论文阅读笔记:Automated Creation of Digital Cousins for Robust Policy Learning
论文:https://arxiv.org/abs/2410.07408
代码:https://digital-cousins.github.io
1 背景
1.1 问题
在真实世界中开发和训练机器人策略模型可能是不安全和成本高昂的,并且难以扩展到多样性的环境中。模拟学习是一个有吸引力的替代方案,因为它提供了一个廉价的和潜在的无限合成数据源。不幸的是,仅在模拟数据上训练的策略需要虚拟到真实的迁移,并且经常受到模拟环境和现实环境之间的语义和物理差异的影响。
缓解这一问题的一个广泛的方法是通过增加合成数据的分布来提高策略的鲁棒性,如随机化视觉语义或物理参数,然而这些方法可能缺乏合成交互数据的质量。
显式地建模一个特定真实世界环境的完全交互副本(数字孪生)可以捕获原始环境中的细致入微的细节,但需要耗费大量的人力来生成。并且在这些环境中训练的机器人策略是针对单个真实世界实例进行优化的,不能泛化到原始场景的变化。
1.2 提出的办法
为了解决虚拟到真实方法的两个极端的局限性,作者首先提出了数字表亲的概念。作者将数字表亲定义为一种虚拟的资产或场景。与数字孪生不同,他没有显式地对现实世界的对应物进行建模,但仍然表现出相似的集合和语义可供性。例如,我们希望一个真实柜子的数字表亲共享类似的把手和抽屉布局,即使两者的材料或细节不同,真实世界厨房的一个虚拟表亲可能包括类似的家具对象排列,即使个别模型稍有不同。
