前言
论文PDF下载地址:7156
最近想搜一下基于大语言模型的情感分析论文,搜到了这篇在今年发表的论文,于是简单阅读之后在这里记一下笔记。
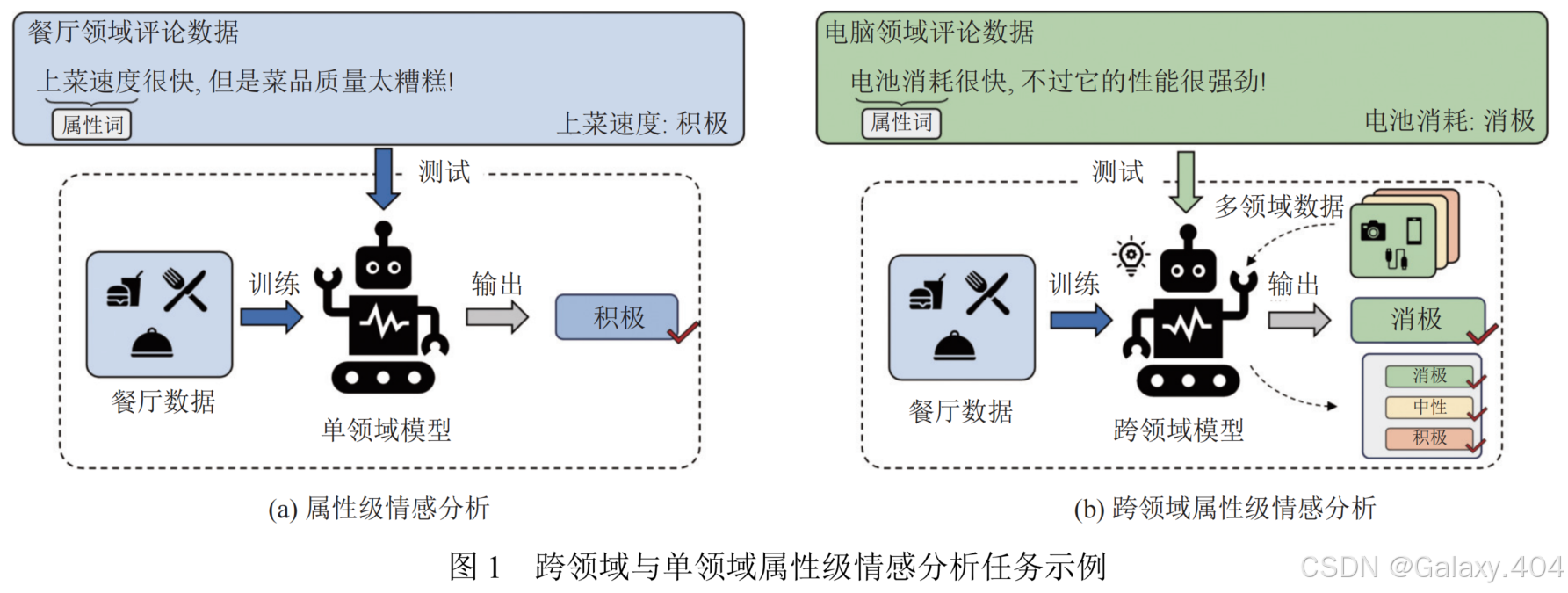
如图1所示,在餐厅领域中的"快"是上菜快,属于正面情感,但是在电脑领域中的"快"是电池消耗很快,属于负面情感。这也说明了:不同领域之间存在同个词包含不同的语义信息。
由于不同领域的语义差异影响了现有属性级情感分析方法的效果,使其大多只能在特定领域或特定类型的数据上表现良好。但是,在面对特定领域的属性级情感分类任务时,往往又缺乏足够的有标签数据。同时,由于语料标注的成本高,获取大规模和高质量训练语料的难度很大,所以目前主流的属性级情感分析方法难以适应不同领域或不同类型数据的属性级情感分析需求。因此有必要提出一种能够适应多领域、多类型数据的跨领域属性情感分类方法。
跨领域情感分类存在两个难点:
- 目标领域缺乏有标签数据;
- 跨领域文本特征差异大。
为了解决跨领域情感分类的研究中所遇到的问题,本文提出了一种新的跨领域数据增强方法:基于大语言模型(LLM)数据增强的跨领域属性级情感分析方法。
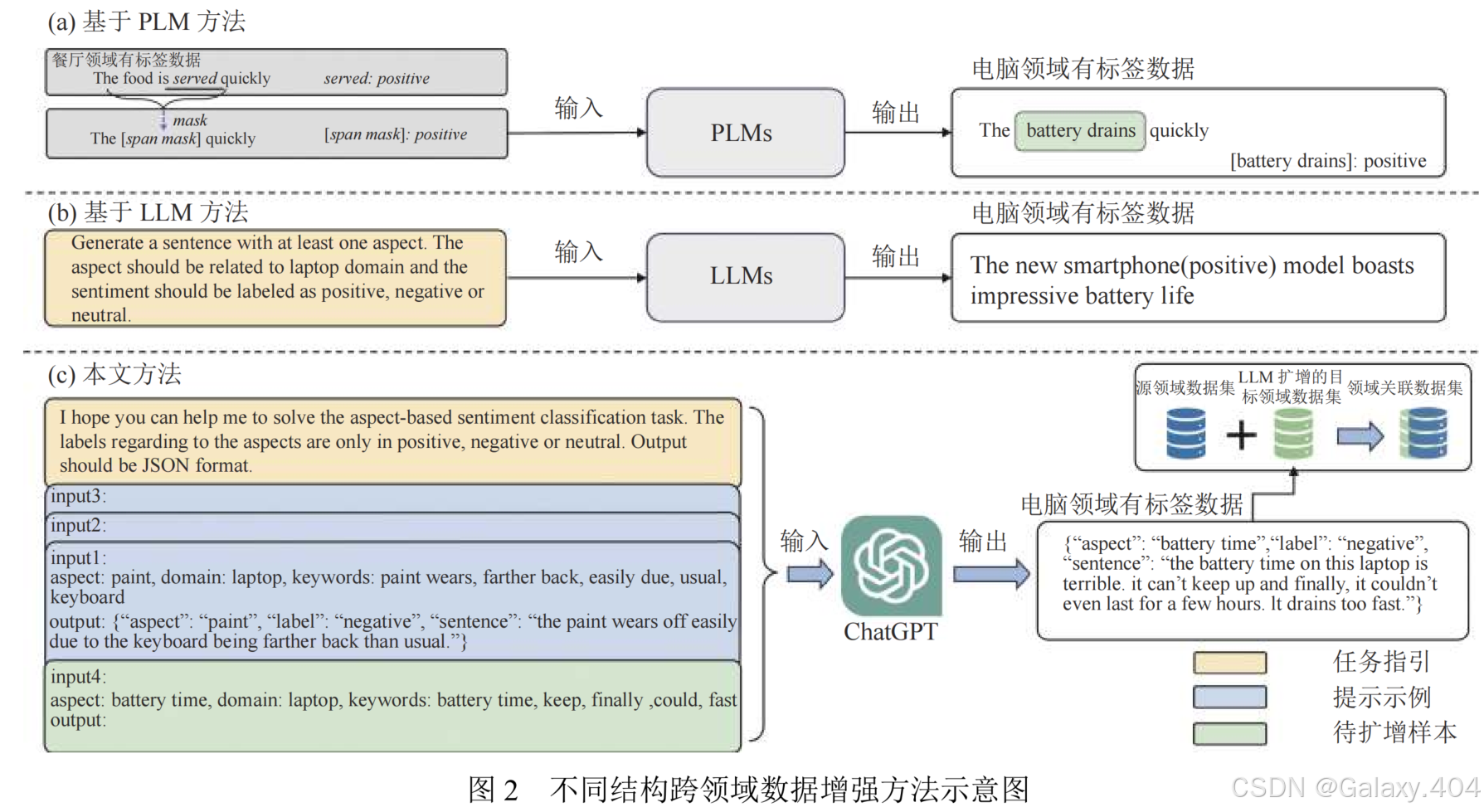
图2展示了不同结构跨领域数据增强方法:
(a) 基于预训练语言模型(PLM)的方法通过掩码策略生成目标领域的有标签数据,其作用是弥补目标领域无标签数据的不足,缺点是不同领域的语义差异可能导致生成的文本不自然流畅,且难以保持目标领域文本的多样性,容易受源领域数据的影响。
(b) 利用大语言模型(LLM)通过学习大规模文本数据生成高质量的文本,其作用是弥补目标领域无标签数据的不足,缺点是生成的文本过于简单,解析性较低,难以确保满足目标领域的要求,容易偏向源领域数据的表达风格。
(c) 本文提出一种基于 LLM 数据增强的跨领域属性级情感分析方法。
- ①针对跨领域属性级别情感分类任务,合理构造指令语句用以引导 LLM 完成目标领域文本结构化生成任务;
