《LIGHTWEIGHT NEURAL APP CONTROL》
用于app控制的轻量级神经网络
摘要
输入是一个文本目标和一系列过去的移动感知,比如截图和相应的UI树,来生成精确的动作。
针对智能手机固有的计算限制,我们在LiMAC中引入了一个小型Action Transformer(AcT),它与微调的视觉-语言模型(VLM)相结合,用于实时决策和任务执行。
我们在两个开源移动控制数据集上评估了LiMAC,展示了我们的小型形态因数方法相对于Florence2和Qwen2-VL等开源VLM的微调版本的优越性能。
具体来说,与微调后的VLM相比,LiMAC将整体动作准确度提高了多达19%,与prompt-engineering基线相比提高了多达42%。
前言
手机代理:这些智能体可以让用户轻松完成各种任务,包括安排约会、发送信息、购买物品和预订航班。
基本上,应用助手通过观察用户指令并逐步与智能手机的用户界面交互——例如,点击、滚动、输入文本等——来完成任务。
然而,由于智能手机的计算资源有限,这些代理人必须优化效率,使用内存占用小、处理速度快的轻量级模型。
(1)最近的进展已经利用基础模型开发出了应用程序代理,这些代理能够理解自然语言指令,并在智能手机界面内执行复杂的用户命令。
(2)为了解决这些限制,我们提出了一种门控架构,它结合了一个轻量级的变压器网络和一个小型的微调VLM。任务描述和智能手机状态首先由一个紧凑的模型(约5亿个参数、0.5B)处理,该模型有效地处理了大多数操作。对于需要自然语言理解的动作,比如编写短信或查询搜索引擎,会调用VLM来生成所需的文字。平均每个任务只需要3秒钟——并且提高了准确性。
(3)在提出的架构(轻量级多模态应用控制,或LiMAC)中,初始处理阶段由动作变换器(AcT)管理,主要负责确定满足用户命令所需的动作类型。 AcT首先根据智能手机界面的当前状态和任务描述预测动作类型,如点击、输入文本或滚动。对于大多数动作类型,如点击和滚动,AcT会自主执行任务。为了预测点击操作的目标,我们使用AcT输出和每个用户界面(UI)元素嵌入之间的对比目标。关于预测动作类型的具体方法以及处理点击动作的处理方式,分别在第3.3节和第3.5节中详细说明。
(4)然而,当AcT预测的动作类型为input-text或open-app,需要更深入的先验知识和对自然语言细微差别的理解时,LiMAC会将选择的动作类型和用户的目标传递给微调过的VLM,以生成合适的文本内容。这种分工使得AcT能够处理简单的交互,同时利用VLM的高级功能来处理更复杂的文本生成任务,确保系统保持资源效率的同时,能够提供复杂响应。在第3.4节中详细描述了在应用代理领域集成和微调VLM的过程。
论文的4个主要贡献:
(1)我们提出了LiMAC,这是一种应用程序代理的架构,它通过将轻量级变压器与微调的VLM相结合,来平衡效率和自然语言理解。
(2)我们还引入了AcT,这是LiMAC的一个子模块,旨在高效预测动作类型和UI元素交互,其特点是具有新颖的点击预测对比目标。