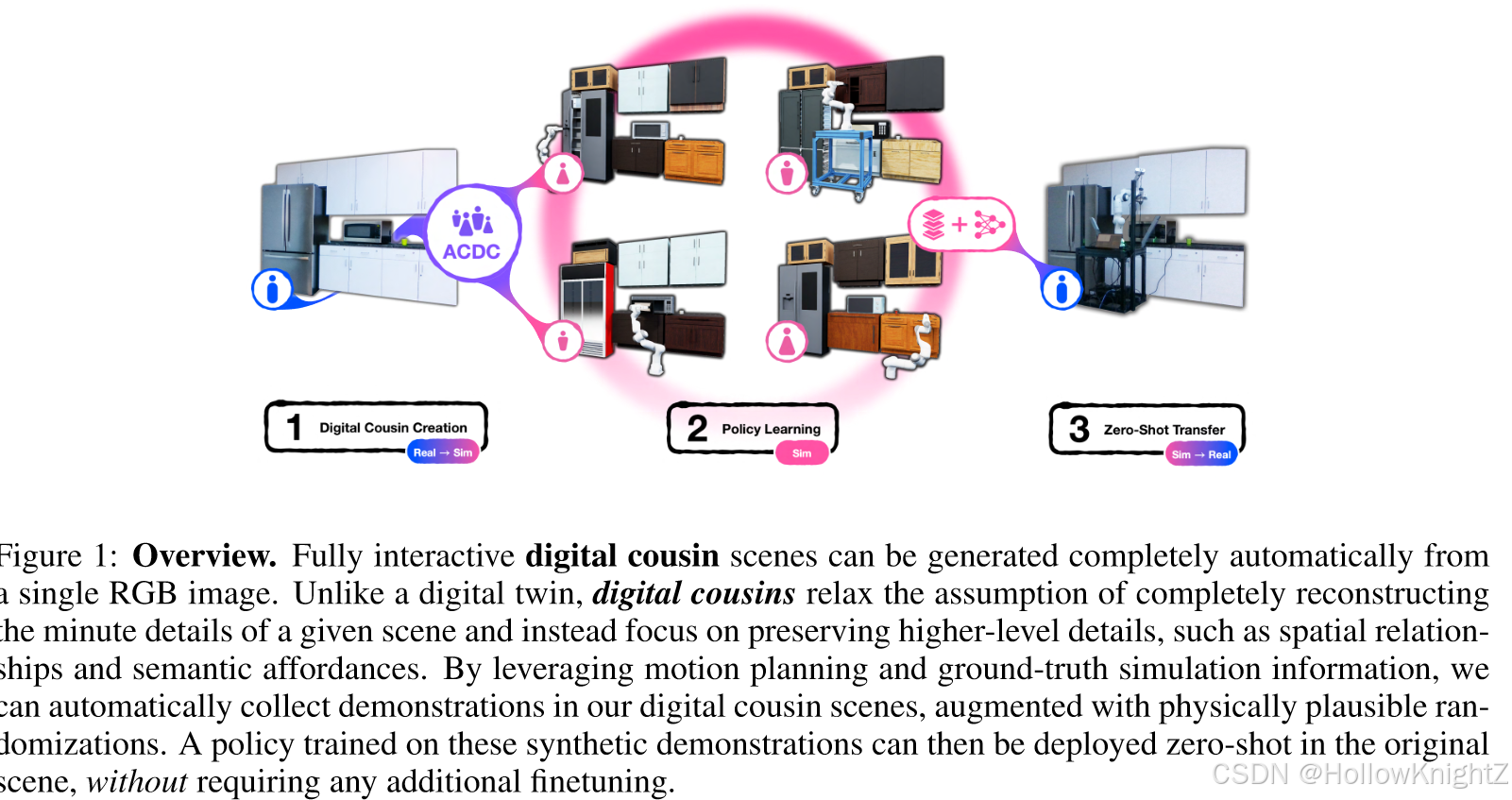
与程序化生成的场景不同,数字表亲在根本上是基于真实世界的场景,类似于数字孪生。然而与数字孪生不同的是,数字表亲放宽了重建精确副本的要求,包含数字表亲的场景转而专注于保留高级场景属性,如空间对象布局,关键的语义和物理可供性。并且如名称所示,对于单个真实世界的场景,可以生成多个不同的表亲,但只能存在单个数字孪生。因此这种放宽有两个目的:(a)减少手动微调的需要,以保证一定的保真度,从而实现数字表亲的完全自动化创作。(b)通过提供一组增强的场景来训练机器人策略,从而对精确的原始场景中的变化具有更好的鲁棒性。
本文介绍了一种新颖的自动创建数组表亲的方法ACDC,该方法可以在真实到模拟的设置中使用完全自动化的端到端,其中真实世界图像生成的数字表亲可以用于在原始场景中的零样本训练。ACDC利用DINOv2作为衡量给定的真实世界资产和候选数字资产之间的相似性,因为它已经被证明可以从不同的图像集合中编码相关的集合和空间信息,并且作者认为具有低特征嵌入距离的资产是给定的真实世界对象的数字表亲。
2 创新点
-
提出了数字表亲的概念,并提出了一种数字表亲自动化生成方法ACDC
-
提供了一个自动方法来训练数字表亲中的模拟策略。
-
证明了在数字表亲中训练的机器人操作策略的性能,并在模拟和显式场景进行策略,效果优于数字孪生策略。
3 方法
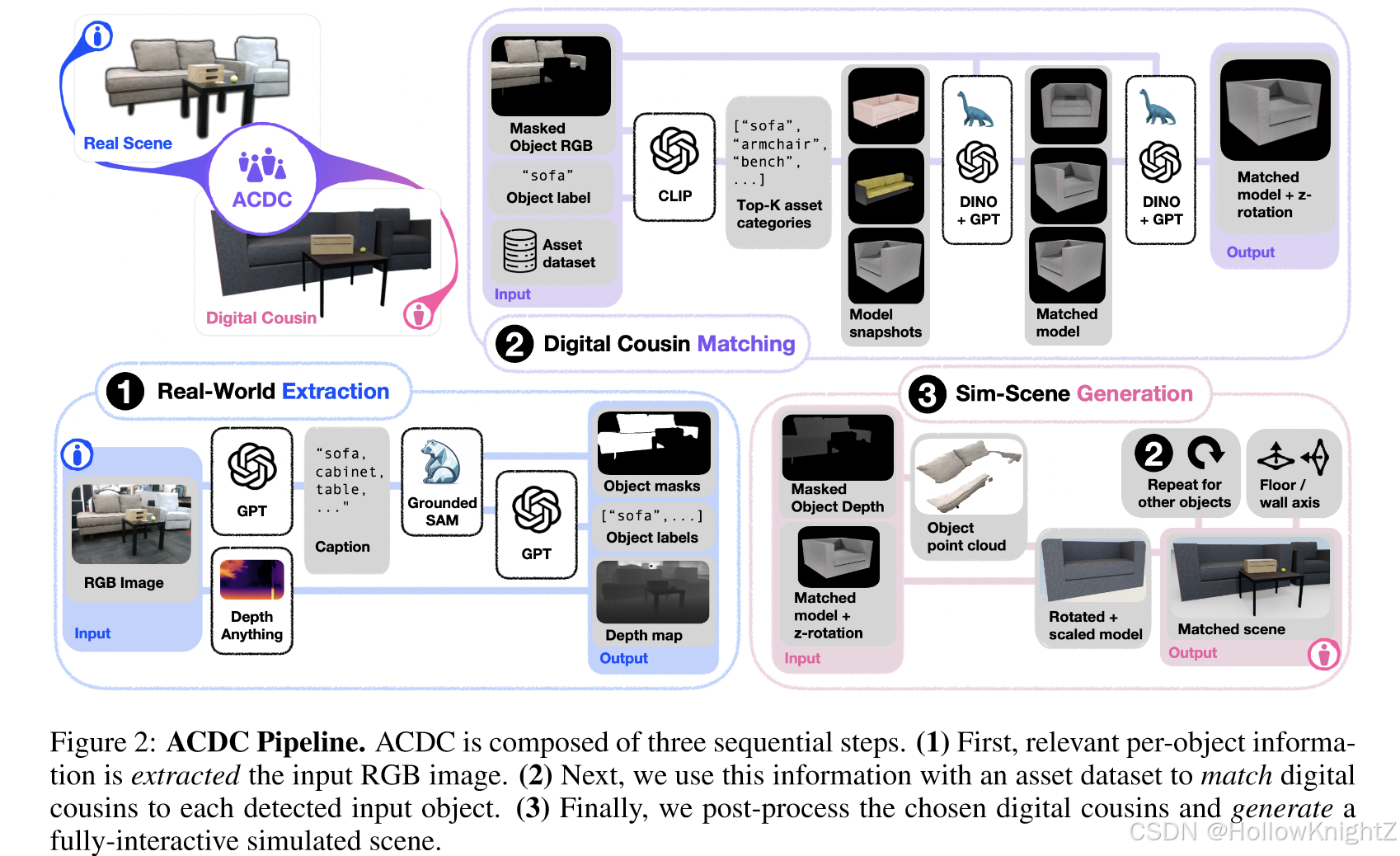
