2024-ECCV-ControlNet++: Improving Conditional Controls with Efficient Consistency Feedback
ControlNet++:通过有效的一致性反馈改进条件控制
作者:Ming Li, Taojiannan Yang, Huafeng Kuang, Jie Wu, Zhaoning Wang, Xuefeng Xiao, and Chen Chen
单位:Center for Research in Computer Vision, University of Central Florida, ByteDance
论文地址:2024-ECCV-ControlNet++: Improving Conditional Controls with Efficient Consistency Feedback
摘要
为了增强文本到图像传播模型的可控性,现有的努力(如 ControlNet)结合了基于图像的条件控制。在本文中,我们揭示了现有方法在生成与图像条件控制一致的图像方面仍然面临重大挑战。为此,我们提出了 ControlNet++,这是一种通过明确优化生成的图像和条件控制之间的像素级循环一致性来改进可控生成的新方法。具体而言,对于输入条件控制,我们使用预先训练的判别奖励模型来提取生成的图像的相应条件,然后优化输入条件控制和提取的条件之间的一致性损失。一种直接的实现是从随机噪声生成图像然后计算一致性损失,但这种方法需要存储多个采样时间步的梯度,从而导致大量的时间和内存成本。为了解决这个问题,我们引入了一种有效的奖励策略,通过添加噪声故意扰乱输入图像,然后使用单步去噪图像进行奖励微调。这避免了与图像采样相关的大量成本,从而可以更有效地进行奖励微调。大量实验表明,ControlNet++ 显著提高了各种条件控制下的可控性。例如,对于分割掩码、线条艺术边缘和深度条件,它分别比 ControlNet 提高了 11.1% mIoU、13.4% SSIM 和 7.6% RMSE。所有代码、模型、演示和组织数据都已在我们的 Github Repo 上开源。
关键词:可控生成 · 扩散模型 · ControlNet
1. 引言
扩散模型 [12, 43, 50] 的出现和改进,以及大规模图像文本数据集的引入 [48, 49],催化了文本到图像生成的重大进步。尽管如此,正如谚语 “一图胜千言” 所传达的那样,仅通过语言来准确而详细地描述图像是一项挑战,这一困境也困扰着现有的文本到图像的扩散模型 [43, 46]。为此,许多研究侧重于将分割掩码等条件控制合并到文本到图像的扩散模型中 [22, 30, 37, 62, 63]。尽管这些方法多种多样,但核心目标仍然是通过明确的基于图像的条件控制促进更准确、可控的图像生成。

实现可控的图像生成可能需要从头开始重新训练扩散模型 [37, 43],但这对计算的要求很高,而且缺乏大型公共数据集 [63]。鉴于此,一种可行的策略是对预先训练的文本到图像模型 [23, 61] 进行微调或引入可训练模块 [30, 62, 63],如 ControlNet [63]。然而,尽管这些研究探索了文本到图像扩散模型中可控性的可行性 [30, 62, 63] 并扩展了各种应用 [22, 23, 37],但在实现精确和细粒度的控制方面仍然存在很大差距。如图 1 所示,现有的可控生成方法(例如 ControlNet [63] 和 T2I-Adapter [30])仍然难以准确生成与输入图像条件一致的图像。例如,T2I-Adapter-SDXL 在所有生成的图像中始终产生错误的额头皱纹,而 ControlNet v1.1 引入了许多错误的细节。遗憾的是,目前的努力缺乏提高可控性的具体方法,这阻碍了该研究领域的进展。
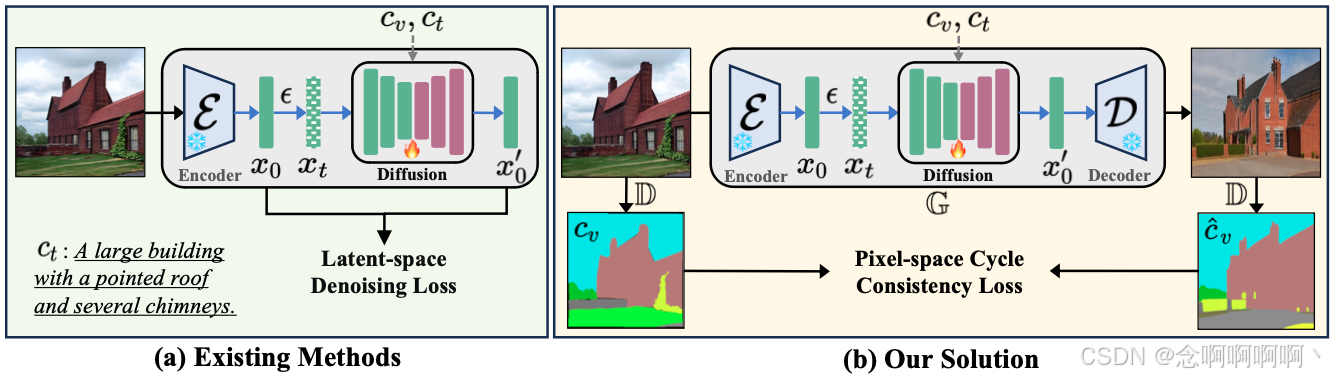
为了解决这个问题,我们将基于图像的可控生成建模为图像转换任务 [17],从输入条件控制到输出生成的图像。受 CycleGAN [71] 的启发,我们建议使用预先训练的判别模型从生成的图像中提取条件,并直接优化循环一致性损失以获得更好的可控性。这个想法是,如果我们将图像从一个域转换到另一个域(条件 c v → c_v\to cv→ 生成的图像 x 0 ′ x^′_0 x0′),然后再转换回来(生成的图像 x 0 ′ → x^′_0\to x0′→ 条件 c v ′ c^′_v cv′),我们应该到达我们开始的地方( c v ′ = c v c^′_v=c_v cv′=cv),如图 2 所示。例如,给定一个分割掩码作为条件控制,我们可以使用现有方法(如 Control-Net [63])来生成相应的图像。然后,可以通过预先训练的分割模型获得这些生成图像的预测分割掩码。理想情况下,预测的分割掩码和输入的分割掩码应该是一致的。因此,循环一致性损失可以表示为输入和预测分割掩码之间的每像素分类损失。与现有的相关研究 [27, 30, 37, 63, 65] 不同,这些研究通过在潜在空间去噪过程中引入条件控制来隐式实现可控性,我们的方法明确地优化了像素空间的可控性以获得更好的性能,如图 3 所示。
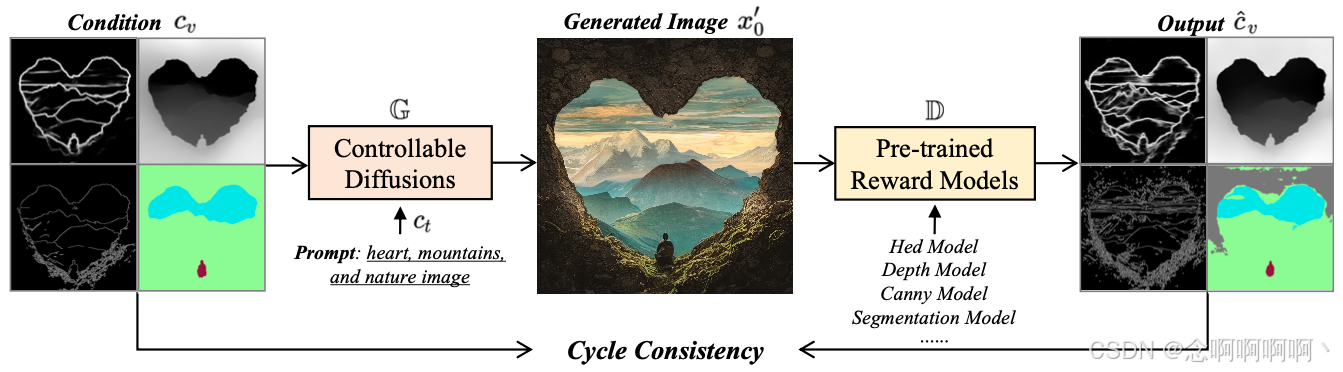
Net [63] 生成相应的图像。然后可以通过预先训练的分割模型获得这些生成图像的预测分割蒙版。理想情况下,预测的分割蒙版和输入的分割蒙版应该是一致的。因此,循环一致性损失可以表示为输入和预测分割蒙版之间的每像素分类损失。与现有的相关工作 [27, 30, 37, 63, 65] 通过在潜在空间去噪过程中引入条件控制来隐式实现可控性不同,我们的方法明确优化了像素空间的可控性以获得更好的性能,如图 3 所示。
为了在扩散模型的背景下实现像素级损失,一种直观的方法是执行扩散模型的推理过程,从随机高斯噪声开始并执行多个采样步骤以获得最终生成的图像,遵循最近的研究重点是通过人工反馈来提高图像质量 [11, 36, 60]。然而,多次采样会导致效率问题,并且需要在每个时间步存储梯度,因此会消耗大量时间和 GPU 内存。我们证明从随机高斯噪声开始采样是不必要的。相反,通过直接向训练图像添加噪声以扰乱它们与输入条件控制的一致性,然后使用单步去噪图像重建一致性,我们可以进行更有效的奖励微调。我们的贡献总结如下:
- 新见解(New Insight):我们发现,现有的可控生成工作在可控性方面仍然表现不佳,生成的图像明显偏离输入条件,并且缺乏明确的改进策略。
- 一致性奖励反馈(Consistency Reward Feedback):我们表明,预先训练的判别模型可以作为强大的视觉奖励模型,以循环一致性的方式提高可控扩散模型的可控性。
