摘要:
语义分割通过对每个像素密集预测其类别,生成对场景的全面理解。深度卷积神经网络的高级特征已经在语义分割任务中证明了它们的有效性,然而高级特征的粗分辨率经常导致对小/薄物体的结果不佳,而这些物体的细节信息非常重要。很自然地,我们考虑引入低级特征来补偿高级特征中丢失的细节信息。不幸的是,简单地结合多级特征会因为它们之间的语义鸿沟而受到影响。在本文中,我们提出了一种新的架构,名为门控全融合(Gated Fully Fusion,GFF),以全连接的方式使用门控机制选择性地融合来自多个级别的特征。具体来说,每个级别的特征都通过具有更强语义的高级特征和具有更多细节的低级特征来增强,并且使用门控来控制有用信息的传播,这显著减少了融合过程中的噪声。我们在四个具有挑战性的场景解析数据集上取得了最先进的结果,包括Cityscapes、Pascal Context、COCO-stuff和ADE20K。
PS:
深度卷积神经网络(Deep Convolutional Neural Networks,DCNNs)的高级特征通常指的是在网络的较深层次中提取的特征。这些特征往往具有以下特点:
-
语义信息丰富:高级特征能够捕捉到图像中更抽象的概念和对象的高级属性,如物体的类别和场景的上下文信息。
-
空间分辨率低:由于网络中的池化(pooling)和卷积操作,高级特征图的空间分辨率通常较低,这意味着它们在描述图像细节方面的能力有限。
-
全局上下文感知:高级特征能够提供全局上下文信息,有助于理解图像的整体内容和结构。
-
对小物体和细节不敏感:由于分辨率较低,高级特征在识别图像中的小物体或细节方面表现不佳。
在语义分割任务中,高级特征的这些特性使得它们在处理大场景和识别高级概念时非常有效,但在需要精细细节的任务中,如小物体的识别或边缘的精确定位,它们的性能可能会下降。因此,研究者们通常会尝试将高级特征与低级特征(如来自网络浅层的特征,具有高空间分辨率)结合起来,以提高分割的精度和细节。GFF(Gated Fully Fusion)架构就是其中一种尝试,它通过门控机制选择性地融合多级特征,以增强特征表示并减少融合过程中的噪声。
空间分辨率(Spatial Resolution)是指图像或特征图中能够区分的最小细节或最小物体的大小。在深度学习和计算机视觉中,空间分辨率是一个重要的概念,因为它直接影响到模型对图像细节的捕捉能力。
在深度卷积神经网络中,空间分辨率的变化通常由以下几个因素决定:
-
卷积层:卷积操作本身不会改变特征图的空间分辨率,除非使用步长(stride)大于1的卷积,这会导致特征图的尺寸减小。
-
池化层:池化(Pooling)操作,尤其是最大池化(Max Pooling)和平均池化(Average Pooling),通常会减小特征图的空间尺寸,从而降低其空间分辨率。