- ②挖掘目标领域与源领域相似文本,提取样例级别的文本生成关键词;
- ③通过上下文学习方式使用领域关联关键词,引导模型高效生成目标领域有标签文本数据,用以解决目标领域数据缺乏以及领域特异性问题,从而有效提高跨领域情感分析方法的准确性和鲁棒性。
1 相关工作
1.1 属性级情感分析
属性级情感分类旨在从文本中识别和分析特定属性词的情感极性。
- 早期:主要依赖人工设计的模板来提取文本中于目标属性词相关的情感信息。
- 深度神经网络时代:主要依赖神经网络模型来处理属性级情感分类任务。
- 预训练模型发展时代:将预训练模型应用到属性级情感分类任务。
虽然目前提出的属性级情感分析方法可以在特定的领域取得较好的结果,但是不同领域间的语义分布差异以及新兴领域缺乏标签数据等问题会影响现有属性级情感分析方法的表现。因此,本文提出一种基于 LLM 数据增强的通用方法,通过合理生成目标领域的有标签数据,可以有效强化现有属性级情感分析方法在跨领域问题中的表现。
1.2 跨领域情感分类
跨领域情感分类是指在某个特定领域中训练情感分类模型,并将该模型应用于不同领域的文本数据中。
- 挖掘领域无关的特征信息来实现跨领域的情感迁移学习的方法。
- 基于领域对抗学习的方法,利用领域对抗学习模块强化模型对于不同领域信息地判别。
- 基于半监督学习,利用无标签数据对预训练模型进行领域后训练。
虽然这些方法可以有效缓解领域差异给模型带来的性能损失,但是缺乏对于目标领域特有语义结构的学习。
1.3 跨领域的数据增强方法
数据增强可以有效缓解领域迁移所带来的问题,缓解数据稀缺的情况,并帮助模型更好地适应不同领域的情感分类任务,从而提升模型的性能和泛化能力。传统的方法有3类:
- 改写类:通过改变句子的结构、单词的顺序或者使用同义词等方式来生成新的句子。
- 噪声类:即通过在原始文本中添加噪声,如随机替换单词、删除单词或者交换单词位置等方式来生成新的句子。
- 采样类:通过从原始文本中随机采样一些片段,如单词、短语或者句子等,然后将它们组合成新的句子。