- 高效奖励微调(Efficient Reward Fine-tuning):我们破坏输入图像和条件之间的一致性,并启用单步去噪进行高效奖励微调,避免图像采样造成的时间和内存开销。
- 评估和有希望的结果(Evaluation and Promising Results):我们对各种条件控制下的可控性进行了统一和公开的评估,并证明 ControlNet++ 全面优于现有方法。
2. 相关工作
2.1 基于扩散的生成模型
[50] 中提出的扩散概率模型取得了长足进步 [12, 19, 25],这要归功于训练和采样策略的迭代改进 [18, 51, 52]。为了减轻训练扩散模型的计算需求,潜在扩散 [43] 将像素空间扩散过程映射到潜在特征空间。在文本到图像合成领域,扩散模型 [31, 35, 40, 41, 43, 46] 集成了 UNet [44] 去噪器和来自预训练语言模型(如 CLIP [38] 和 T5 [39])的文本嵌入之间的交叉注意机制,以促进合理的文本到图像生成。此外,扩散模型通过操纵输入 [40]、编辑交叉注意 [16] 和微调模型 [45] 应用于图像编辑任务 [3, 14, 24, 29]。尽管扩散模型具有惊人的能力,但语言是一种稀疏且高度语义化的表示,不适合描述密集、低语义的图像。此外,现有方法 [35, 43] 仍然难以理解详细的文本提示,这对可控生成 [63] 构成了严峻挑战。
2.2 可控的文本到图像扩散模型
为了在预训练的文本到图像扩散模型中实现条件控制,ControlNet [63] 和 T2I-Adapter [30] 引入了额外的可训练模块来引导图像生成。此外,最近的研究采用了各种提示工程 [27, 61, 64] 和交叉注意约束 [6, 23, 58] 来实现更有规律的生成。一些方法还探索了单个扩散模型中的多条件或多模式生成 [21, 37, 65],或者专注于基于实例的可控生成 [54, 69]。然而,尽管这些方法探索了可行性和应用,但仍然缺乏一种明确的方法来增强各种控制下的可控性。此外,现有的工作通过扩散模型的去噪过程隐式地学习可控性,而我们的 Control-Net++ 以显式的循环一致性方式实现了这一点,如图 3 所示。
2.3 语言和视觉奖励模型
奖励模型的训练目的是评估生成模型的结果与人类期望的契合程度,其量化结果将用于促进生成模型实现更好、更可控的生成。它通常在 NLP 任务中使用人类反馈强化学习(RLHF)进行训练 [10, 32, 53],最近已扩展到视觉领域,以提高文本到图像扩散模型的图像质量 [1, 11, 13, 36, 56, 60]。然而,图像质量是一个极其主观的指标,充满了个人偏好,需要创建具有人类偏好的新数据集 [26, 55, 56, 60] 并训练奖励模型 [36, 55, 60]。与当前研究中追求具有主观人类偏好的全局图像质量不同,我们的目标是更细粒度和客观的可控性目标。此外,与人工反馈相比,获得人工智能反馈更具成本效益。
3. 方法
在本节中,我们首先在第 3.1 节中介绍扩散模型的背景。在第 3.2 节中,我们讨论如何设计可控扩散模型的循环一致性损失以增强可控性。最后,在第 3.3 节中,我们研究了直接解决方案的效率问题,并相应地提出了一种有效的奖励策略,该策略利用单步去噪图像进行一致性损失,而不是从随机噪声中采样图像。
3.1. 初步
扩散模型 [18] 通过逐渐向输入数据 x 0 x_0 x0 添加噪声来定义扩散前向过程 q ( x t ∣ x 0 ) q\left(x_t|x_0\right) q(xt∣x0) 的马尔可夫链:
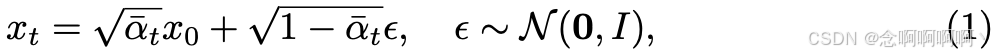
其中 ϵ \epsilon ϵ 是从高斯分布中采样的噪声图, α ^ : = ∏ s = 0 t α s \hat{\alpha}:= {\textstyle \prod_{s=0}^{t}}\alpha_s α^:=∏s=0tαs。\alpha_t=1-\beta_t 是时间步长 t t t 的可微函数,由 DDPM [18] 等去噪采样器确定。为此,扩散训练损失可以表示为:
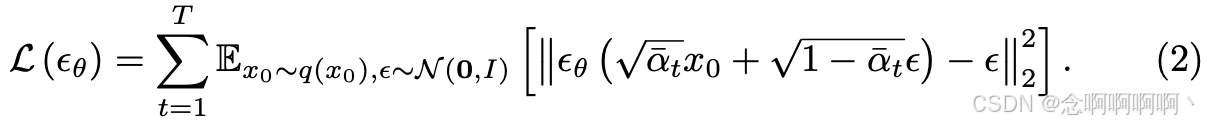
在可控生成 [30, 63] 的背景下,给定图像条件 c v c_v cv 和文本提示 c t c_t ct,时间步 t t t 的扩散训练损失可以重写为:
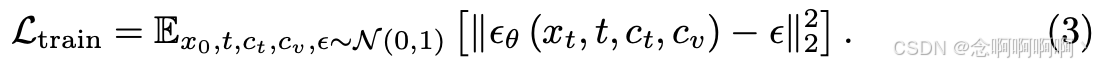
在推理过程中,给定一个随机噪声 x T ∼ N ( 0 , I ) x_T\sim \mathcal{N} \left ( \mathbf{0} ,\ \mathbf{I} \right ) xT∼N(0, I),我们可以通过逐步去噪过程预测最终去噪图像 x 0 x_0 x0 [18]:
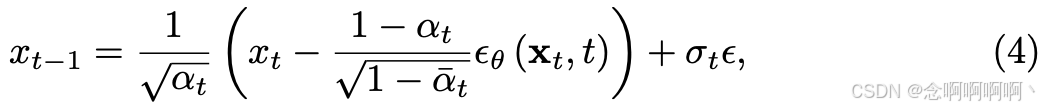
其中 ϵ θ \epsilon_\theta ϵθ 表示 U-Net [44] 在时间步 t t t 处预测的噪声,参数为 θ \theta θ, σ t = 1 − α ˉ t − 1 1 − α ˉ t β t \sigma_{t}=\frac{1-\bar{\alpha}_{t-1}}{1-\bar{\alpha}_{t}} \beta_{t} σt=1−αˉt1−αˉt−1βt 是后验高斯分布 p θ ( x 0 ) p_\theta\left(x_0\right) pθ(x0) 的方差。
3.2 具有一致性反馈的奖励可控性
由于我们将可控性建模为输入条件与生成图像之间的一致性,因此我们可以通过判别奖励模型自然地量化这一结果。一旦我们量化了生成模型的结果,我们就可以基于这些量化结果以统一的方式对各种条件控制进行进一步优化,以实现更可控的生成。
更具体地说,我们最小化输入条件 c v c_v cv 与生成图像 x 0 ′ x^′_0 x0′ 的相应输出条件 c ^ v \hat{c}_v c^v 之间的一致性损失,如图 2 所示。奖励一致性损失可以表示为:
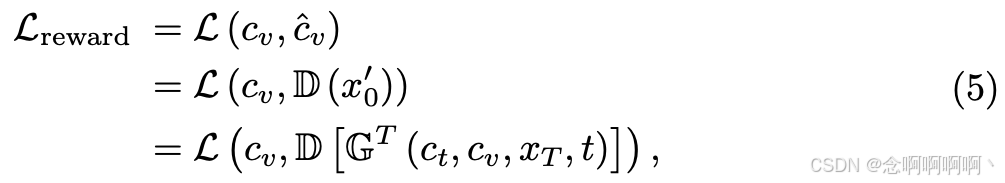
其中 G T ( c t , c v , x T , t ) \mathbb{G}^{T}\left(c_{t}, c_{v}, x_{T}, t\right) GT(ct,cv,xT,t) 表示模型执行 T T T 个去噪步骤从随机噪声 x T x_T xT 生成图像 x 0 ′ x^′_0 x0′ 的过程,如图 4(a) 所示。这里, L \mathcal{L} L 是一个抽象的度量函数,对于不同的视觉条件可以采用不同的具体形式。例如,在使用分割蒙版作为输入条件控制的背景下, L \mathcal{L} L 可以是每像素交叉熵损失。奖励模型 D \mathcal{D} D 也取决于条件,我们使用 UperNet [57] 来处理分割蒙版条件。损失函数和奖励模型的细节总结在补充材料中。
