原文链接
原文笔记
What
提出了一种新的基于锚点的查询设计,即将锚点编码为对象查询。
Why
对象检测任务是预测图像中每个对象的边界框和类别。在过去的几十年里,基于CNN的目标检测取得了很大进展(Ren et al. 2015;Cai和Vasconcelos 2018;Redmon et al. 2016;Lin et al. 2017;Zhang et al. 2019;乔、陈和Yuille 2020;Chen et al. 2021)。最近,Carion等人(Carion et al. 2020)提出了DETR,它是基于变压器的目标检测的新范式。它使用一组学习的对象查询来推断对象和全局图像上下文之间的关系,以输出最终的预测集。然而,学习到的对象查询很难解释。它没有明确的物理意义,每个对象查询的相应预测槽没有特定的模式。如图1(a)所示,DETR中每个对象的查询的预测与不同的区域有关,每个对象查询都负责非常大的区域。这种位置歧义,即对象查询不关注特定区域,使得object query很难优化。
Challenge
1、如何让对象查询关注固定位置
2、如何解决一个区域包含多个对象的问题
3、如何解决传统attention计算效率慢内存占用大的问题
Idea
对1:将锚点编码进Object Query
对2:使用单锚点多Pattern进行匹配
对3:采用x、y坐标分解的attention进行注意力计算
原文翻译
Abstract
在本文中,我们提出了一种新的基于变压器的目标检测查询设计。在之前的基于变压器的检测器中,对象查询是一组学习嵌入。然而,每个学习嵌入没有明确的物理意义,我们无法解释它将关注的地方。很难优化,因为每个对象查询的预测槽没有特定的模式。换句话说,每个对象查询不会关注特定区域。为了解决这些问题,在我们的查询设计中,对象查询基于锚点,这已经广泛用于基于 CNN 的检测器。因此,每个对象查询都关注锚点附近的对象。此外,我们的查询设计可以在一个位置预测多个对象以解决困难:“一个区域、多个对象”。此外,我们设计了一个注意力变体,它可以在实现与标准注意力相似或更好的性能的同时降低内存成本。由于查询设计和注意力变体,我们提出的称为 Anchor DETR 的检测器可以实现更好的性能,并且运行速度比 DETR 快 10 倍,训练 epoch 更少。例如,当使用 ResNet50-DC5 特征训练 50 个 epoch 时,它在 MSCOCO 数据集上以 19 FPS 实现了 44.2 AP。在 MSCOCO 基准上的广泛实验表明了所提出方法的有效性。代码可在 https://github.com/megvii-research/AnchorDETR 获得。
Introduction