但是,传统的数据增强方法存在语法错误、语义失真和上下文难捕捉等问题,而且依赖预定义规则,无法处理复杂任务。此外,这些方法仅局限于利用有标签的源领域数据,缺乏对目标领域无标签数据的利用。因此,这类方法同样缺乏对目标领域中特有属性词与情感词的敏感性。
跨领域的数据增强通过直接生成目标领域的有标签数据用以解决目标领域缺乏有标签数据的问题。此类方法可以提高模型对于目标领域中特有属性词与情感词的敏感性,但是目前跨领域的数据增强方法生成的目标领域文本仍有许多不足,如文本语义不连贯,文本结构单一,文本特征与源领域趋同等。因此,本文提出一种基于 LLM 数据增强的通用方法,通过合理引导 LLM 生成目标领域的有标签数据,同时保证生成数据的多样性和流畅性。
2 基于LLM与数据增强的跨领域属性级情感分类任务
- ①针对跨领域属性级别情感分析任务,合理构造指令语句用以引导LLM 完成目标领域文本结构化生成任务。
- ②挖掘目标领域与源领域相似文本,提取样例级别的文本生成关键词。
- ③通过上下文学习方式,基于示例样本,引导模型使用领域关联关键词引导模型高效生成目标领域有标签文本数据,从而解决目标领域数据缺乏问题。
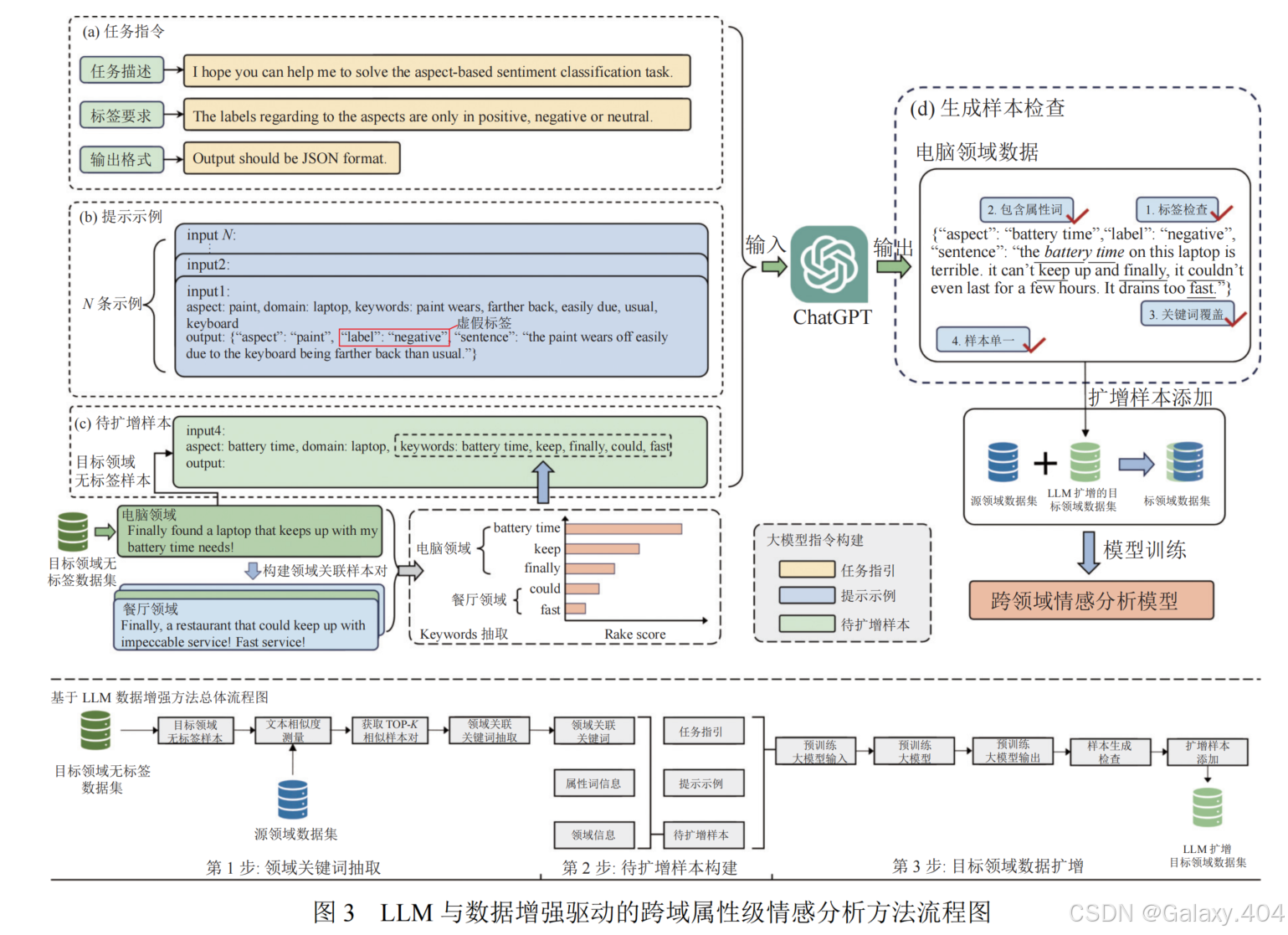
以餐厅领域作为源领域,电脑领域作为目标领域,则本文方法流程如图3 所示。
2.1 LLM与指令构建
本文设计了针对属性级别情感分任务的数据生成指令“I hope you can help me to solve the aspect-based sentiment classification task. The labels regarding tothe aspect are only in positive, negative or neutral. Output should be JSON format,”。
如图 3(a)所示,相较于先前工作直接生成自然语言样本,本文使用特定指令使得 LLM 输出结构化的 JSON 格式文本。相比于非结构化文本,结构化文本可以更方便地进行信息提取,进而便于后续的模型训练。
同时,本文还在指令中明确规定了生成样本的标签信息。‘’