除了奖励损失之外,我们还在等式 3 中采用了扩散训练损失,以确保原始图像生成能力不受影响,因为它们具有不同的优化目标。最后,总损失是 L t r a i n \mathcal{L}_{train} Ltrain 和 L r e w a r d \mathcal{L}_{reward} Lreward 的组合:
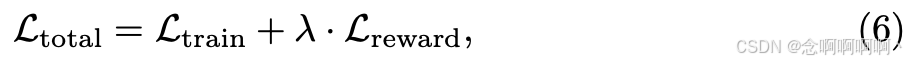
其中 λ \lambda λ 是调整奖励损失权重的超参数。通过这种方法,一致性损失可以指导扩散模型如何在不同的时间步进行采样以获得与输入控制更一致的图像,从而增强可控性。尽管如此,直接应用这种奖励一致性在现实环境中仍然存在效率方面的挑战。
3.3 高效奖励微调
为了实现像素空间一致性损失 L r e w a r d \mathcal{L}_{reward} Lreward,需要使用最终扩散图像 x 0 x_0 x0 来计算奖励模型中的奖励一致性。由于现代扩散模型(如稳定扩散 [43])需要多个步骤(例如 50 个步骤)来渲染完整图像,因此在现实环境中直接使用这种解决方案是不切实际的:(1)需要多次耗时的采样才能从随机噪声中获取图像。(2)为了启用梯度反向传播,我们必须在每个时间步存储梯度,这意味着 GPU 内存使用量将随着时间步数线性增加。以 ControlNet 为例,当批量大小为 1 且混合精度为 FP16 时,单个去噪步骤和存储所有训练梯度所需的 GPU 内存约为 6.8GB。如果我们使用 DDIM [51] 调度程序进行 50 步推理,则需要大约 340GB 的内存来对单个样本执行奖励微调,这在当前的硬件能力下几乎是不可能实现的。虽然可以通过采用低秩自适应(LoRA)[11, 20]、梯度检查点 [7, 11] 或停止梯度 [60] 等技术来减少 GPU 内存消耗,但生成图像所需的采样步骤数量导致的效率下降仍然很大,不容忽视。因此,需要一种有效的奖励微调方法。
与图 4(a) 中所示的通过随机噪声 x T x_T xT 扩散来获得最终图像 x 0 x_0 x0 不同,我们提出了一种单步高效奖励策略。具体来说,我们不是从噪声中随机采样,而是向训练图像 x 0 x_0 x0 添加噪声,从而通过执行等式 1 中的扩散前向过程 q ( x t ∣ x 0 ) q\left(x_t|x_0\right) q(xt∣x0) 明确扰乱扩散输入 x t ′ x^′_t xt′ 与其条件控制 c v c_v cv 之间的一致性。我们在图 4(b) 中将此过程演示为扰动一致性,其过程与标准扩散训练过程相同。当添加的噪声 ϵ \epsilon ϵ 相对较小时,我们可以通过对扰动图像 x t ′ x^′_t xt′ 执行单步采样3来预测原始图像 x 0 ′ x^′_0 x0′ [18]:
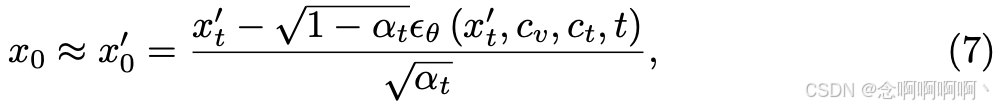
然后我们直接利用去噪后的图像 x 0 ′ x^′_0 x0′ 进行奖励微调:
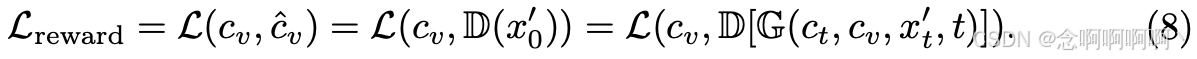
本质上,添加噪声的过程会破坏输入图像与其条件之间的一致性。然后,等式 8 中的奖励微调指示扩散模型生成可以重建一致性的图像,从而增强其在生成过程中遵循条件的能力。
3 我们在补充材料中提供了更详细的证明。
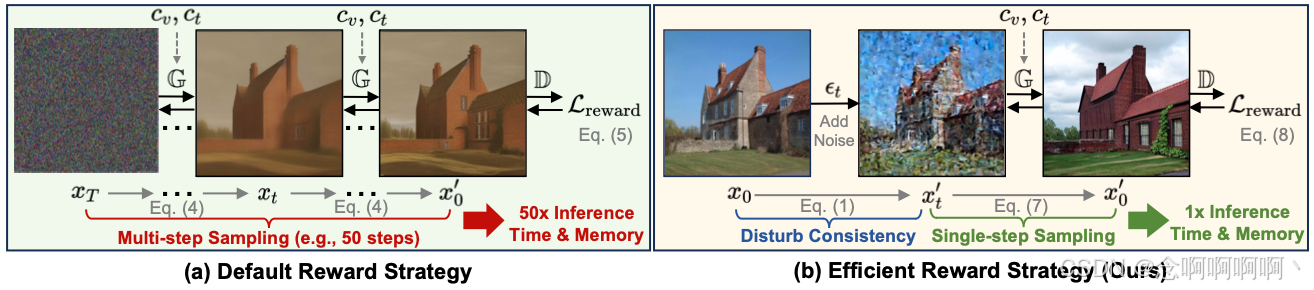
请注意,这里我们避免了公式 5 中的采样过程。最终,损失是扩散训练损失和奖励损失的组合:
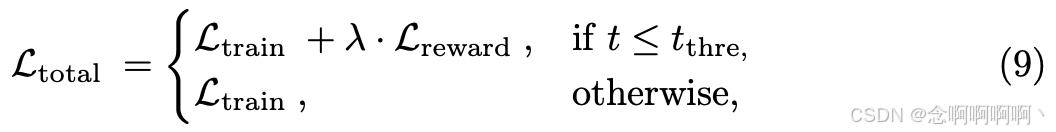
其中 t t h r e t_{thre} tthre 表示时间步长阈值,它是一个超参数,用于确定是否应使用带噪声的图像 x t x_t xt 进行奖励微调。我们注意到,较小的噪声 ϵ \epsilon ϵ(即相对较小的时间步长 t t t)会扰乱一致性并导致有效的奖励微调。当时间步长 t t t 很大时, x t x_t xt 更接近随机噪声 x T x_T xT,直接从 x t x_t xt 预测 x 0 ′ x^′_0 x0′ 会导致严重的图像失真。我们高效奖励的优势在于, x t x_t xt 既可用于训练扩散模型,也可用于奖励扩散模型,而无需多次采样带来的时间和 GPU 内存成本,从而显著提高奖励微调阶段的效率。
在奖励微调阶段,我们冻结预先训练的判别奖励模型和文本到图像模型,并且仅按照原始实现更新 ControlNet,从而确保生成能力不受影响。我们还观察到,仅使用奖励损失会导致图像失真,这与先前研究 [60] 得出的结论一致。
4. 实验
4.1 实验设置
条件控制和数据集。鉴于现有的生成模型文本-图像配对数据集无法提供准确的条件控制数据对 [48, 49],例如图像分割对,我们努力为不同的任务选择特定的数据集,以提供更精确的图像标签数据对。更具体地说,ADE20K [67, 68] 和 COCOStuff [4] 用于 ControlNet [63] 之后的分割掩码条件。对于 canny 边缘图、hed 边缘图、线性图和深度图条件,我们利用 UniControl [37] 提出的 MultiGen-20M 数据集,它是 LAION-Aesthetics [48] 的一个子集。对于没有文本标题的数据集(例如 ADE20K),我们使用 MiniGPT-4 [70] 生成图像标题,指令为 “请用一句话简要描述这张图片”。所有数据集和方法的训练和推理分辨率均为 512×512。详细信息请参阅补充材料。
评估和指标。我们在每个相应数据集的训练集上训练 ControlNet++,并在验证数据集上评估所有方法。为了公平比较,所有实验均在 512×512 分辨率下进行评估。对于每种条件,我们通过测量输入条件与从扩散模型的生成图像中提取的条件之间的相似性来评估可控性。对于语义分割和深度图控制,我们分别使用 mIoU 和 RMSE 作为评估指标,这是相关研究领域的常见做法。对于边缘任务,我们对硬边缘(canny 边缘)使用 F1-Score,因为它可以看作是 0(非边缘)和 1(边缘)的二元分类问题,并且具有严重的长尾分布,遵循边缘检测中的标准评估 [59]。用于评估的阈值对于 OpenCV 为 (100, 200),对于 Kornia 实现为 ( 0.1 , 0.2 ) \left(0.1,\ 0.2\right) (0.1, 0.2)。 SSIM 度量用于软边缘条件控制(即,hed 边缘和线性边缘),遵循先前的研究 [65]。对于 ControlNet++,我们使用 UniPC [66] 采样器和 20 个去噪步骤来生成带有原始文本提示的图像,遵循 ControlNet v1.1 [63],没有任何负面提示。对于 ControlNet 和我们的方法之外的其他方法,我们利用它们的开源代码来生成图像,并在相同数据下进行公平评估,而无需更改它们的推理配置,例如推理步骤数或去噪采样器。