对象检测任务是预测图像中每个对象的边界框和类别。在过去的几十年里,基于CNN的目标检测取得了很大进展(Ren et al. 2015;Cai和Vasconcelos 2018;Redmon et al. 2016;Lin et al. 2017;Zhang et al. 2019;乔、陈和Yuille 2020;Chen et al. 2021)。最近,Carion等人(Carion et al. 2020)提出了DETR,它是基于变压器的目标检测的新范式。它使用一组学习的对象查询来推断对象和全局图像上下文之间的关系,以输出最终的预测集。然而,学习到的对象查询很难解释。它没有明确的物理意义,每个对象查询的相应预测槽没有特定的模式。如图1(a)所示,DETR中每个对象的查询的预测与不同的区域有关,每个对象查询都负责非常大的区域。这种位置歧义,即对象查询不关注特定区域,使得object query很难优化。
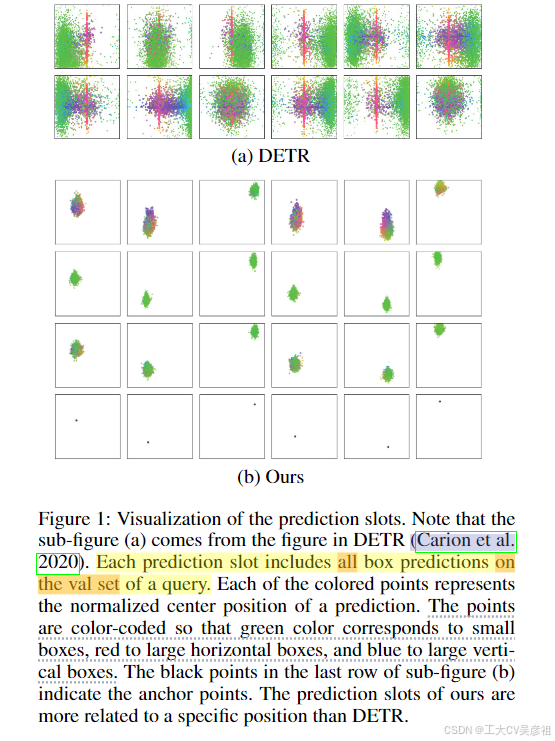
回顾基于CNN的检测器,锚点与位置高度相关,包含可解释的物理意义。受这种动机的启发,我们提出了一种新的基于锚点的查询设计,即将锚点编码为对象查询。对象查询是锚点坐标的编码,以便每个对象查询具有明确的物理意义。但是,该解决方案会遇到困难:将有多个对象出现在一个位置。在这种情况下,该位置只有一个对象查询无法预测多个对象,因此来自其他位置的对象查询必须协同预测这些对象。这将导致每个对象查询负责更大的区域。因此,我们通过将多个模式添加到每个锚点来改进对象查询设计,以便每个锚点都可以预测多个对象。如图1(b)所示,每个对象查询的三种模式的所有预测都分布在相应的锚点周围。换句话说,它表明每个对象查询只关注相应锚点附近的对象。因此,所提出的对象查询可以很容易地解释。由于对象查询具有特定模式,不需要预测远离相应位置的对象,因此更容易优化。
除了查询设计之外,我们还设计了一个注意力变体,我们称之为 Row-Column Deouple Attention (RCDA)。它将二维关键特征解耦为一维行特征和一维列特征,依次进行行注意和列注意。RCDA 可以在实现与标准注意力相似或更好的性能的同时降低内存成本。我们相信这可能是 DETR 中标准注意力的一个很好的替代方案。
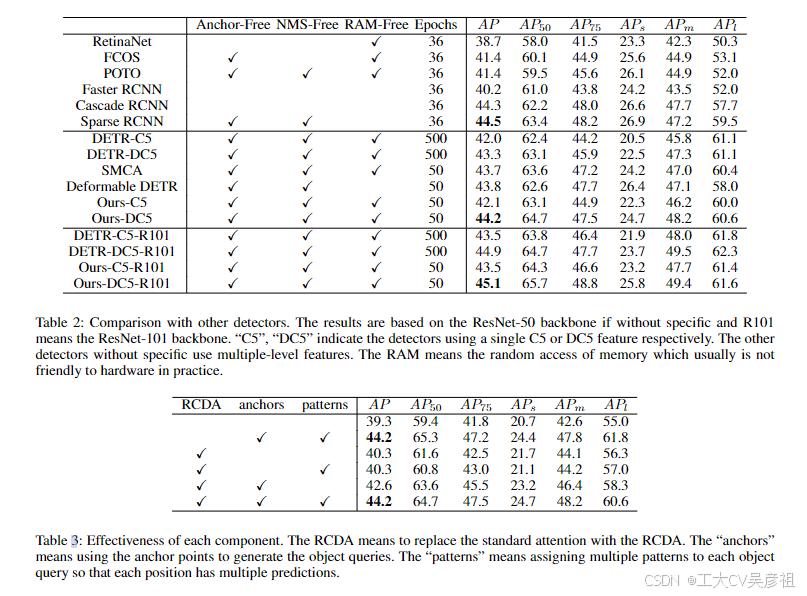
如表 1 所示,由于基于锚点和注意力变体的新颖查询设计,所提出的检测器 Anchor DETR 可以在使用相同的单级特征时实现比原始 DETR 更好的性能并运行得更快,训练时间减少了 10 倍。与其他训练 epoch 少 10 倍的类 DETR 检测器相比,所提出的检测器在其中实现了最佳性能。当使用单个 ResNet50-DC5 (He et al. 2016) 特征训练 50 个 epoch 时,所提出的检测器可以以 19 FPS 的速度实现 44.2 AP。
主要贡献可以概括为:
• 我们为基于变压器的检测器提出了一种基于锚点的新型查询设计。此外,我们在每个锚点上附加多个模式,以便它可以为每个位置预测多个物体以处理“一个区域,多个对象”。的困难。基于锚点的建议查询比学习嵌入更易于解释和更容易优化。由于所提出的查询设计的有效性,我们的检测器可以在比 DETR 少 10 倍的训练 epoch 的情况下获得更好的性能。
• 我们设计了一个注意力变体,我们称之为 RowColumn 解耦注意力。它可以减少内存成本,同时实现与标准注意力相似或更好的性能,这可能是标准注意力的一个很好的替代方案。
• 进行了广泛的实验以证明每个组件的有效性。
Relative Work
Anchors in Object Detection
基于 CNN 的对象检测器中使用了两种类型的锚点,即锚框(Ren et al. 2015; Lin et al. 2017)和锚点(Tian et al. 2019; Zhou, Wang, and Kr̈ahenb̈uhl 2019)。由于需要仔细调整手工制作的锚框以实现良好的性能,我们可能更喜欢不使用锚框。我们通常将不使用锚框的方法称为无锚的方法,所以使用锚点的检测器也被视为无锚的(Tian et al. 2019; Zhou, Wang, and Kr̈ahenb̈uhl 2019)。DETR (Carion et al. 2020)既不采用锚盒也不采用锚点。它直接预测图像中每个对象的绝对位置。但是,我们发现将锚点引入对象查询可以更好。
Transformer Detector
Vaswani 等人。 (Vaswani et al. 2017) 首先提出了用于序列转导的transformer。最近,Carion等人(Carion et al. 2020)提出了基于transformer进行目标检测的DETR。转换器检测器将根据查询和键的相似性将值的信息提供给查询。Zhu等人(Zhu et al. 2020)提出了可变形DETR,将值的可变形点采样到查询,并使用多层次特征来解决变压器检测器收敛速度慢的问题。高等人。 (Gao et al. 2021) 在每个查询的原始注意力中添加高斯图。
与我们同时,条件DETR (Meng et al. 2021)将参考点编码为查询位置嵌入。但是动机不同,因此仅使用参考点来生成位置嵌入作为交叉注意力中的条件空间嵌入,对象查询仍然是学习嵌入。此外,它不涉及一个位置多物体检测和注意力的计算变体。
Efficient Attention
Transformer 的 self-attention 具有很高的复杂性,因此它不能很好地处理大量查询和键。为了解决这个问题,已经提出了许多有效的注意力模块(Wang et al. 2020b;Shen et al. 2021; Vaswani et al. 2017; Beltagy, Peters, and Cohan 2020; Liu et al. 2021; Ma et al. 2021).一种方法是首先计算键和值,这可能会导致查询或键数量的线性复杂度。