此外,为了更好地在指令构建部分引导模型生成结构化数据,本文针对跨领域属性级别情感分析任务,设计了多个样例属性,用以包含源领域与目标领域信息,如属性词(aspect word),领域信息 (domain),以及跨领域文本关键词信息 (keywords),用以引导 LLM 高效生成目标领域样本。
2.2 样例级领域关联关键词抽取
仅凭单一指令文本来引导 LLM 生成文本,可能会导致生成结果的文本结构较为单一,缺乏丰富性和多样性。为了解决此问题,本文在引导语句中添加领域相关的关键词,以提高生成文本的质量和多样性,这些领域关键词与源领域和目标领域的相关文本内容紧密相关,能够引导 LLM 在生成文本时专注领域相关的特定知识和主题,令其提供更具针对性的内容表达。
例如,在图3中,源领域为餐厅领域,目标领域为电脑领域,本文通过在引导语句中加入与源领域内容相关的关键词,如“fast”,以引导模型生成与之相关的目标领域评论信息,从而有效构建源领域与目标领域文本关联,进而缓解领域差异问题。如图3中所示,源领域餐厅评论中“fast”有积极的含义,如果仅使用源领域数据训练模型,模型由于缺乏对目标领域数据的学习,针对电子设备领域中出现的用电速度快,可能会做出错误的判断,本文通过构建样例级领域关键词,引导 LLM 产生与源领域关联的目标领域数据用于模型学习和训练,可以有效缓解这一问题。
本文抽取样例级领域关键词可分为以下3步:
- 使用 SimCSE50计算待扩增目标领域样本与源领域所有样本文本相似度。
- 获取源领域与目标领域待文本相似度 Top-k样本对。
- 针对这些样本对,使用 RAKE算法5抽取关键短语,获取得分最高的 Top-P 个短语作为关键词。
具体流程如图4所示:
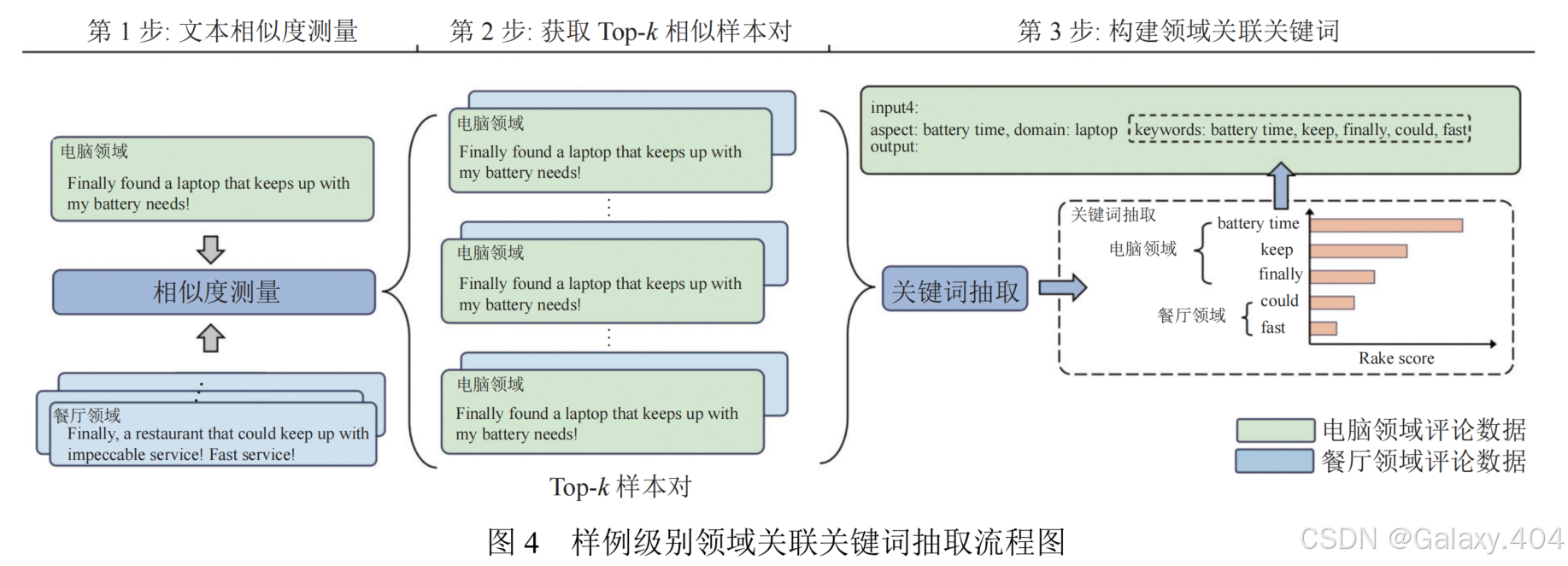
简单来说,该流程可以简要提取为以下几个步骤:
- SimEncoder编码:使用训练好的SimEncoder模型分别对源领域有标签数据和目标领域无标签数据进行编码,得到对应的隐含层向量表示。