(3)我们对两个开源的视觉-语言模型(VLMs)进行了微调和评估,这些模型专门用于处理基于文本的操作。我们微调后的VLM在性能上可与GPT-4o方法相媲美,甚至超越它,而参数数量却少于20亿(2B)。
(4)我们展示了实验结果,证明与基于GPT-4o的和微调的VLM应用代理相比,LiMAC可以提升任务执行速度和精度——速度最高快30倍,准确度提高40%。
结论
总之,我们提出了LiMAC,一个轻量级的框架,旨在处理应用程序控制任务。
LiMAC从每个手机屏幕截图中提取UI元素,并使用专门的视觉和文本模块对其进行编码。
然后,这些UI元素编码作为嵌入向量传递给AcT,AcT预测下一个动作的类型和规格。
AcT关注动作的两个关键方面:预测动作是点击时的动作类型和目标元素。对于需要文本生成的动作,LiMAC使用微调的VLM来确保成功完成。
我们对比LiMAC与六个基于最新基础模型的基线方法,并在两个开源数据集上进行评估。结果表明,LiMAC在训练和推理所需计算时间显著减少的情况下,性能仍能超过这些基线。这证明LiMAC能够在计算能力有限的设备上完成任务处理。
所提出方法的主要限制之一是有限的训练数据。LiMAC分别只在13K和18K个场景上进行了AndroidControl和AitW的训练。缺乏预训练进一步阻碍了模型在更复杂任务上提高性能的能力。
未来,我们打算通过引入在线学习技术,如强化学习,来提升模型的性能。在本工作中展示的初始训练阶段后,LiMAC 可以与 Android 模拟器互动来生成更多数据。
通过使用合适的奖励函数,甚至利用GPT-4来评估生成的轨迹并分配奖励(Bai et al., 2024),我们可以微调LiMAC以提高任务完成率。
重要图
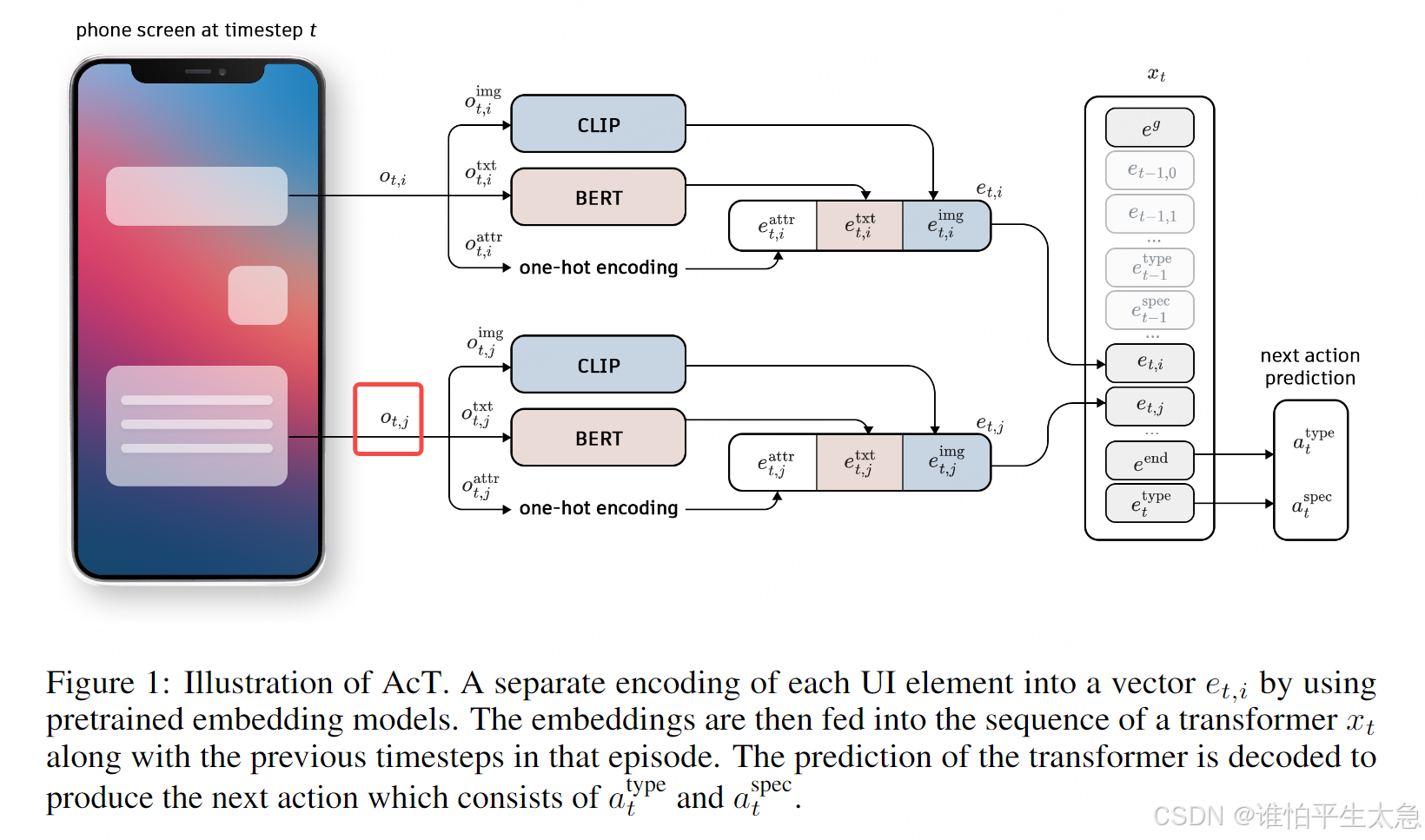
图1
图中红框中 t表示timestep, j表示 j-th UI元素(就是widget、或者某个控件)、o表示这个状态的观测结果,img指的是 与UI元素相对应的图像、 txt指的是 与UI元素相对应的文本、 attr指的是 UI元素的相关属性,如是否可点击
next action predict中的 a_t 指的是 第t步的动作,type 对应 动作类型、 spec 对应 动作的规格说明(规格根据操作类型有所不同:对于点击操作,规格可能表示目标UI元素;对于输入操作,它将包含要输入的文本。)
重要表
表3
在AitW和AndroidControl数据集上,不同模块组合的动作类型、点击目标和文本的准确性。LiMAC在两个数据集中都获得了最佳的动作类型准确性,在AitW中也获得了最佳的点击目标准确性,而我们微调过的Florence2则在文本预测方面表现出色。
未完待续
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 论文阅读:华为的LiMAC

发表评论 取消回复