTree.hpp"
using namespace std;
int main()
{
int a[] = { 53, 139, 75, 49, 145, 36, 101 };
BTree<int, 3> t;
for (auto e : a)
{
t.insert(e);
}
vector<int> ret = t.inOrder();
for (auto num : ret)
cout << num << " - ";
cout << "end" << endl;
return 0;
}
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 数据结构:B树

发表评论 取消回复