- 计算相似度矩阵:利用源领域和目标领域的编码结果,计算它们之间的相似度矩阵。
- 选择Top-k样本:基于相似度矩阵,从源领域选择与目标领域最相似的Top-k样本。
- 关键词提取(RAKE算法):对源领域和目标领域样本中的文本进行关键词提取,获取关键信息。
- 生成新样本集:利用提取到的关键词及生成的相似样本集,进一步生成目标领域的结构化样本数据,便于后续模型训练和情感分析。
2.3 上下文学习
利用LLM根据上下文指示命令完成任务并生成文本预测。
如图3(b)所示,完整上下文学习指令可以形式化为定义:

其中,C表示本文使用完整指示命令,I为跨领域属性级情感分析任务指示命令文本,d为目标领域名称,n为添加示例数量,


因此,基于上下文学习的 LLM 可以定义为:
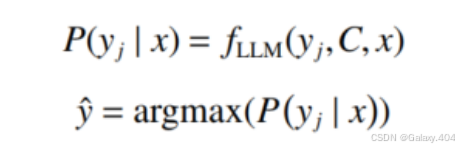
生成数据为 LLM 经由指令指导生成的目标领域有标签样本。
2.4 数据清洗
为了提高 LLM 生成文本的质量,本文对生成的文本数据进行筛选和修复处理,具体包括以下措施:
- 删除不符合 JSON 格式的样本。
- 删除标签错误的样本。
- 删除文本中不包含指定属性词的样本。
- 删除关键词覆盖率小于
的样本。
- 剔除重复样本,确保生成数据的独特性。
2.5 模型训练
![X=[I,x_1,x_2,...,x_m]](/uploads/article_img/eq?X%3D%5BI%2Cx_1%2Cx_2%2C...%2Cx_m%5D) , 首先基于 T5
模型的
Encoder
部分将输入文本X 编码为
, 首先基于 T5
模型的
Encoder
部分将输入文本X 编码为 ,
即:
,
即:

3 实验
3.1 实验数据与实验设置
- 使用 Restaurant, Service, Laptop, Device 这 4 个领域常用的英文属性级情感分析数据集,构建 10 个 (源领域, 目标领域) 数据集对。
- 使用扫地机器人,香水,牛奶,智能开关领域的评论数据,并去除中其中无属性词的样本,构建 4 个中文属性级情感分析数据集对,用以验证本文方法在跨领域属性级情感分析任务中的有效性。