-
步长:卷积和池化操作中的步长决定了操作的覆盖范围,步长越大,特征图的空间尺寸减小得越快。
-
网络深度:随着网络深度的增加,特征图的空间分辨率通常会逐渐降低,因为每经过一层卷积或池化,特征图的尺寸都会减小。
-
上采样:在某些网络结构中,如U-Net或FPN(Feature Pyramid Network),会使用上采样(Upsampling)操作来增加特征图的空间分辨率,以便更好地恢复图像细节。
引言:
语义分割密集地预测图像中每个像素的语义类别,这种全面理解图像的能力对于许多基于视觉的应用非常有价值,例如医学图像分析(Ronneberger, Fischer, 和 Brox 2015)、遥感(Kampffmeyer, Salberg, 和 Jenssen 2016)以及自动驾驶(Xu et al. 2017)。然而,正如图1所示,为每个像素精确预测标签是具有挑战性的,因为像素可能来自微小或大型物体、远或近的物体,以及物体内部或物体边界。
作为一个语义预测问题,语义分割的基本任务是为每个像素生成高级表示,即一个高级且高分辨率的特征图。鉴于卷积神经网络(ConvNets)在从数据中学习高级表示方面的能力,语义分割通过利用这种高级表示取得了很大进展。然而,卷积神经网络生成的高级表示是伴随着降低分辨率进行的,因此高分辨率和高级表示之间的平衡是一个关键问题。
这些特征图具有不同的属性:高级特征图能够以粗略的方式正确预测大部分大模式上的像素,这在当前的语义分割方法中被广泛使用;而低级特征图只能预测小模式上的少量像素。简单地将高级特征图和高分辨率特征图结合起来,会将有用信息淹没在大量无用信息中,无法得到信息丰富的高级和高分辨率特征图。因此,需要一个先进的融合机制,有选择性地从不同的特征图中收集信息。
为了实现这一点,提出了门控全融合(Gated Fully Fusion,GFF),它使用门控机制,这是一种通常用于从时间序列中提取信息的操作,来逐像素地衡量每个特征向量的有用性,并相应地通过门控制信息的传播。每层的门的设计原则是要么发送有用的信息到其他层,要么在本层信息无用时从其他层接收信息。通过这种方式,GFF能够显著减少融合过程中的噪声,并生成具有高分辨率和高级语义信息的特征图。
此外,大感受野内的上下文信息对于语义分割也非常重要,这一点已经被PSPNet(Zhao et al. 2017)、ASPP(Chen et al. 2018b)和DenseASPP(Yang et al. 2018)证明。因此,我们在GFF之后也对上下文信息进行了建模,以进一步提高性能。具体来说,我们提出了一个密集特征金字塔(Dense Feature Pyramid,DFP)模块,将上下文信息编码到每个特征图中。DFP重用每个特征级别的上下文信息,旨在增强上下文建模部分,而GFF在骨干网络上操作以捕获更详细的信息。将这两个组件结合在一个端到端的网络中,我们在四个场景解析数据集上取得了最先进的结果。