基线。我们的评估主要集中在 T2I-Adapter [30]、ControlNet v1.1 [63]、GLIGEN [27]、Uni-ControlNet [65] 和 UniControl [37] 上,因为这些方法在可控文本到图像扩散模型领域具有开创性,并为各种图像条件提供公共模型权重。为确保评估的公平性,所有方法都使用相同的图像条件和文本提示。虽然大多数方法都采用用户友好的 SD1.5 作为可控生成的文本到图像模型,但我们观察到最近有一些基于 SDXL [35] 的模型。因此,我们还报告了 ControlNet-SDXL 和 T2I-Adapter-SDXL 的可控性结果。请注意,此处提到的 ControlNet-SDXL 不是 ControlNet [63] 中正式发布的模型。
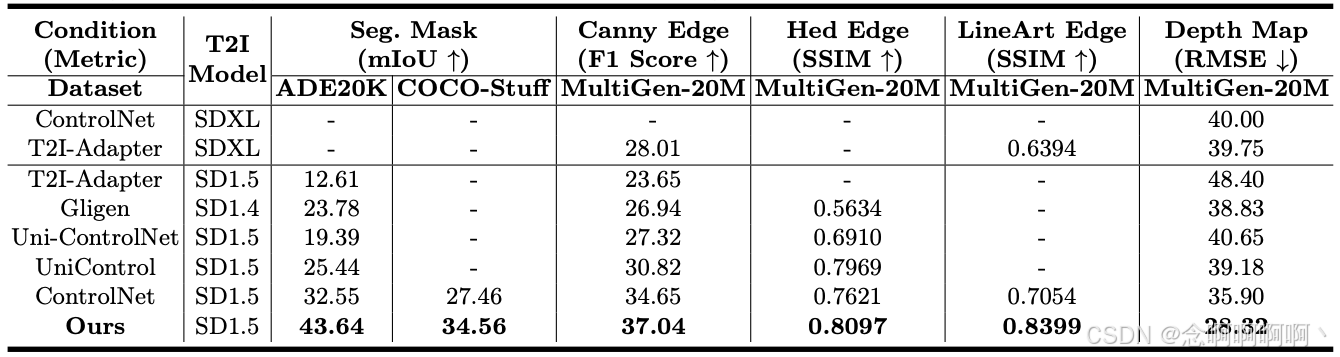
可控性与最新方法的比较。实验结果如表 1 所示,可总结为以下观察结果:(1)现有方法在可控性方面仍然表现不佳,难以实现精确的控制生成。例如,当前方法(即 ControlNet)在分割掩码条件下生成的图像仅实现 32.55 mIoU,这与 Mask2Former 分割模型 [8] 的相同评估下在真实数据集上 50.7 mIoU 的性能相差甚远。(2)我们的 ControlNet++ 在各种条件控制下的可控性方面明显优于现有作品。例如,在深度图条件下,它与以前的最新方法相比实现了 11.1% 的 RMSE 改进;(3)对于可控扩散模型,文本到图像主干的强度不会影响其可控性。如表所示,基于 SDXL 的 [35] ControlNet 和 T2I-Adapter 虽然在某些特定任务上具有更好的可控性,但提升幅度并不大,且并未显著优于基于 SD 1.5 的 [43] 。
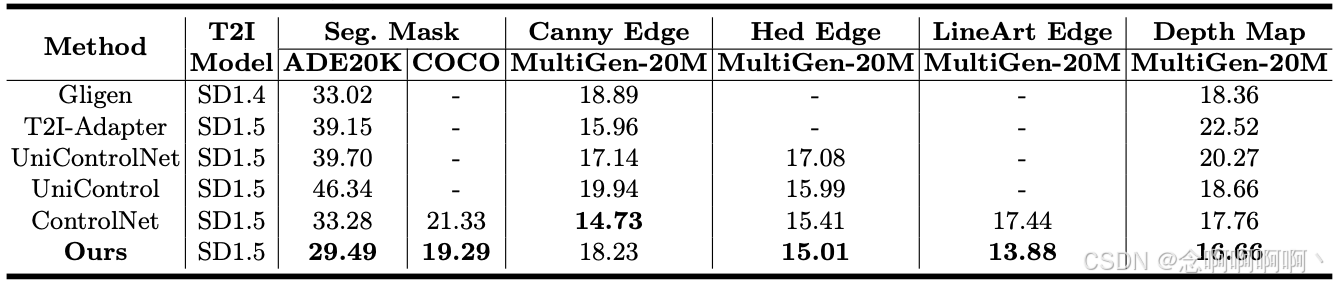
图像质量与最先进方法的比较。为了验证提高可控性是否会导致图像质量下降,我们在表 2 中报告了不同方法在各种条件生成任务下的 FID(Fréchet Inception Distance)指标。我们发现,与现有方法相比,ControlNet++ 在大多数情况下通常表现出更好的 FID 值,这表明我们的方法在增强条件控制的可控性的同时,不会导致图像质量下降。这也可以在图 6 中观察到。我们在补充材料中提供了更多视觉示例。
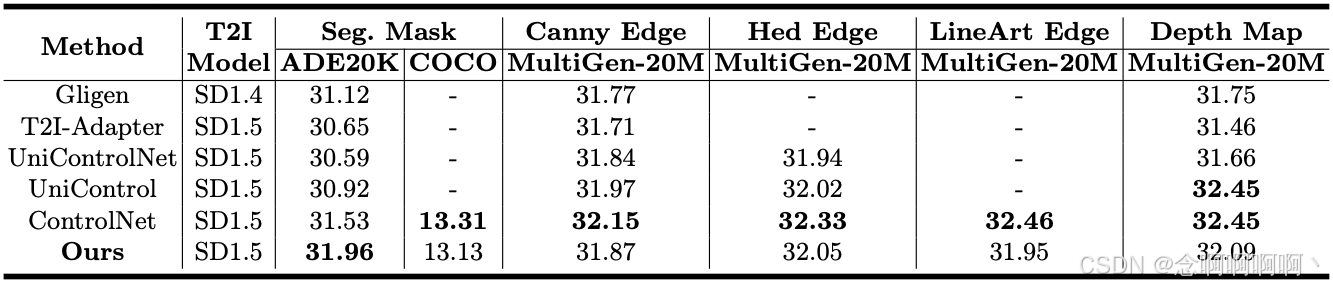
CLIP 分数与最先进方法的比较。我们的 ControlNet++ 旨在使用基于图像的条件提高扩散模型的可控性。考虑到对文本可控性的潜在不利影响,我们使用 CLIP-Score 指标在不同数据集上评估了各种方法来测量生成的图像和输入文本之间的相似性。如表 3 所示,与现有方法相比,ControlNet++ 在多个数据集上实现了相当或更优异的 CLIP-Score 结果。这表明我们的方法不仅显著增强了条件可控性,而且还保留了原始模型的文本到图像生成能力。
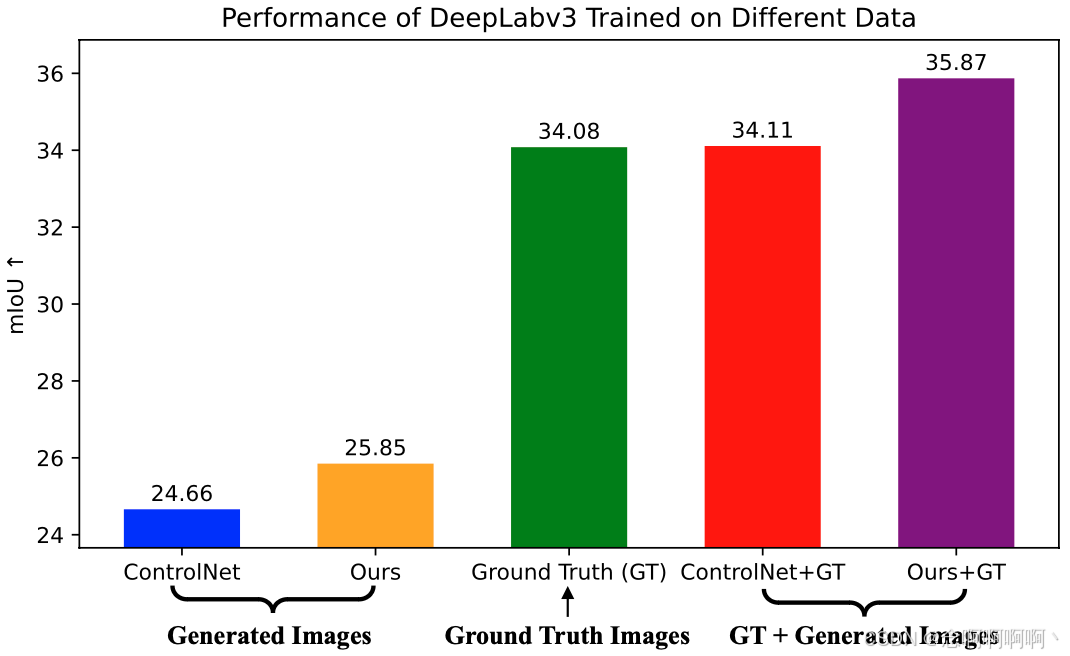
生成图像的有效性。为了进一步验证我们在可控性方面的改进及其影响,我们使用生成的图像以及真实的人工注释标签来创建一个新的数据集,用于从头开始训练判别模型。请注意,与用于训练判别模型的原始数据集的唯一区别在于,我们用可控扩散模型生成的图像替换了图像,同时保持标签不变。如果生成模型表现出良好的可控性,则构建的数据集的质量将更高,从而能够训练更强大的模型。
具体来说,我们在具有 MobileNetv2 主干 [5] 的 DeepLabv3 上对 ADE20K [67, 68] 数据集进行实验。我们使用标准训练数据集(20210 个训练样本)来训练判别模型,并使用验证数据集(5000 个评估样本)进行评估。我们在图 5 中展示了实验结果,在我们的图像上训练的分割模型比基线结果(ControlNet)高出 1.19 mIoU。请注意,这种改进在分割任务中非常显著。例如,Mask2Former [8] 在语义分割中将之前的 SOTA MaskFormer [9] 提高了约 1.1 mIoU。除了仅在生成的数据集上进行实验外,我们还将生成的数据与真实数据相结合以训练分割模型。实验结果表明,用 ControlNet 生成的数据增强真实的地面实况数据不会带来额外的性能改进(34.11 v.s. 34.08)。相反,用我们的生成数据增强真实数据会显著提高性能(+1.76 mIoU)。
定性比较。图 6 和图 7 在不同条件控制下对我们的 ControlNet++ 与之前最先进的方法进行了定性比较。当给出相同的输入文本提示和基于图像的条件控制时,我们观察到现有方法通常会生成与图像条件不一致的区域。例如,在分割蒙版生成任务中,其他方法通常会在墙壁上产生多余的相框,导致从生成的图像中提取的分割蒙版与输入不匹配。在深度条件下也会发生类似的情况,其他方法无法准确表示不同手指的深度。相比之下,ControlNet++ 生成的图像与输入深度图保持了良好的一致性。


损失设置。在图 8 中,我们发现保持原始扩散训练过程对于保持生成图像的质量和可控性至关重要。仅依靠像素级一致性损失会导致严重的图像失真,而同时使用该损失和扩散训练损失来训练模型可以增强可控性而不会影响图像质量。
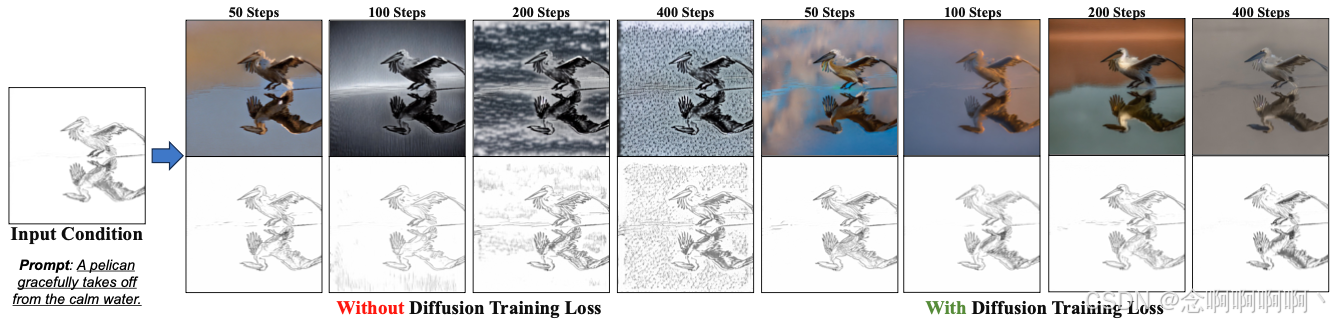
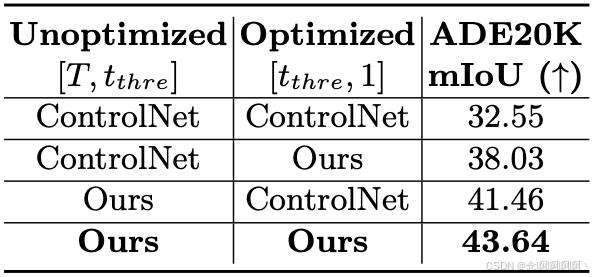
高效奖励微调的通用性。虽然奖励微调只用于一小部分时间步,但它会更新 ControlNet 的所有参数,因此有助于更多时间步在采样期间提高可控性。为了证明这一点,我们将采样过程分为两部分:未优化的时间步 [ T , t t h r e ] [T,\ t_{thre}] [T, tthre] 和优化的时间步 [ t t h r e , 1 ] [t_{thre},\ 1] [tthre, 1],并使用 ControlNet 和我们的模型进行交叉推理,在 ControlNet 之后进行 20 步采样。表 4 表明,我们在较少时间步长 [ t t h r e , 1 ] [t_{thre},\ 1] [tthre, 1] 上执行的奖励微调可以推广到较大的时间步长 [ T , t t h r e ] [T,\ t_{thre}] [T, tthre]。