- 删除了 (Device, Laptop) 和 (Laptop, Device) 两个英文评论领域对, 因为其评论内容过于接近。
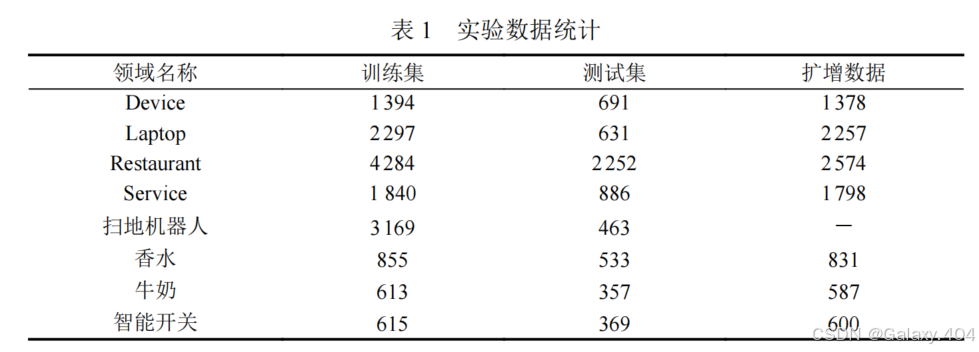
- 本文提出的跨领域属性级情感分类方法使用 ChatGPT 和 T5-base 模型进行数据增强,使用 API 调用 gpt-3.5-turbo-0301 执行数据增强任务。
- 实验使用 GeForce RTX 3090 GPU,Batch size 设置为 16,T5 模型的学习率为 2E-4,使用 Adam 优化器优化模型参数,LLM 生成时的 temperature 参数设置为 0.2。
- 实验采用准确率(Acc)作为评价指标,结果基于多次实验的平均值。
3.2 对比方法与实验结果
基线方法:BERT、T5、BART。
近期较为强劲的跨领域情感分析模型: ChatGPT、LLaMa、ADSPT、PADA、ACSC。
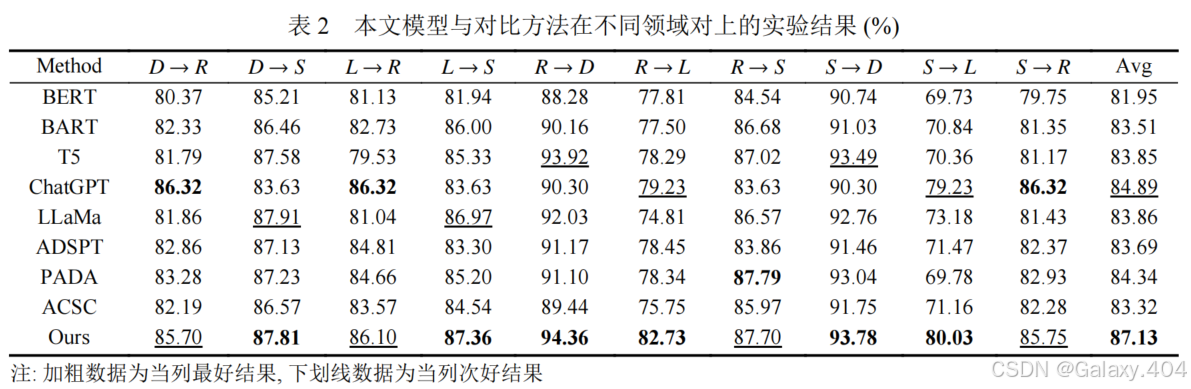
实验表明:
- BERT 在跨领域属性级情感分析任务中的表现相对较低,而经过微调的 T5 和 BART 模型表现更好。大语言模型如 ChatGPT 和 LLaMa 的表现则超过了传统模型,尤其是 T5 和 BART。
- 指令调优方法显著提高了 LLM 在跨领域属性级情感分析任务中的表现,但同时对LLM的平均准确率有所影响。
- 各种跨领域情感分析方法如 ADSPT、PADA 和 ACSC 表现相似,但通过上下文学习的方式结合关键词引导生成目标领域标注数据能够有效缓解领域迁移问题。
- ChatGPT 在多个领域中的平均准确率提高了 2.3%,T5 模型提高了 3.28%。表明本文提出的方法有较强的泛化性和表现力。
3.3 中文数据集实验结果
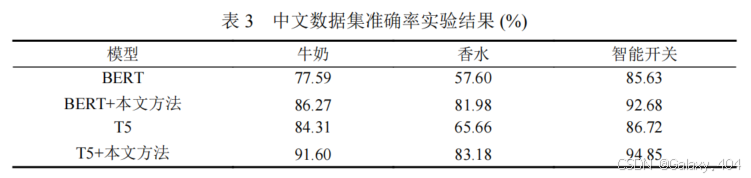
