
背景
在数据分析和业务报告中,Excel 文件广泛用于存储和展示信息,特别是在需要对数据进行分类和分组时。许多商业场景中,数据会以多层级表头的形式呈现,体现不同维度的信息。例如,在财务报表中,可能按年度、季度和产品类别等层次展示;在人力资源管理中,考勤数据可能按照部门、职位等进行分类。
然而,处理多层级的 Excel 表头增加了数据操作的复杂性。手动操作这些数据容易出错,且不利于后续的自动化处理。此时,pandas 库提供了强大而灵活的 MultiIndex 和 .loc[] 方法来简化这些操作,使得高效地读取和处理这些层级化数据成为可能。本文将介绍如何使用 MultiIndex 和 .loc[] 处理多层级 Excel 表头,帮助我们在实际业务中提升效率。
前置操作
在处理Excel 文件时,首先需要安装 pandas 库。如果尚未安装,可以通过以下命令安装:
pip install pandas openpyxl
为本文准备一份演示的名为 demo.xlsx 的文件,内容如下截图所示:
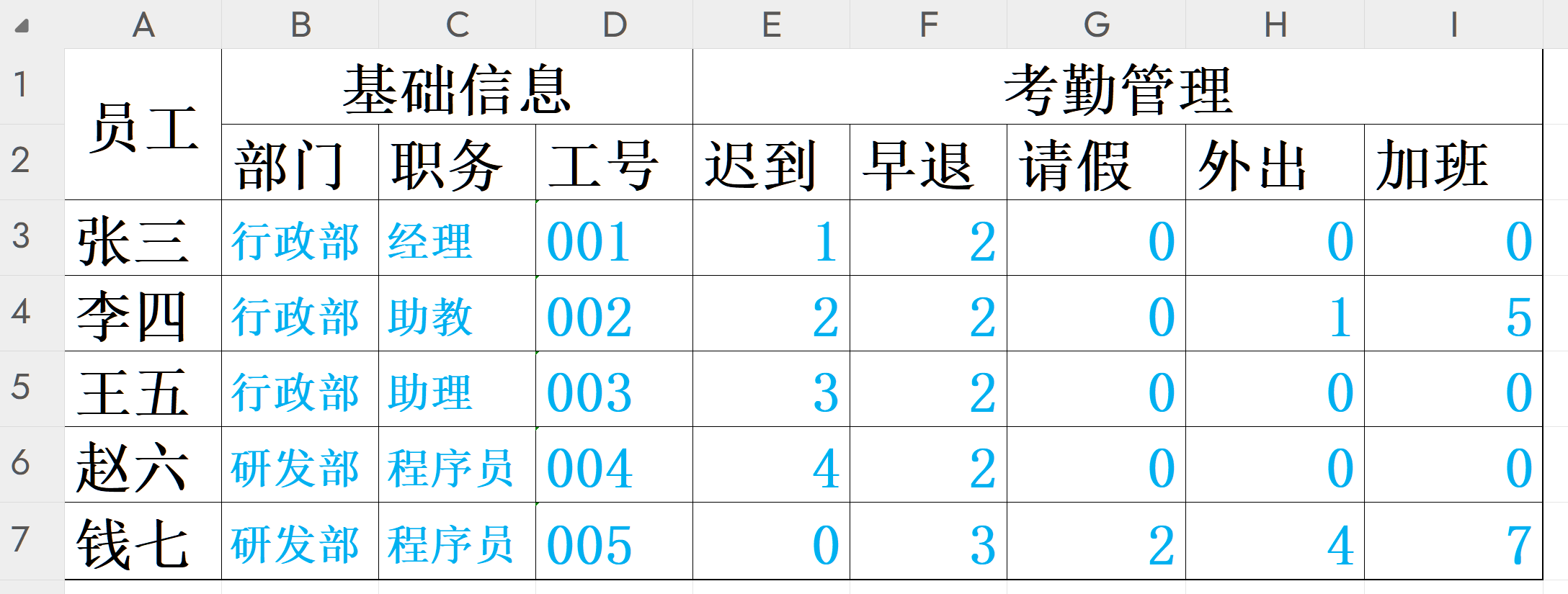
1. 理解 MultiIndex 的概念
MultiIndex 是 pandas 中一种特殊的索引类型,允许在行或列上使用多个级别的索引。这种结构使得数据可以更清晰地组织成层次关系。例如,一个考勤表可能包含多列(如“基础信息”、“考勤管理”)作为顶层索引,而具体的类别作为次级索引。
应用场景
在处理带有层级结构的 Excel 文件时,MultiIndex 特别有用。例如,财务报表可能按月份、产品类别等层级组织,使用 MultiIndex 可以方便地进行数据分析和报告生成。
2. 读取多层级表头的 Excel 文件
接下来,我们使用 pandas 的 read_excel() 函数读取 Excel 文件,并指定前几行为表头:
import pandas as pd
# 读取 Excel 文件,指定前两行为表头
df = pd.read_excel('demo.xlsx', header=[0, 1])
# 查看生成的多层级表头
print(df.columns)
在此示例中,header=[0, 1] 表示将 Excel 文件中的第 1 行和第 2 行作为表头。这两行的内容将形成一个 MultiIndex 结构,使得后续的数据处理更加灵活。([0, 1]是行索引~)
3. 将多层表头的数据处理为嵌套字典
为了便于后续的数据提取和分析,我们可以将多层级的表头转换为嵌套字典。这种结构化的方法可以帮助我们更清晰地查看和访问各个层级的列信息。
以下代码展示了如何实现:
from collections import defaultdict
# 将多层表头的数据处理为嵌套字典
result = defaultdict(lambda: {'column': [], 'index': []})
# 遍历每个大类列
for idx, columns in enumerate(df.columns.values.tolist()):
key, val = columns
result[key]['column'].append(val)
result[key]['index'].append(idx)