ACDC是从单张RGB图像中生成完全交互的模拟场景的pipeline,包含三个步骤:
-
提取步骤,从原始图像中提取相关的对象掩码
-
匹配步骤,从原始场景中提取单个对象,并为其选择数字表亲
-
生成步骤,将选择的数字表亲进行后处理并一起编译,以形成完全交互的,物理上可行的数字表亲场景。方法如图2。
4 模块
4.1 真实世界提取
ACDC只需要一个由内参矩阵为 K K K 的已标定相机拍摄的单幅RGB图像 X X X 作为输入。为了从输入图像中提取单个目标掩码,首先提示 GPT-4 为 X X X 中观察到的所有目标生成标题 c j , j ∈ { 1 , … , M } c_j,j∈\{1,…,M\} cj,j∈{1,…,M},然后将标题传递给 Grounded SAM-v2,与 X 一起生成一组检测到的目标掩码 m i , i ∈ { 1 , … , N } m_i,i∈\{1,…,N\} mi,i∈{1,…,N}。为了重新同步 Grounded SAM-v2 和GPT-4 之间的标题,作者重新提示 GPT-4 从前面生成的标题列表中为每个掩码选择准确的标签 l i ∈ { c j } j = 1 M l_i∈\{c_j\}_{j=1}^M li∈{cj}j=1M。
同时我们还需要一个深度图,以便在生成场景的时候正确的定位和重新缩放匹配的数字表亲。深度相机应用广泛,但不能准确地捕获反射面,也无法在户外使用。为了减轻这些限制,作者利用一个先进的单目深度估计模型 DepthAnything-v2 从 X X X 中估计相应的深度图 D D D。