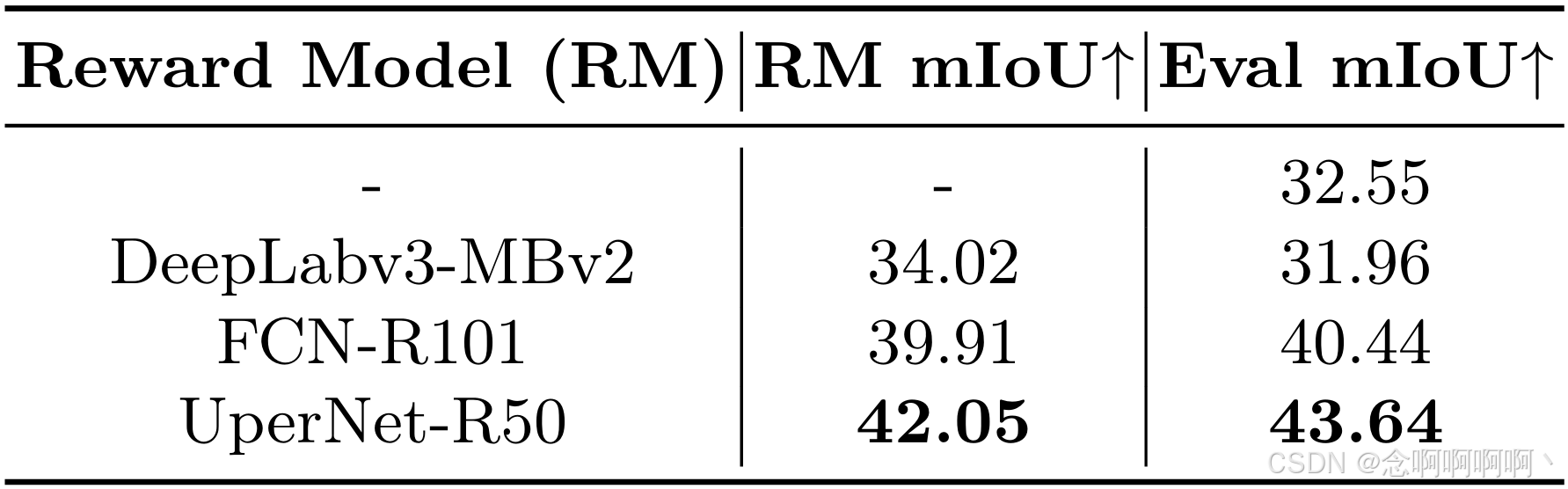
不同奖励模型的选择。我们在表 5 中展示了不同奖励模型的有效性,所有评估结果(即表中的 Eval mIoU)均由最强大的分割模型 Mask2Former [8] 在 ADE20K 数据集上以 56.01 mIoU 进行评估。我们尝试了三种不同的奖励模型,包括以 MobileNetv2 [47] 为骨干的 DeepLabv3 [5](DeepLabv3-MBv2)、以 ResNet-101 [15] 为骨干的 FCN [28](FCN-R101)和以 ResNet-50 为骨干的 UperNet [57]。结果表明,更强大的奖励模型可为可控扩散模型带来更好的可控性。
5. 讨论
如何使 Hed/LineArt 边缘提取方法可微分?Hed 和 LineArt 边缘提取模型是没有不可微分操作的神经网络。只需修改前向代码即可实现可微分性。某些条件(例如 Box/Sketch/Pose)不可用。我们的奖励微调利用了预先训练的 ControlNet 和可微分的奖励模型。目前,缺乏针对对象边界框的预训练 ControlNet 和针对草图的可微分奖励模型。在现有的姿势模型中,存在不可微分的操作,例如 NMS 和关键点分组。我们将如何将一致性奖励扩展到更多条件的问题留待将来的工作。文本提示的影响。我们讨论了不同类型的文本提示(无提示、冲突提示和完美提示)如何影响最终结果。如图 9 所示,当文本提示为空或与图像条件控制存在语义冲突时,ControlNet 通常难以生成准确的内容。而我们的 ControlNet++ 则可以在各种文本提示场景下,生成符合输入条件控制的图像。

6. 结论
本文从定量和定性两个角度论证了现有可控生成研究仍未能实现精确的条件控制,导致生成图像与输入条件不一致。为了解决这个问题,我们引入了 ControlNet++,它使用预训练的判别奖励模型以循环一致性的方式显式地优化输入条件和生成图像之间的一致性,这与现有通过潜在扩散去噪隐式实现可控性的方法不同。我们还提出了一种新颖而有效的奖励策略,通过向输入图像添加噪声然后进行单步去噪来计算一致性损失,从而避免了从随机高斯噪声中采样所带来的大量计算和内存成本。在多个条件控制下的实验结果表明,ControlNet++ 在不影响图像质量和图文对齐的情况下显著提高了可控性,为可控视觉生成提供了新的见解。
参考文献
- Black, K., Janner, M., Du, Y., Kostrikov, I., Levine, S.: Training diffusion models with reinforcement learning. arXiv preprint arXiv:2305.13301 (2023)
- Bradski, G.: The OpenCV Library. Dr. Dobb’s Journal of Software Tools (2000)
- Brooks, T., Holynski, A., Efros, A.A.: Instructpix2pix: Learning to follow image editing instructions. In: CVPR (2023)
- Caesar, H., Uijlings, J., Ferrari, V.: Coco-stuff: Thing and stuff classes in context. In: CVPR (2018)
- Chen, L.C., Papandreou, G., Schroff, F., Adam, H.: Rethinking atrous convolution for semantic image segmentation. arXiv preprint arXiv:1706.05587 (2017)
- Chen, M., Laina, I., Vedaldi, A.: Training-free layout control with cross-attention guidance. arXiv preprint arXiv:2304.03373 (2023)
- Chen, T., Xu, B., Zhang, C., Guestrin, C.: Training deep nets with sublinear memory cost. arXiv (2016)
- Cheng, B., Misra, I., Schwing, A.G., Kirillov, A., Girdhar, R.: Masked-attention mask transformer for universal image segmentation. In: CVPR (2022)
- Cheng, B., Schwing, A., Kirillov, A.: Per-pixel classification is not all you need for semantic segmentation. NeurIPS (2021)
- Chowdhery, A., Narang, S., Devlin, J., Bosma, M., Mishra, G., Roberts, A., Barham, P., Chung, H.W., Sutton, C., Gehrmann, S., et al: Palm: Scaling language modeling with pathways. arXiv preprint arXiv:2204.02311 (2022)
- Clark, K., Vicol, P., Swersky, K., Fleet, D.J.: Directly fine-tuning diffusion models on differentiable rewards. arXiv preprint arXiv:2309.17400 (2023)
- Dhariwal, P., Nichol, A.: Diffusion models beat gans on image synthesis. NeurIPS (2021)
- Fan, Y., Watkins, O., Du, Y., Liu, H., Ryu, M., Boutilier, C., Abbeel, P., Ghavamzadeh, M., Lee, K., Lee, K.: Dpok: Reinforcement learning for fine-tuning text-to-image diffusion models. NeurIPS (2023)