# 打印最终结果字典
print(dict(result))
该代码的输出:
{
"员工": {
"column": ["Unnamed: 0_level_1"],
"index": [0]
},
"基础信息": {
"column": ["部门", "职务", "工号"],
"index": [1, 2, 3]
},
"考勤管理": {
"column": ["迟到", "早退", "请假", "外出", "加班"],
"index": [4, 5, 6, 7, 8]
}
}
在这段代码中,我们使用 defaultdict 创建了一个嵌套字典。通过遍历 df.columns.values.tolist(),我们提取了每个大类的列名和索引,将它们存储在字典中。这样一来,我们就能够方便地获取某一大类下所有的列信息,为后续的数据处理打下基础。
4. 多层级表头的切片与筛选
在处理多层级数据时,灵活的切片与筛选是分析的关键步骤。通过使用 MultiIndex 结构,我们可以高效地访问特定的数据子集,确保分析的精确性和高效性。
切片与筛选的基本概念
切片和筛选是指通过特定条件选择数据的过程。在 pandas 中,切片可以使用 .loc[] 方法和 IndexSlice 类进行,允许我们根据多层级索引来提取所需数据。
使用 .loc[] 进行切片
.loc[] 的基本用法是:
data = df.loc[row_indexer, column_indexer]
row_indexer用于指定行的选择。column_indexer用于指定列的选择。
在多层级索引中,可以使用 pd.IndexSlice 来简化选择过程。例如,若我们需要提取某个特定类别下的所有列数据,可以使用如下代码:
# 提取特定的列,提取顶层A列的one二级列
data = df.loc[:, pd.IndexSlice['A', 'one']]
print(data)
这里的 pd.IndexSlice 允许我们根据多层级的索引值精确提取需要的数据,: 表示我们选择所有行。
例子分析
使用本文提供的 Excel 文件示例,
多层级获取顶级列全部的子列
# 提取“基础信息”的所有员工基本信息
base_info = df.loc[:, pd.IndexSlice['基础信息', slice(None)]]
print(base_info)
在这个例子中,slice(None) 表示选择“基础信息”顶层列下的所有类别列。
输出结果如下:
基础信息
部门 职务 工号
0 行政部 经理 1
1 行政部 助教 2
2 行政部 助理 3
3 研发部 程序员 4
4 研发部 程序员 5
多层级获取顶级列的指定子列
如获取 考勤管理 中的 请假 和 加班列的内容
# 提取“基础信息”的所有员工基本信息
base_info = df.loc[:, pd.IndexSlice['考勤管理', ['请假', '加班']]]
print(base_info)
在这个例子中,pd.IndexSlice['考勤管理', ['请假', '加班']] 表示选择“考勤管理”顶层列下的“请假”和”加班“。
输出结果如下:
考勤管理
请假 加班
0 0 0
1 0 5
2 0 0
3 0 0
4 2 7
结合多个条件进行筛选