高效注意(Shen et al. 2021)和线性注意(Katharopoulos et al. 2020)遵循这一思想。另一种方法是限制每个查询的关键注意区域而不是整个区域。Restricted SelfAttention (Vaswani et al. 2017)、Deformable Attention (Zhu et al. 2020)、Criss-Cross Attention (Huang et al. 2019)和LongFormer (Beltagy, Peters和Cohan 2020)遵循这一思想。在本文中,我们通过一维全局平均池化将关键特征解耦为行特征和列特征,然后依次进行行注意和列注意。
Method
Anchor Points
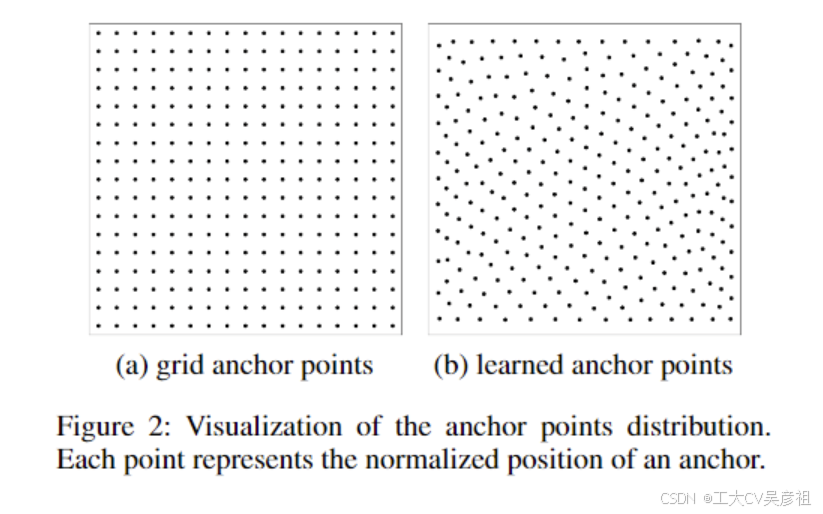
在基于 CNN 的检测器中,锚点始终是特征图的相应位置。但是它在基于变压器的检测器中更加灵活。锚点可以是学习点、均匀网格点或其他手工锚点。我们采用两种类型的锚点。一个是网格锚点,另一个是学习的锚点。如图2(a)所示,网格锚点固定为图像中的均匀网格点。学习的点使用从 0 到 1 的均匀分布随机初始化,并作为学习参数进行更新。使用锚点,将预测边界框的中心位置(ˆcx,ˆcy)添加到相应的锚点作为最终预测(等于预测的是偏移量),就像在Deformable DETR中一样(朱等人)。2020)。
Attention Formulation
类detr变压器的注意力可以表述为:
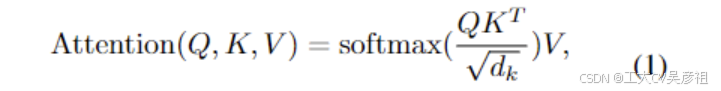
Q = Qf + Qp, K = Kf + Kp, V = Vf ,
其中dk是通道维度,下标f表示特征,下标p表示位置嵌入,Q、K、V 分别是查询、键和值。请注意,Q、K、V 将分别通过线性层,为清楚起见,等式 (1) 中省略。
DETR 解码器有两个关注。一个是自注意力,另一个是交叉注意力。在 selfattention 中,Kf 和 Vf 与 Qf 相同,而 Kp 与 Qp 相同。Qf ∈ RNq ×C 是最后一个解码器的输出,第一个解码器的初始 Qinit f ∈ RNq ×C 可以设置为常数向量或学习嵌入。对于查询位置嵌入 Qp ∈ RNq ×C ,它在 DETR 中使用一组学习嵌入来表示:
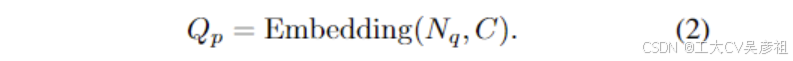
在交叉注意中,Qf ∈ R^Nq ×C 是从前面自注意力的输出生成的,而 Kf ∈R^HW ×C 和 Vf ∈ R^HW ×C 是编码器的输出特征。Kp ∈ R^HW ×C 是 Kf 的位置嵌入。它是正弦余弦位置编码函数(Vaswani et al. 2017;Carion et al. 2020) gsin基于相应的关键特征位置P osk∈RHW ×2:
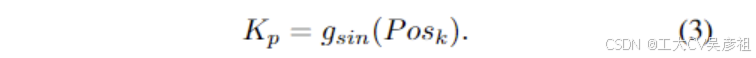