我们工作的主要贡献可以总结为三点:
- 首先,我们提出了门控全融合来从多级特征图中生成高分辨率和高级特征图,以及密集特征金字塔来增强多级特征图的语义表示。
- 其次,通过不同层学习的门的详细分析和可视化直观地展示了GFF中的信息调节机制。
ps:语义分割的目标是为图像中的每个像素分配一个类别标签,从而能够识别和区分图像中的不同物体和场景。这种技术可以提供图像的详细理解,因为它不仅识别出图像中的主要物体,还能精确地知道每个像素属于哪个物体或场景的哪一部分。
相关工作:
上下文建模 尽管卷积神经网络中的高级特征图在语义分割上显示出了有希望的结果(Long, Shelhamer, 和 Darrell 2015),但它们的接受域大小仍然不足以捕获大物体和区域的上下文信息。因此,上下文建模成为语义分割中的一个实用方向。PSPNet(Zhao et al. 2017)使用空间金字塔池化来聚合多尺度上下文信息。Deeplab系列(Chen et al. 2015; 2018b; 2017)开发了扩张空间金字塔池化(ASPP),通过具有不同扩张率的扩张卷积层来捕获多尺度上下文信息。与PSPNet和Deeplab中采用的并行聚合不同,Yang et al.(Yang et al. 2018)和Bilinski et al.(Bilinski and Prisacariu 2018)遵循密集连接(Huang et al. 2017)的思想,以密集的方式编码上下文信息。在(Peng et al. 2017)中,直接使用分解的大型滤波器来增加接受域大小,以进行上下文建模。SVCNet(Ding et al. 2019)为每个像素生成一个尺度和形状变化的语义掩码,以限制其上下文区域,2018年),根据在投影特征空间中定义的相似性,从所有位置收集上下文信息。同样,DANet(Fu et al.2018)、CCNet(Huang et al.2018)、EMAnet(Li et al.2019)和ANN(Zhu et al.2019)使用非局部风格操作符(Wang et al. 2018)根据像素间的亲和性从整个图像中聚合信息。