我们还可以结合多个条件进行筛选,例如,选择“职务”为程序员中 早退 次数大于 0 的员工:
# 筛选“销售”部门中迟到次数大于 0 的员工
leave_early_data = df.loc[
(df[('基础信息', '职务')] == '程序员') &
(df[('考勤管理', '早退')] >= 0)
]
print(leave_early_data)
输出结果如下:
员工 基础信息 考勤管理
Unnamed: 0_level_1 部门 职务 工号 迟到 早退 请假 外出 加班
3 赵六 研发部 程序员 4 4 2 0 0 0
4 钱七 研发部 程序员 5 0 3 2 4 7
筛选的灵活性
通过使用切片和筛选方法,用户可以灵活地从多层级数据中提取所需的信息。例如,在进行员工考勤分析时,我们可以快速获取特定考勤类别、时间段或特定客户群体的具体数据。这种灵活性使得数据分析过程更为高效,并能快速响应业务需求。
小结
本节介绍了如何使用 MultiIndex 和 .loc[] 对多层级表头的数据进行切片和筛选。我们可以根据业务需求选择特定的列,结合不同条件进行筛选,方便分析不同维度的数据。这些工具为我们提供了灵活且高效的数据提取方法,特别适合在数据集复杂的业务场景中使用。
5. 多层级表头的重构与扁平化
在处理带有多层级表头的Excel数据时,有时需要将表头扁平化,以便于后续的操作和分析。通过将多层级表头拼接成一个单层表头,可以有效地简化数据结构。
扁平化表头代码示例
import pandas as pd
# 读取Excel文件并指定表头为多层级
df = pd.read_excel('demo.xlsx', header=[0, 1])
# 使用扁平化方式将多层级表头合并
df.columns = ['_'.join(col).strip() for col in df.columns.values]
# 显示处理后的DataFrame
print(df)
上述代码会将表头中的多层级转化为以下形式的单层表头:
员工 基础信息_部门 基础信息_职务 ... 考勤管理_请假 考勤管理_外出 考勤管理_加班
0 张三 行政部 经理 ... 0 0 0
1 李四 行政部 助教 ... 0 1 5
2 王五 行政部 助理 ... 0 0 0
3 赵六 研发部 程序员 ... 0 0 0
4 钱七 研发部 程序员 ... 2 4 7
扁平化表头的应用场景
表头扁平化的操作特别适用于需要对数据进行进一步的分析、可视化或者保存为简单格式(如CSV)的场景。通过将复杂的多层级表头转化为便于操作的单层级表头,我们可以更轻松地进行列选择、筛选、分组等常见的数据处理操作。
总结
本文详细介绍了如何使用 MultiIndex 和 .loc[] 方法处理多层级 Excel 表头。我们学习了如何读取带有多层级表头的 Excel 文件,精确提取和筛选数据,以及如何将多层级表头扁平化以便于后续处理。
通过掌握这些技术,你将能够在数据分析过程中高效地处理复杂的 Excel 文件,提升工作效率。
后话
本次分享到此结束,
see you~~
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【Pandas】使用 pandas 处理多层级 Excel 表头的实用指南

发表评论 取消回复