- Gal, R., Alaluf, Y., Atzmon, Y., Patashnik, O., Bermano, A.H., Chechik, G., Cohen-or, D.: An image is worth one word: Personalizing text-to-image generation using textual inversion. In: ICLR (2023)
- He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR (2016)
- Hertz, A., Mokady, R., Tenenbaum, J., Aberman, K., Pritch, Y., Cohen-or, D.: Prompt-to-prompt image editing with cross-attention control. In: ICLR (2023)
- Hertzmann, A., Jacobs, C.E., Oliver, N., Curless, B., Salesin, D.H.: Image analogies. In: SIGGRAPH (2001)
- Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. NeurIPS (2020)
- Ho, J., Salimans, T.: Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598 (2022)
- Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: LoRA: Low-rank adaptation of large language models. In: ICLR (2022)
- Hu, M., Zheng, J., Liu, D., Zheng, C., Wang, C., Tao, D., Cham, T.J.: Cocktail: Mixing multi-modality controls for text-conditional image generation. NeurIPS (2023)
- Huang, L., Chen, D., Liu, Y., Shen, Y., Zhao, D., Zhou, J.: Composer: Creative and controllable image synthesis with composable conditions. In: ICML (2015)
- Ju, X., Zeng, A., Zhao, C., Wang, J., Zhang, L., Xu, Q.: Humansd: A native skeleton-guided diffusion model for human image generation. In: ICCV (2023)
- Kawar, B., Zada, S., Lang, O., Tov, O., Chang, H., Dekel, T., Mosseri, I., Irani, M.: Imagic: Text-based real image editing with diffusion models. In: CVPR (2023)
- Kingma, D., Salimans, T., Poole, B., Ho, J.: Variational diffusion models. NeurIPS (2021)
- Kirstain, Y., Polyak, A., Singer, U., Matiana, S., Penna, J., Levy, O.: Pick-a-pic: An open dataset of user preferences for text-to-image generation. arXiv preprint arXiv:2305.01569 (2023)
- Li, Y., Liu, H., Wu, Q., Mu, F., Yang, J., Gao, J., Li, C., Lee, Y.J.: Gligen: Open-set grounded text-to-image generation. In: CVPR (2023)
- Long, J., Shelhamer, E., Darrell, T.: Fully convolutional networks for semantic segmentation. In: CVPR (2015)
- Meng, C., He, Y., Song, Y., Song, J., Wu, J., Zhu, J.Y., Ermon, S.: Sdedit: Guided image synthesis and editing with stochastic differential equations. In: ICLR (2022)
- Mou, C., Wang, X., Xie, L., Zhang, J., Qi, Z., Shan, Y., Qie, X.: T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. arXiv preprint arXiv:2302.08453 (2023)
- Nichol, A.Q., Dhariwal, P., Ramesh, A., Shyam, P., Mishkin, P., Mcgrew, B., Sutskever, I., Chen, M.: Glide: Towards photorealistic image generation and editing with text-guided diffusion models. In: ICML (2022)
- Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., et al: Training language models to follow instructions with human feedback. NeurIPS (2022)
- Parmar, G., Zhang, R., Zhu, J.Y.: On aliased resizing and surprising subtleties in gan evaluation. In: CVPR (2022)