请注意,H、W、C 是特征的高度、宽度、通道,Nq 是查询的预定义数量。
Anchor Points to Object Query(重点)
通常情况下,decoder的Qp被认为是对象查询(Object Query)因为他负责区分不同的对象,像公式(2)那样基于学习的对象查询很难去解释其内涵(没有明确的物理意义),正如Introduction模块讨论的那样
(这里解释一下,有的说法认为Qf是对象查询,Qp是对象查询的位置编码,有的说法认为Q是对象查询,这里又说Qp在通常情况下被认为是对象查询,但是其实在实现中Q=Qf+Qp,而在detr,deformable-detr中Qf被初始化为全0张量,所以Q=Qp=对象查询)
在本文中,我们提出基于anchor pointPosq来设计对象查询,P osq ∈ R^NA×2 表示 NA 点及其 (x, y) 位置,范围从 0 到 1。然后基于锚点的对象查询可以表述为:
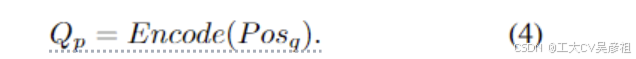
这意味着我们将锚点编码为对象查询。
所以如何设计编码函数。由于对象查询被设计为查询位置嵌入,如公式(1)所示,最自然的方法是共享与键相同的位置编码函数:
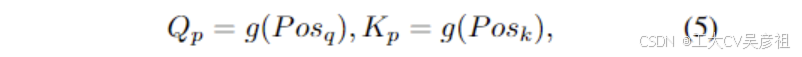
其中 g 是位置编码函数。位置编码函数可以是 gsin 或其他位置编码函数。在本文中,我们更喜欢使用具有两个线性层的小型 MLP 网络来额外调整它,而不是仅仅使用启发式 gsin。
Multiple Predictions for Each Anchor Point(重点)
为了处理一个位置可能有多个对象的情况,我们进一步改进了对象查询来预测每个锚点的多个对象,而不仅仅是一个预测。回顾初始查询特征Qinit f∈R^Nq ×C,每个Nq对象查询都有一个模式Qi f∈R^1×C。请注意,i 是对象查询的索引。为了预测一个锚点位置上存在的多个物体,我们可以将多个模式合并到每个对象查询中。我们使用一小组模式嵌入 Qi f ∈ R^Np ×C :
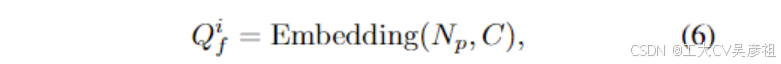
来检测每个位置具有不同模式的对象,Np是模式的数量,这通常是一个很小的数字,例如Np=3,对于平移不变性的属性,为所有对象查询共享模式。因此,我们可以通过将Qi f∈RNp ×C共享到Qp∈RNA×C中的每一个,得到初始qinit f∈RNpNA×C和Qp∈RNp NA ×C。这里 Nq 等于 Np × NA。然后我们可以将所提出的 PatternPosition 查询设计定义为:
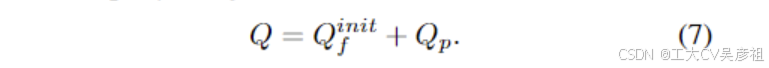
对于以下解码器,Qf 也是最后一个解码器的输出生成的,像DETR一样。
由于所提出的查询设计,所提出的检测器具有可解释的查询,并且比原始 DETR 具有更好的性能,训练时间减少了 10 倍。