- 为验证本文方法在不同语言数据集中的有效性,使用中文评论数据集作为训练数据,并测试牛奶、香水及智能手机领域的评论数据。
- 使用 BERT 和 MT5-base 多语言模型进行训练和测试,以支持中文评论数据。
- 实验结果表明,本文方法在中文数据集中的有效性较强,尤其在香水领域表现尤为突出。
- 基线模型因样本偏差较大导致表现不均衡,而本文方法通过数据增强和引导生成有标签数据,能够有效缓解领域迁移问题。
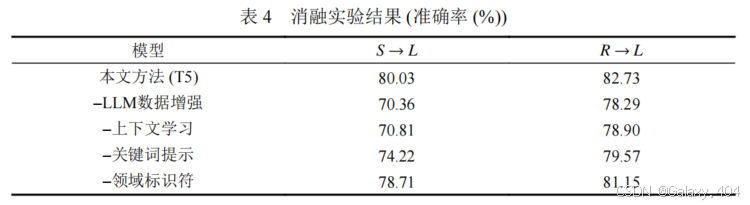
3.4 消融实验
- 去除 LLM 数据增强后,模型在跨领域中的准确率显著下降,特别是在 S→L 领域,准确率下降了 9.94%。基于 LLM 的数据增强通过合理引导生成目标领域有标签数据,能够有效缓解领域差异问题,提升跨领域属性级情感分析任务的性能。
- 去除上下文学习的指令引导后,模型性能也有大幅度下降,说明上下文学习和关键词提示对生成多样化、结构化的目标领域数据至关重要。
- 去除关键词提示和领域标识符也回降低模型的性能。样例级别的关键词提示可以提高文本生成的多样性。
实验证明,本文方法中的各模块对解决跨领域情感分类任务有显著帮助。
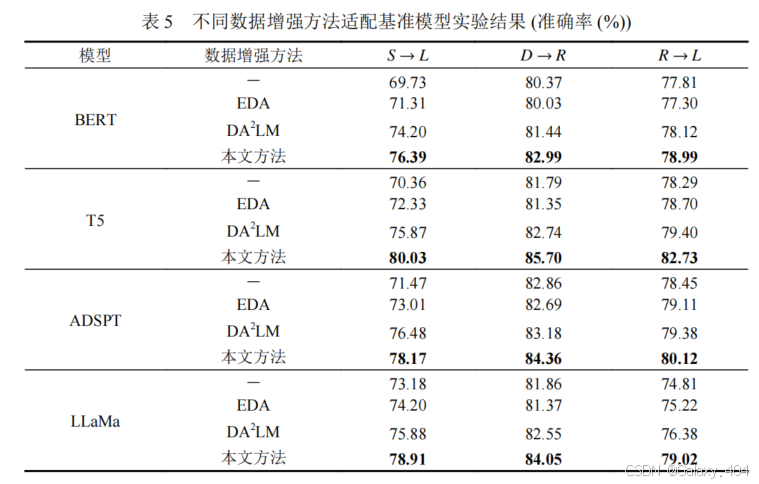
3.5 不同数据增强方法适配基准模型实验
为验证本文方法的普适性,本文选择了3个领域对基于 LLM 的数据增强方法与不同数据增强方法进行基准测试,比较了传统的 EDA 方法和基于 DA²LM 的方法。
- 基于 LLM 数据增强的方法在不同领域对的表现优于其他方法,尤其在 S→L 领域中,由于领域差异较大,各类方法的表现都不理想,但 LLM 方法仍能较好缓解领域差异问题。
- 在 D→R→L 领域对中,本文方法也优于其他数据增强方法,能够更好提升基准模型的表现。
结果表明,本文方法可以简洁有效地适配多种结构模型,帮助跨领域属性级情感分析任务取得更好效果。
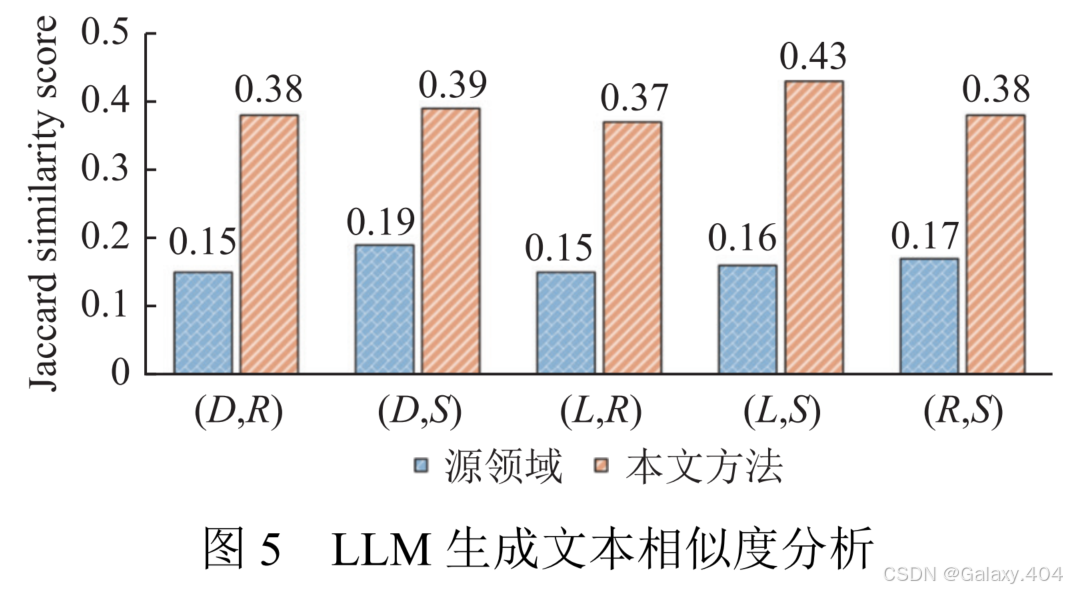
3.6 LLM生成文本分析