- von Platen, P., Patil, S., Lozhkov, A., Cuenca, P., Lambert, N., Rasul, K., Davaadorj, M., Wolf, T.: Diffusers: State-of-the-art diffusion models. https:// github.com/huggingface/diffusers (2022)
- Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952 (2023)
- Prabhudesai, M., Goyal, A., Pathak, D., Fragkiadaki, K.: Aligning text-to-image diffusion models with reward backpropagation. arXiv preprint arXiv:2310.03739 (2023)
- Qin, C., Zhang, S., Yu, N., Feng, Y., Yang, X., Zhou, Y., Wang, H., Niebles, J.C., Xiong, C., Savarese, S., et al: Unicontrol: A unified diffusion model for controllable visual generation in the wild. NeurIPS (2023)
- Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al: Learning transferable visual models from natural language supervision. In: ICML (2021)
- Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., Liu, P.J.: Exploring the limits of transfer learning with a unified text-to-text transformer. JMLR (2020)
- Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., Chen, M.: Hierarchical textconditional image generation with clip latents. arXiv preprint arXiv:2204.06125 (2022)
- Ramesh, A., Pavlov, M., Goh, G., Gray, S., Voss, C., Radford, A., Chen, M., Sutskever, I.: Zero-shot text-to-image generation. In: ICML (2021)
- Riba, E., Mishkin, D., Ponsa, D., Rublee, E., Bradski, G.: Kornia: an open source differentiable computer vision library for pytorch. In: CVPR (2020)
- Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: CVPR (2022)
- Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedical image segmentation. In: MICCAI (2015)
- Ruiz, N., Li, Y., Jampani, V., Pritch, Y., Rubinstein, M., Aberman, K.: Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In: CVPR (2023)
- Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E.L., Ghasemipour, K., Gontijo Lopes, R., Karagol Ayan, B., Salimans, T., et al: Photorealistic textto-image diffusion models with deep language understanding. NeurIPS (2022)
- Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., Chen, L.C.: Mobilenetv2: Inverted residuals and linear bottlenecks. In: CVPR (2018)
- Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C., Wightman, R., Cherti, M., Coombes, T., Katta, A., Mullis, C., Wortsman, M., Schramowski, P., Kundurthy, S., Crowson, K., Schmidt, L., Kaczmarczyk, R., Jitsev, J.: Laion-5b: An open large-scale dataset for training next generation image-text models. ArXiv (2022)
- Schuhmann, C., Vencu, R., Beaumont, R., Kaczmarczyk, R., Mullis, C., Katta, A., Coombes, T., Jitsev, J., Komatsuzaki, A.: Laion-400m: Open dataset of clip-filtered 400 million image-text pairs. ArXiv (2021)
- Sohl-Dickstein, J., Weiss, E., Maheswaranathan, N., Ganguli, S.: Deep unsupervised learning using nonequilibrium thermodynamics. In: ICML (2015)
- Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. In: ICLR (2021)
- Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Scorebased generative modeling through stochastic differential equations. In: ICLR (2021)
- Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al: Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288 (2023)
- Wang, X., Darrell, T., Rambhatla, S.S., Girdhar, R., Misra, I.: Instancediffusion: Instance-level control for image generation (2024)
- Wu, X., Hao, Y., Sun, K., Chen, Y., Zhu, F., Zhao, R., Li, H.: Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis. arXiv preprint arXiv:2306.09341 (2023)
- Wu, X., Sun, K., Zhu, F., Zhao, R., Li, H.: Better aligning text-to-image models with human preference. In: ICCV (2023)
- Xiao, T., Liu, Y., Zhou, B., Jiang, Y., Sun, J.: Unified perceptual parsing for scene understanding. In: ECCV (2018)
- Xie, J., Li, Y., Huang, Y., Liu, H., Zhang, W., Zheng, Y., Shou, M.Z.: Boxdiff: Textto-image synthesis with training-free box-constrained diffusion. In: ICCV (2023)
- Xie, S., Tu, Z.: Holistically-nested edge detection. In: ICCV (2015)
- Xu, J., Liu, X., Wu, Y., Tong, Y., Li, Q., Ding, M., Tang, J., Dong, Y.: Imagereward: Learning and evaluating human preferences for text-to-image generation. NeurIPS (2023)
- Yang, Z., Wang, J., Gan, Z., Li, L., Lin, K., Wu, C., Duan, N., Liu, Z., Liu, C., Zeng, M., et al: Reco: Region-controlled text-to-image generation. In: CVPR (2023)
- Ye, H., Zhang, J., Liu, S., Han, X., Yang, W.: Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models. arXiv preprint arXiv:2308.06721 (2023)
- Zhang, L., Rao, A., Agrawala, M.: Adding conditional control to text-to-image diffusion models. In: ICCV (2023)
- Zhang, T., Zhang, Y., Vineet, V., Joshi, N., Wang, X.: Controllable text-to-image generation with gpt-4. arXiv preprint arXiv:2305.18583 (2023)
- Zhao, S., Chen, D., Chen, Y.C., Bao, J., Hao, S., Yuan, L., Wong, K.Y.K.: Unicontrolnet: All-in-one control to text-to-image diffusion models. NeurIPS (2023)
- Zhao, W., Bai, L., Rao, Y., Zhou, J., Lu, J.: Unipc: A unified predictor-corrector framework for fast sampling of diffusion models. arXiv preprint arXiv:2302.04867 (2023)
- Zhou, B., Zhao, H., Puig, X., Fidler, S., Barriuso, A., Torralba, A.: Scene parsing through ade20k dataset. In: CVPR (2017)
- Zhou, B., Zhao, H., Puig, X., Xiao, T., Fidler, S., Barriuso, A., Torralba, A.: Semantic understanding of scenes through the ade20k dataset. IJCV (2019)
- Zhou, D., Li, Y., Ma, F., Yang, Z., Yang, Y.: Migc: Multi-instance generation controller for text-to-image synthesis. In: CVPR (2024)
- Zhu, D., Chen, J., Shen, X., Li, X., Elhoseiny, M.: Minigpt-4: Enhancing visionlanguage understanding with advanced large language models. arXiv preprint arXiv:2304.10592 (2023)
- Zhu, J.Y., Park, T., Isola, P., Efros, A.A.: Unpaired image-to-image translation using cycle-consistent adversarial networks. In: ICCV (2017)
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【AIGC】2024-ECCV-ControlNet++:通过有效的一致性反馈改进条件控制

发表评论 取消回复