多级特征融合 除了缺乏上下文信息外,顶层还缺乏精细的细节信息。为了解决这个问题,在FCN(Long, Shelhamer, 和 Darrell 2015)中,使用中间层的预测来改善详细结构的分割,而超列(Hariharan et al. 2015)直接结合多层特征进行预测。U-Net(Ronneberger, Fischer, 和 Brox 2015)在编码器和解码器之间添加跳跃连接以重用低级特征,(Zhang et al. 2018b)通过将高级特征融合到低级特征中来改进U-Net。特征金字塔网络(FPN)(Lin et al. 2017b)使用U-Net的结构,并从特征金字塔的每个级别进行预测。DeepLabV3+(Chen et al. 2018c)通过结合低级特征来改进其先前版本的解码器。在(Lin et al.2018)和(Ding et al.2018)中,他们提出在特征金字塔中局部融合每两个相邻的特征图,直到只剩下一个特征图。这些融合方法在特征金字塔中局部操作,没有意识到所有要融合的特征图的有用性,这限制了有用特征的传播。
门控机制 在深度神经网络中,特别是对于循环网络,门通常被用来控制信息传播。例如,LSTM(Hochreiter 和 Schmidhuber 1997)和GRU(Cho et al. 2014)是两个典型的案例,其中使用不同的门来处理长期记忆和依赖关系。高速公路网络(Srivastava, Greff, 和 Schmidhuber 2015)使用门使得训练深度网络成为可能。为了改进场景解析和深度估计的多任务学习,PAD-Net(Xu et al.2018)提出使用门来融合从多个辅助任务训练的多模态特征。DepthSeg(Kong 和 Fowlkes 2018)提出深度感知门控模块,该模块使用深度估计来自适应地修改高级特征图中的池化场大小。GSCNN(Takikawa et al.2019)使用门通过包括另一个形状流来编码边缘特征到最终表示中,以学习精确的边界信息。
我们的方法与上述方法有关并受到启发,与它们不同的是,多级特征图通过门控机制同时融合,并且结果方法超越了最先进的方法。
方法
在本节中,我们首先概述了多级特征融合的基本设置和三种基线融合策略。然后,我们介绍了所提出的多级融合模块(GFF)以及带有上下文建模模块(DFP)的整个网络。
多级特征融合
给定从某些骨干网络(例如ResNet)提取的L个特征图 ,其中特征图按照它们在网络中的深度排序,语义信息随着深度增加而增加,但细节信息减少。
分别是第i个特征图的高度、宽度和通道数。由于下采样操作,较高层的特征图分辨率较低,即
。在语义分割中,通常使用具有原始输入图像1/8分辨率的顶层特征图
,因为它具有丰富的语义信息。
的主要限制是其空间分辨率低,没有详细信息,因为输出需要与输入图像具有相同的分辨率。相比之下,来自浅层的低级特征图具有高分辨率,但语义信息有限。直观上,结合多个层级特征图的互补优势将实现高分辨率和丰富语义的目标,这个过程可以抽象为一个融合过程f,即,