然后提取点云 KaTeX parse error: Undefined control sequence: \* at position 4: P=D\̲*̲K^{-1},并利用单个物体掩膜 m i m_i mi 生成 P P P 中的点 p i p_i pi 和对应于该物体的 X X X 中的像素 x i x_i xi 的子集,从而得到一组物体表示 { o i = l i , m i , p i , x i } i = 1 N \{o_i={l_i,m_i,p_i,x_i}\}^N_{i=1} {oi=li,mi,pi,xi}i=1N。
4.2 数字表亲匹配
给定提取的对象表示 o i o_i oi,通过将虚拟资产数据集进行分层搜索,以匹配数字表亲。假设数据集中的每个数字资产 i i i 都被赋予了一个语义意义的类别 t i t_i ti,并且每个资产模型都有多个再不同方向下拍摄的快照 { i i s } i = 1 N s n a p \{i_{is}\}_{i=1}^{N_{snap}} {iis}i=1Nsnap,其中包括一个具有代表性的快照 I i I_i Ii,形成资产元祖 { a i = ( t i , I i , { i i s } s = 1 N s n a p ) } i = 1 N a s s e r t s \{a_i=(t_i,I_i,\{i_{is}\}_{s=1}^{N_{snap}})\}_{i=1}^{N_{asserts}} {ai=(ti,Ii,{iis}s=1Nsnap)}i=1Nasserts,其中 N s n a p N_{snap} Nsnap 是快照数, N a s s e r t s N_{asserts} Nasserts 是资产数。