实验使用了 5 组领域对组合,分别使用源领域和目标领域的混合数据进行相似度计算。结果显示,基于 LLM 的数据增强方法可以有效提高不同领域对之间的文本相似度。
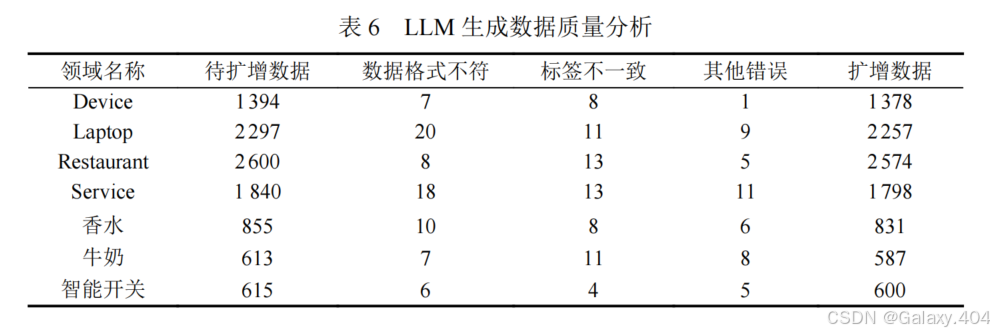
为探讨 LLM 生成文本的质量,本文对生成的低质量数据进行了详细分析。
实验结果表明,生成的低质量数据中主要错误为数据格式不匹配和标签错误,其他类型错误包括属性词遗漏和关键词缺失。
尽管低质量数据占比较高,但 LLM 错误生成的数据比例相对较低,说明本文提出的基于 LLM 的数据增强策略具备较高的鲁棒性。
3.7 生成样例分析

- ① 针对跨领域属性级别情感分析任务,本文合理构造指令语句 (instruction)用以引导LLM 完成目标领域文本结构化生成任务,并且在指示语句中明确指出情感标签类别与输出格式。
- ②通过挖掘目标领域与源领域相似文本,提取样例级别的文本生成关键词,如 input4 中包含的关键词,friendly 来源于餐厅领域,其余关键词来源于电脑领域。
- ③本文利用这些领域关联关键词,通过上下文学习的方式引导模型高效生成目标领域有标签文本数据。
通过图6可以看出,基于本文设计构造的指令,LLM 可以基于关键词信息准确地输出目标领域文本内容,领域信息,属性词信息和其情感信息,同时具有较高的文本流畅性。
因此,通过本文提出的基于 LLM 数据增强方法可以有效地缓解目标领域缺乏标签数据的问题,从而帮助模型更好地解决跨领域属性级情感分析任务。
4 总结
本文提出了一种基于 LLM 和数据增强的跨领域属性级情感分析方法,旨在克服目标领域数据匮乏和领域差异性的问题。通过构建引导句和上下文学习方式,生成目标领域的有标签数据,缓解领域迁移问题。实验结果表明,本文方法在多个数据集上提升了基线模型的性能。未来研究将专注于控制生成文本质量,减少 LLM 产生的幻觉现象,并完成更复杂的情感分析任务。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 大语言模型驱动的跨域属性级情感分析——论文阅读笔记

发表评论 取消回复