其中是第l层的融合特征图。为了简化以下方程中的符号,忽略了双线性采样和 1X1 卷积,这些操作用于重塑右侧的特征图,使融合后的特征图与左侧的特征图具有相同的大小。连接(Concatenation)是一种直接的操作,用于聚合多个特征图中的所有信息,但它将有用信息与大量非信息特征混合在一起。加法(Addition)是另一种简单的特征图组合方式,通过在每个位置添加特征来实现,但它也遭受与连接类似的的问题。FPN(Lin et al. 2017b)通过自顶向下的路径和横向连接进行融合过程。这三种融合策略可以翻译为:
- 连接(Concatenation):这是一种直接的操作,用于聚合多个特征图中的所有信息,但它会将有用信息与大量非信息特征混合在一起。
- 加法(Addition):这是另一种简单的特征图组合方式,通过在每个位置添加特征来实现,但它也遭受与连接类似的问题。
- FPN(Feature Pyramid Network):通过自顶向下的路径和横向连接进行融合过程。
这些策略都是为了解决高层特征图分辨率低和低层特征图语义信息有限的问题,通过融合不同层级的特征图来提高语义分割的性能:
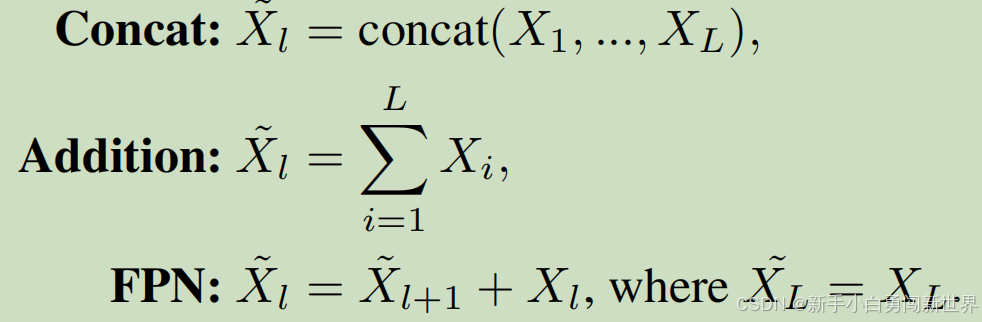
这些基本融合策略的问题是特征在不测量每个特征向量的有用性的情况下融合在一起,在融合过程中将大量无用的特征与有用的特征混合。
Gated Fully Fusion(门控全融合)
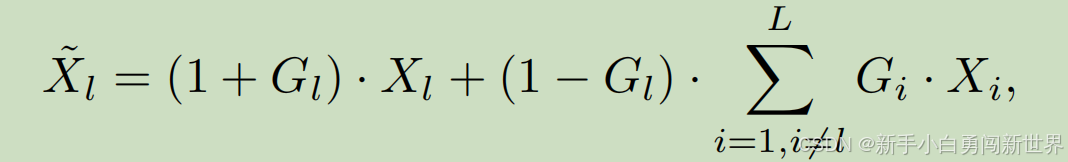
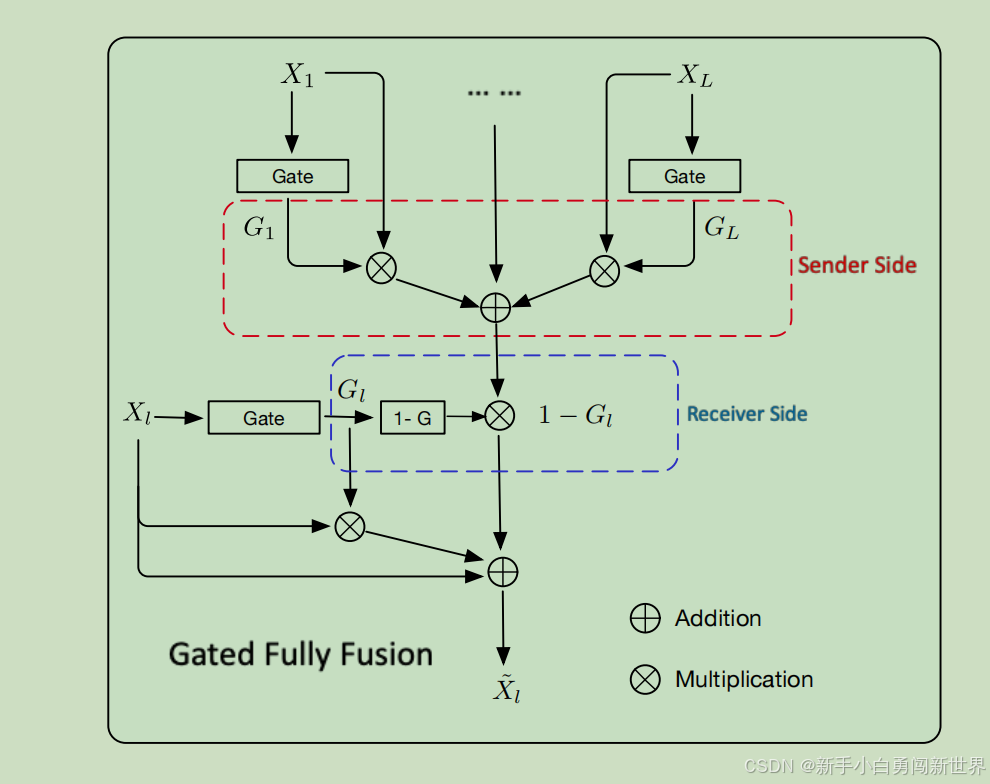
与其他门控模块的比较:Ding等人(2018)的工作也使用了门控机制来控制相邻层之间的信息。GFF的不同之处在于使用门控机制来完全融合来自每个层级的特征,而不是相邻层级,并且在所有层级中拥有丰富的信息和较大的可用性差异,这激励我们设计了双门控机制,它通过在发送者和接收者两侧的门控更有效地过滤掉无用信息。实验部分的实验结果展示了所提方法的优势。
密集特征金字塔
上下文建模旨在编码更多的全局信息,它与所提出的GFF正交(上下文建模和GFF是两个互补的过程,它们可以结合在一起以增强特征表示。GFF专注于在骨干网络中融合不同层级的特征,而上下文建模则专注于增强特征的全局上下文信息,从而提高模型对场景的整体理解能力。),因为GFF是为骨干网络层级设计的。因此,我们进一步设计了一个模块来从PSPPNet(Zhao等人,2017)和GFF的输出中编码更多的上下文信息。受到密集连接可以加强特征传播(Huang等人,2017)的启发,我们也从PSPPNet输出的特征图开始,以自顶向下的方式密集连接特征图,并且高级特征图被多次重用来向低层添加更多的上下文信息,这在我们的实验中对于正确分割物体中的大模式被发现是重要的。这个过程如下所示:
