SparseDrive
论文链接
https://arxiv.org/pdf/2405.19620
仓库链接
https://github.com/swc-17/SparseDrive
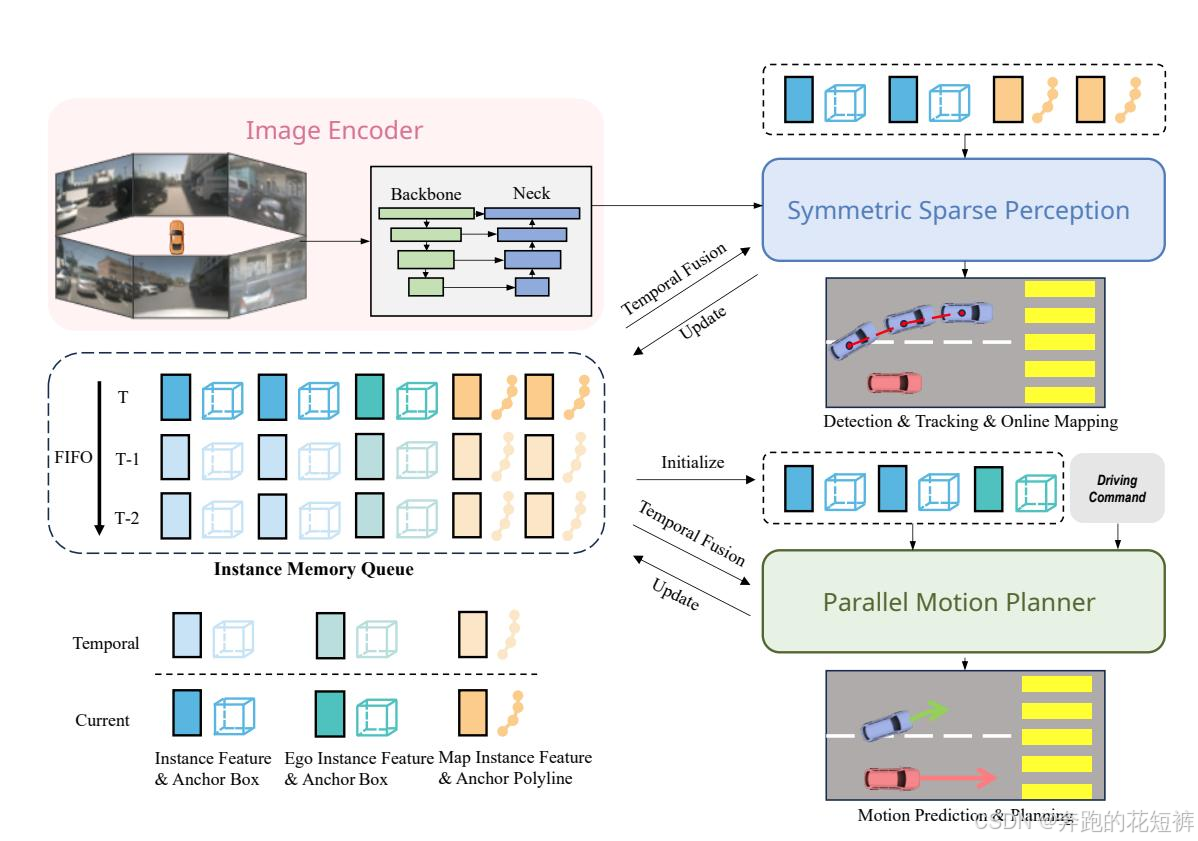
论文和模型的相关介绍大家可以参考其他博客的介绍,这里只介绍模型部署的过程和中间可能遇到的问题解决办法,以及代码解析和使用记录。
模型部署
项目自带有# Quick Start文档,可以参考。
下载的几步可以同步执行。
这里也介绍一下:
1、conda验证或安装
需要使用conda构建虚拟环境
nvcc -V
指令查看conda版本
无conda查看conda安装文档
2、设置新的虚拟环境
初次使用进行create,后续只需进行activate即可。
conda create -n sparsedrive python=3.8 -y
conda activate sparsedrive
3、安装依赖包### Install dependency packpages
是整个过程最复杂的一步了吧,消耗时间较长
cd 至sparsedrive的文件目录下
sparsedrive_path="path/to/sparsedrive"
cd ${sparsedrive_path}
pip3 install --upgrade pip
pip3 install torch==1.13.0+cu116 torchvision==0.14.0+cu116 torchaudio==0.13.0 --extra-index-url https://download.pytorch.org/whl/cu116
pip3 install -r requirement.txt
很容易下载出错,也可以到下载链接出手动下载。https://download.pytorch.org/whl/cu116
按照对应的版本下载就行。我下载的是torch-1.13.0+cu116-cp38-cp38-linux_x86_64.whl等。
下载完成后进行离线安装
打开命令行,使用如下指令进入需要安装pytorch的环境中:
conda activate xxx ##xx代表需要安装的具体环境名称
进入对应环境后,输入下面的指令安装torch,torchvision和torchaudio。
pip install torch-2.0.0+cu117-cp39-cp39-linux_x86_64.whl
……
##安装所有下载的文件,注意使用文件的绝对路径
验证是否安装成功
通过在命令行中输入以下指令验证pytorch是否安装成功
python
>>>import torch
>>>torch.cuda.is_available()
True
当显示True表示torch安装成功。
pip3 install -r requirement.txt
执行这条指令时可能会报错
error: subprocess-exited-with-error
× python setup.py egg_info did not run successfully.
│ exit code: 1
╰─> [12 lines of output]
fatal: 不是 git 仓库(或者任何父目录):.git
Traceback (most recent call last):
File "<string>", line 2, in <module>