本文使用了BEHAVIOR-1K资产,在实际中,本文的方法可以使用任何满足上述性质的资产数据集。
对于给定的输入对象表示 o i o_i oi,首先通过计算标签 l i l_i li 与所有资产类别名称 { t i } i = 1 N a s s e r t s \{t_i\}_{i=1}^{N_{asserts}} {ti}i=1Nasserts 之间的 CLIP 相似度得分来选择匹配的候选类别,选择前 k c a t k_{cat} kcat 个最接近的类别。选定给定的类别,通过计算掩码对象 RGB x i x_i xi 和代表性模型快照 I j I_j Ij 之间的 DINOv2 特征嵌入距离,在这些类别中的所有资产模型中选择潜在的数字表亲候选者。在选择 k c a n d k_{cand} kcand 个对象后,重新计算每个候选对象的个体快照 { i j s } s = 1 N s n a p \{i_{js}\}_{s=1}^{N_{snap}} {ijs}s=1Nsnap 上的 DINOv2 距离,并最终选择最接近的 k c o u s k_{cous} kcous 个表亲,其中每个被选择的表亲由一个特定的虚拟资产 A c A_c Ac 和基于所选择的快照的相应方向 q c q_c qc 组成。
4.3 模拟场景生成
将匹配的表情编译成物理上合理的数字表亲场景,对于给定的输入对象信息 o i o_i oi 和对应的匹配表亲信息 ( A c , q c ) (A_c,q_c) (Ac,qc),将资产的边界框中心放置在对应的输入对象点云 p i p_i pi 的质心处,然后重新缩放以对其 p i p_i pi 的范围。作者还从提取步骤获得的点云中你和地板和墙面,并查询 GPT-4 以确定是否应该将任何物体安装在地板或墙上。最后,作者去穿透所有的物体,使得场景在物理上是稳定的。
4.4 政策学习
一旦有了一组数组表亲,就可以在这些环境中训练机器人策略,这些环境可以转移到其他看不见的设置中。虽然本文的数字表亲可以接受多种训练范式,如强化学习和模仿人类学习,但作者选择从脚本演示中重点模仿学习,因为这种范式不需要人类演示,而是可以与类似的完全自主的ACDC pipeline进行端到端的耦合。
5 实验
数字表亲场景重建的质量评估。
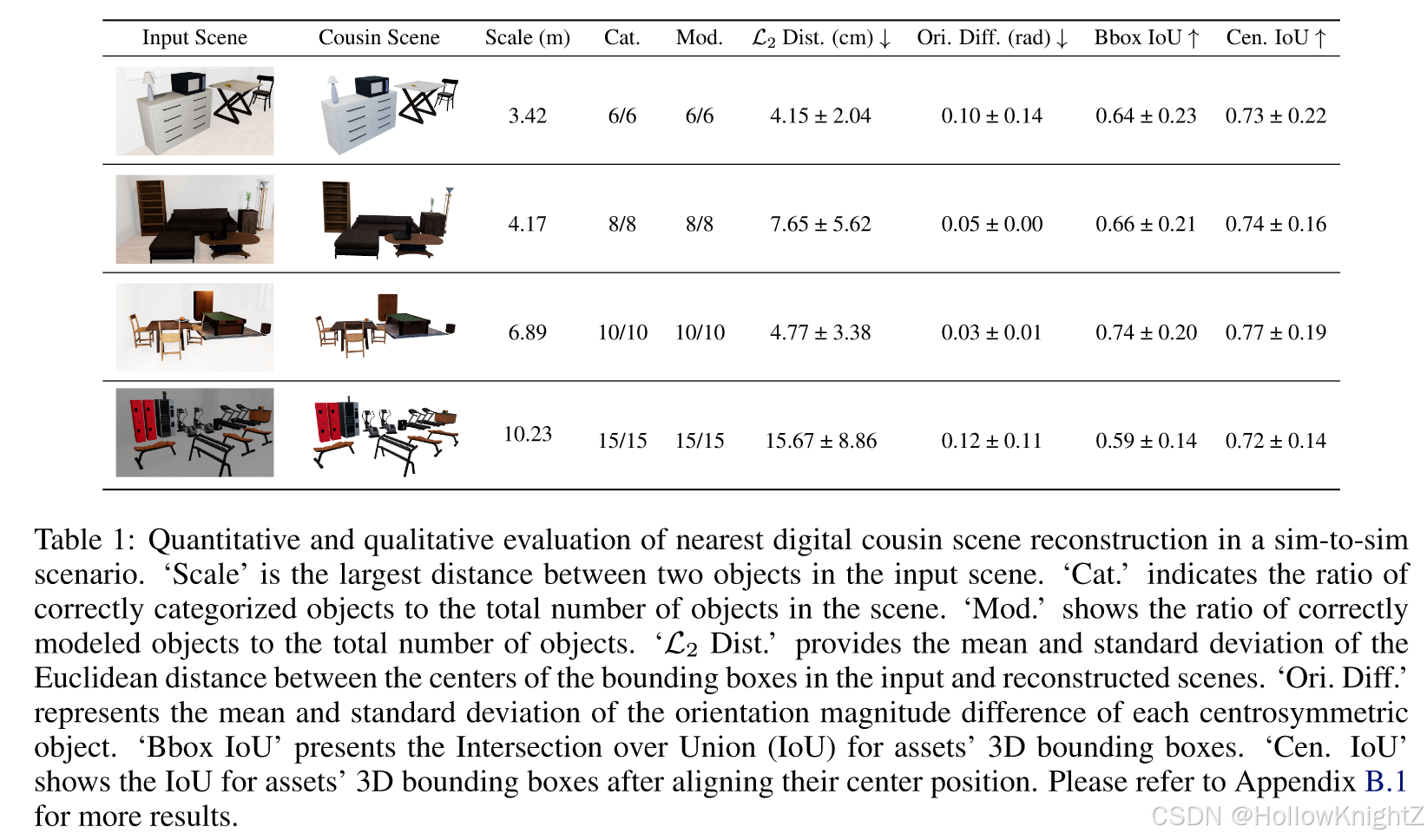
一些生成结果。

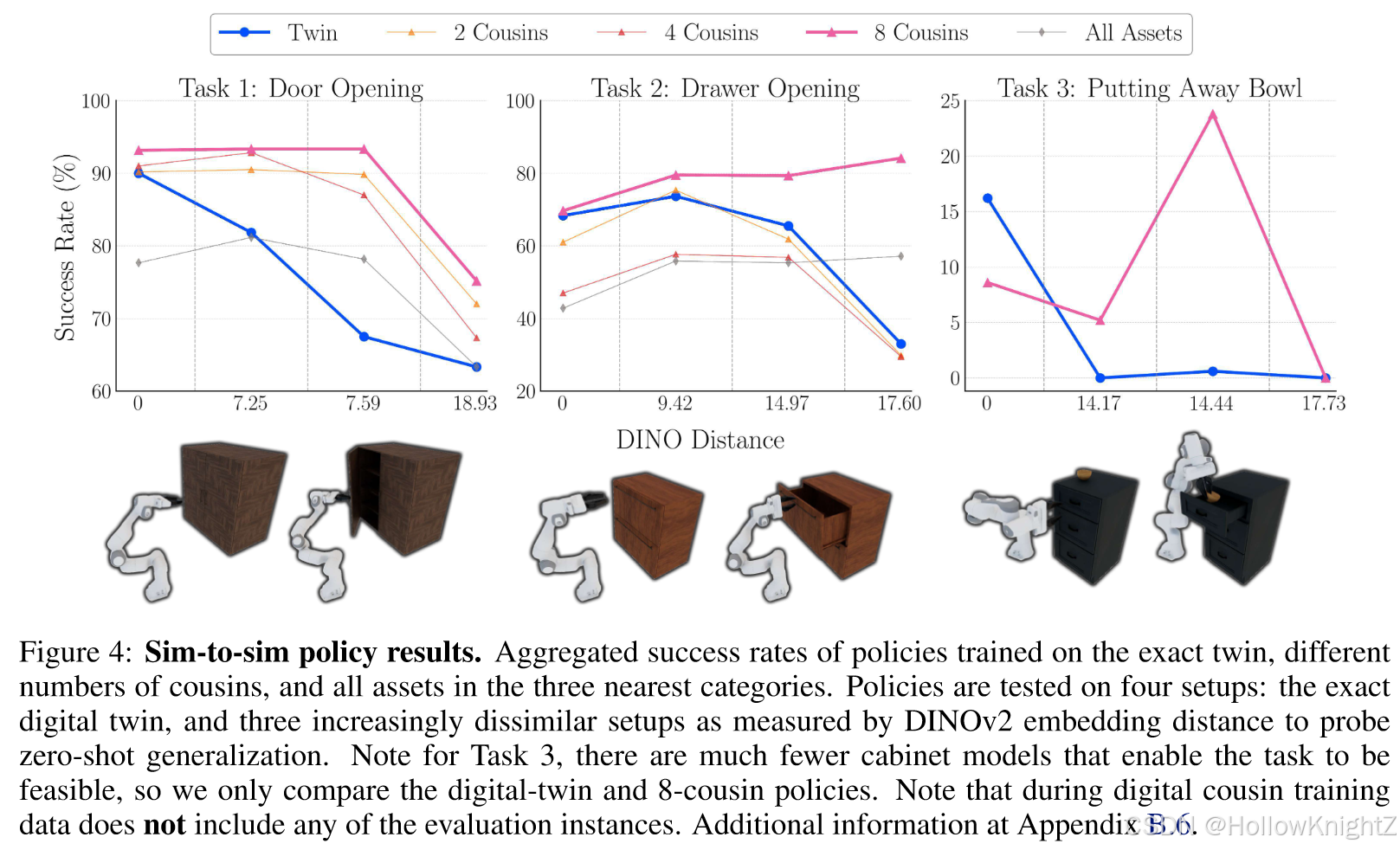
机器人动作的成功率和训练资产与真实场景的 DINOv2 距离的关系。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 论文阅读笔记:Automated Creation of Digital Cousins for Robust Policy Learning

发表评论 取消回复