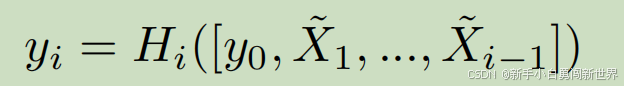
因此,第j个特征金字塔接收所有前导金字塔的特征图 $y_{0}, \tilde{X}{1},\ldots\tilde{X}{i-1}$ 作为输入,并输出当前金字塔 $y_{i}$:其中 $y_{0}$ 是 PSP-Net 的输出,而 $\tilde{X}{i}$ 是第i个 GFF 模块的输出。融合函数 $H{i}$ 由一个单一卷积层实现。由于特征金字塔密集连接,我们将这个模块称为密集特征金字塔(Dense Feature Pyramid,DFP)。DFP的输出集合 $y_{i}$ 用于最终预测。GFF和DFP都可以插入到现有的 FCNs(全卷积网络Fully Convolutional Networks) 中,以端到端的训练方式进行,并且只需额外的计算成本。
网络架构和实现
我们的网络架构是基于之前最先进的网络 PSPNet(Zhao et al. 2017)设计的,使用 ResNet(He et al. 2016)作为骨干网络进行基本特征提取,ResNet 的最后两个阶段通过扩张卷积修改,使两个步长为1并保持空间信息。图3显示了包括 GFF 和 DFP 的整体框架。PSPNet 形成了自下而上的路径,与骨干网络和金字塔池化模块(PPM),其中 PPM 在顶部编码上下文信息。每个阶段的最后残差块的特征图翻译成骨干网络的特征图用作GFF模块的输入,所有特征图通过1×1卷积层减少到256个通道。来自GFF的输出特征图在输入到DFP模块之前,每个层级进一步通过两个3×3卷积层融合。所有卷积层后面都跟着批量归一化(Ioffe和Szegedy 2015)和ReLU激活函数。在DFP之后,所有特征图被连接起来进行最终的语义分割。与基本的PSPNet相比,提出的方法只略微增加了参数数量和计算量。整个网络以端到端的方式训练,由定义在分割基准上的交叉熵损失驱动。为了促进训练过程,辅助损失与主损失一起使用来帮助优化,遵循(Lee等人。2015),其中主损失定义在网络的最终输出上,辅助损失定义在ResNet的第3阶段的输出特征图上,权重为0.4(Zhao等人。2017)。
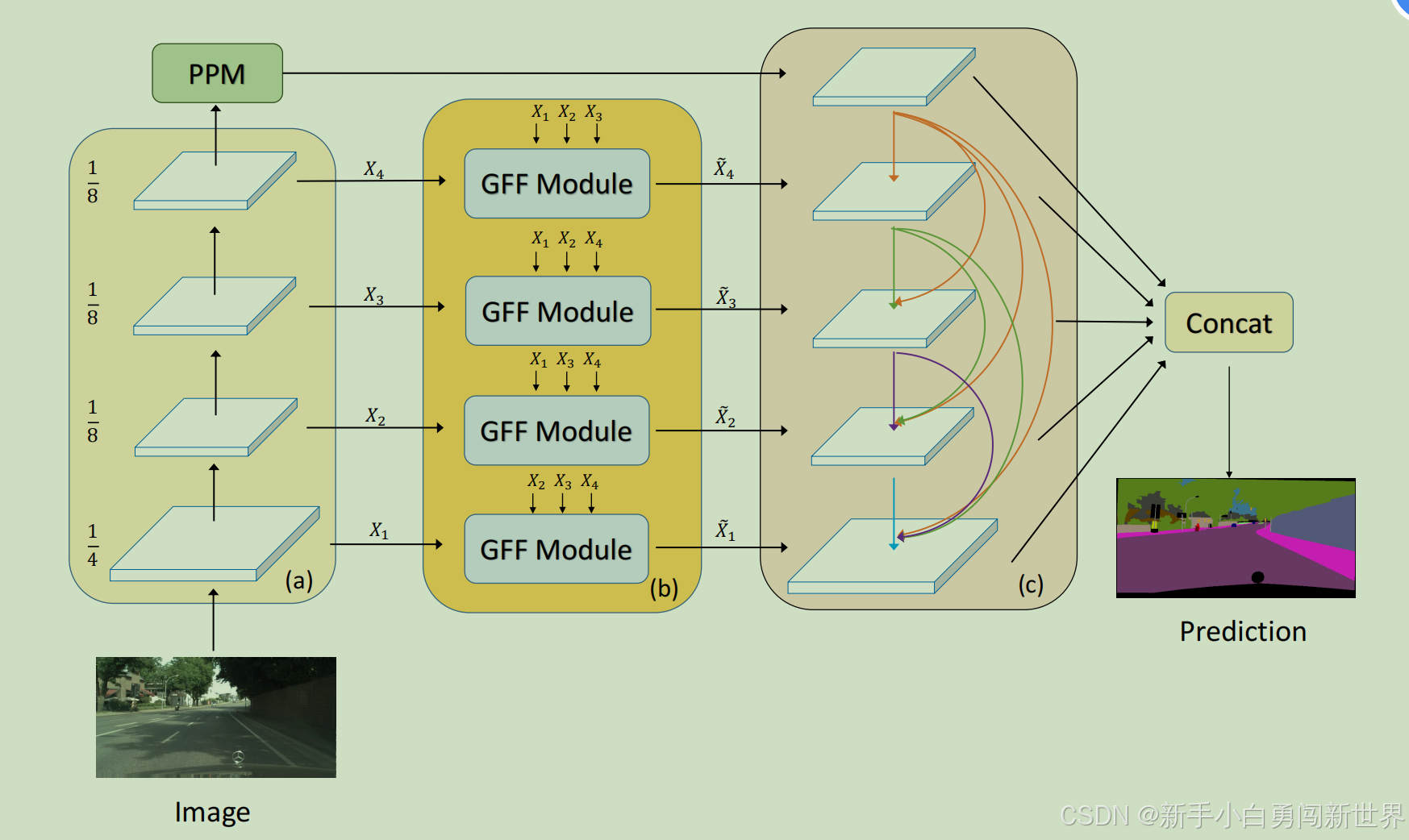
整体架构的说明。(a)骨干网络(例如ResNet(He等人2016)),顶部有金字塔池模块(PPM)(Zhao等人2017)。主干提供了一个不同层次的特征金字塔。(b),特征金字塔通过门控完全融合(GFF)模块。GFF模块的细节如图2所示。(c),然后从一个密集的特征金字塔(DFP)模块中获得包含上下文信息的最终特征。最佳视图和放大。