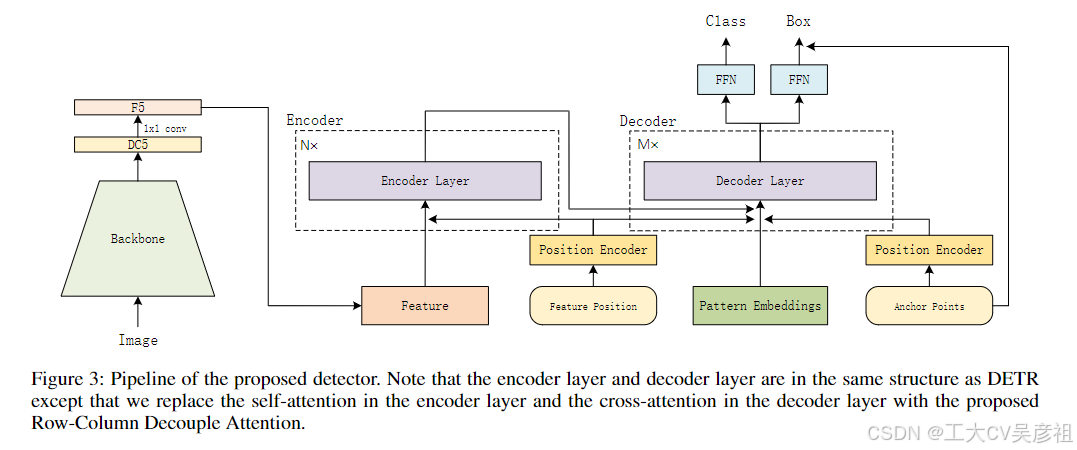
Row-Column Decoupled Attention
Transformer 将花费大量 GPU 内存,这可能会限制其使用高分辨率特征或其他扩展。
Deformable Transformer (Zhu et al. 2020)可以降低内存成本,但它将导致对硬件不友好的内存的随机访问。还有一些注意模块(Ma et al. 2021;Shen et al. 2021)具有线性复杂度,不会导致内存的随机访问。然而,在我们的实验中,我们发现这些注意力模块不能很好地处理类似 DETR 的检测器。这可能是因为类似 DETR 的解码器中的交叉注意力比自注意力要困难得多。
在本文中,我们提出了行列解耦注意(RCDA),它不仅可以减少内存负担,而且实现了相较于DETR中的标准注意力相似或更好的性能。RCDA的主要思想是通过一维全局平均池化将关键特征Kf∈R^H×W ×C解耦为行特征Kf,x∈R^W ×C和列特征Kf,y∈R^H×C。然后我们依次执行行注意和列注意。不失一般性,我们假设 W ≥ H and RCDA 可以表述为:
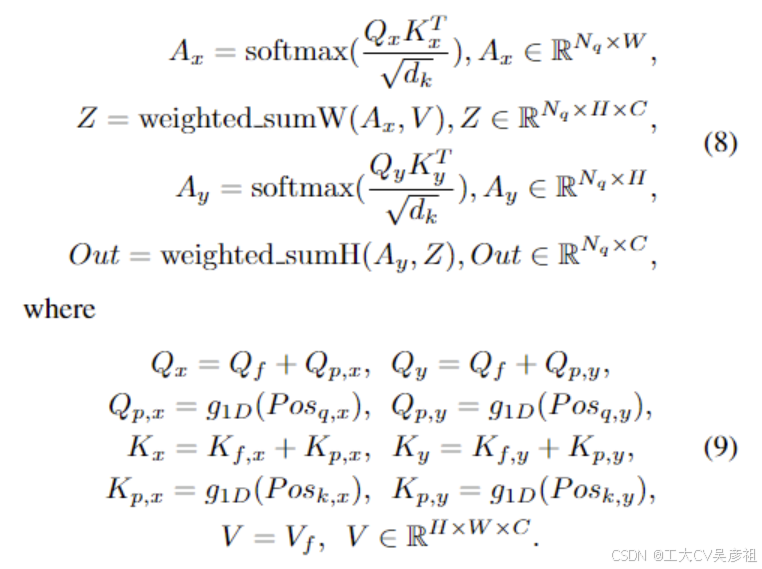
加权和 W 和加权和 H 操作分别沿宽度维度和高度维度进行加权求和。P osq,x ∈ RNq ×1 是 Qf ∈ RNq ×C 和 P osq,y ∈ RNq ×1, P osk,x ∈ RW ×1, P osk,y ∈ RH×1 的相应行位置以类似的方式。g1D 是类似于 g 的 1D 位置编码函数,它将 1D 坐标编码为具有 C 个通道的向量。
现在我们分析一下为什么它可以节省内存。在前面的公式中,为了清晰,我们假设多头注意的头数M为1,而不失去一般性,但我们应该考虑头数M进行内存分析。在DETR中,注意力的主要内存开销是注意力权重图 A ∈ RNq ×H×W ×M。但是 RCDA 的注意权重图是 Ax ∈ RNq ×W ×M 和 Ay ∈ RNq ×H×M,其内存成本远小于 A。然而,RCDA 的主要内存成本是临时结果 Z。所以我们应该比较 A ∈ RNq ×H×W ×M 和 Z ∈ RNq ×H×C 的内存成本。RCDA 保存内存的比率为:
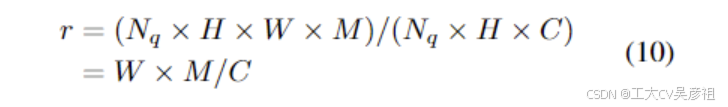
其中默认设置为 M = 8, C = 256。因此,当大边 W 等于 32 时,内存成本大致相同,这是对象检测中 C5 特征的典型值。当使用高分辨率特征时,可以节省内存,例如为 C4 或 DC5 特征节省大约 2 倍的内存,并为 C3 特征节省 4 倍的内存。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Anchor DETR论文笔记

发表评论 取消回复