File "<pip-setuptools-caller>", line 34, in <module>
File "/tmp/pip-install-az4fmfe4/flash-attn_4cf3f6b2d7834a539c7624728fa4b02f/setup.py", line 117, in <module>
raise RuntimeError(
RuntimeError: FlashAttention is only supported on CUDA 11.6 and above. Note: make sure nvcc has a supported version by running nvcc -V.
torch.__version__ = 1.13.0+cu116
原因是cuda版本过低,升级至要求版本即可。
4、编译可变形聚合操作### Compile the deformable_aggregation CUDA op
前置依赖torch,安装好后可以直接进行编译操作
cd projects/mmdet3d_plugin/ops
python3 setup.py develop
cd ../../../
5、准备数据集### Prepare the data
数据集下载链接
在下载页面下载数据集和CAN bus expansion
根据自己的需要下载mini或者all数据集。(点击后面荧光色US下载)
下载完成后移动至对应文件夹
cd ${sparsedrive_path}
mkdir data
ln -s path/to/nuscenes ./data/nuscenes
打包数据集的元信息和标签,并将所需的pkl文件生成到data/infos。
我们还在data_converter中生成map_annos,默认roi_size为(30,60)。
建议初始按照默认进行执行(如果你想要一个不同的范围,你可以在tools/data_converter/nuscenes_converter.py中修改roi_sze)。
sh scripts/create_data.sh
6、通过K-means生成锚点### Generate anchors by K-means
对于稀疏感知模块很重要
Gnerated anchors are saved to data/kmeans and can be visualized in vis/kmeans.
sh scripts/kmeans.sh
7、下载预训练权重### Download pre-trained weights
Download the required backbone pre-trained weights.
mkdir ckpt
wget https://download.pytorch.org/models/resnet50-19c8e357.pth -O ckpt/resnet50-19c8e357.pth
8、开始训练和测试### Commence training and testing
# train
sh scripts/train.sh
# test
sh scripts/test.sh
9、可视化### Visualization
sh scripts/visualize.sh
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 端到端自动驾驶模型SparseDrive部署过程

发表评论 取消回复