PS:PSPPNet(Pyramid Scene Parsing Network)是一种用于语义分割的深度学习模型,它通过构建一个金字塔结构来聚合多尺度的上下文信息,从而提高分割的精度。PPNet的核心组件包括:
-
金字塔池化模块(Pyramid Pooling Module):这个模块通过不同尺度的池化操作来捕获图像的多尺度上下文信息。
-
特征融合:PPNet通过融合金字塔池化模块输出的特征图和骨干网络中的特征图来增强特征的表达能力。
-
上采样和解码:融合后的特征图会经过上采样和解码过程,以生成高分辨率的分割图。
PPNet的输出通常是一个高分辨率的特征图,这个特征图包含了丰富的上下文信息,可以用于生成最终的像素级分割结果。在实际应用中,PPNet的输出可以进一步通过softmax层转换为每个像素的类别概率分布,从而得到最终的分割掩码(mask)。PPNet因其有效的上下文聚合能力和对多尺度物体的良好处理能力,在语义分割任务中取得了很好的效果。
最终的分割掩码(mask)是语义分割任务的输出结果,它是一个与输入图像大小相同的二维数组,其中每个像素的值代表该像素所属的类别。在语义分割中,分割掩码通常用于表示图像中每个像素的类别标签,从而实现对图像中不同区域的区分和识别。
分割掩码的生成过程通常包括以下步骤:
-
特征提取:使用深度卷积神经网络(如ResNet、VGGG等)提取图像的特征。
-
特征融合:通过特征融合技术(如PPNet、GFF等)聚合不同尺度或不同层级的特征信息,以增强特征的表达能力。
-
上采样:将融合后的特征图上采样到与原始图像相同的分辨率。
-
分类:通过一个分类层(通常是全连接层或卷积层)对每个像素进行分类,得到每个像素的类别概率。
-
生成掩码:根据分类结果,将概率最高的类别标签分配给每个像素,生成最终的分割掩码。
实验
结论
在这项工作中,我们提出门控完全融合(GFF)来完全融合由学习门映射控制的多层次特征图。该新模块搭建了低语义高分辨率和高语义低分辨率之间的桥梁。我们探索了所提出的语义分割任务的GFF,并获得了新的最先进的结果,四个具有挑战性的场景解析数据集。特别是,我们发现缺失的低级特征可以融合到金字塔的每个特征层次中,这表明我们的模块可以很好地处理场景中的小的对象。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » GFF: Gated Fully Fusion for Semantic Segmentation门控融合语义分割-论文阅读笔记

发表评论 取消回复