前言
该R代码用于对Iris数据集进行多组比较分析,探讨不同鸢尾花品种在不同测量变量(花萼和花瓣长度与宽度)上的显著性差异。通过将数据转换为长格式,并利用ANOVA和Tukey检验,代码生成了不同品种间的显著性标记,并将结果导出为Excel文件。同时,代码使用柱状图显示均值、标准差及显著性星号标记,使结果更加直观。
代码说明
代码如下
# 加载必要的包
library(dplyr) # 用于数据操作
library(tidyr) # 用于数据整理
library(ggplot2) # 用于数据可视化
library(multcompView) # 用于多重比较结果可视化
library(writexl) # 用于将数据导出为Excel文件
library(tidyverse) # 包含dplyr、tidyr等,用于数据处理和可视化
# 定义函数用于添加显著性星号
add_significance <- function(p_value) {
if (p_value < 0.001) {
"***"
} else if (p_value < 0.01) {
"**"
} else if (p_value < 0.05) {
"*"
} else {
""
}
}
# 根据P值的大小添加显著性符号("*"、"**"、"***")
# 将数据转换为长格式
iris_long <- iris %>%
pivot_longer(cols = starts_with("Sepal") | starts_with("Petal"),
names_to = "Variable", values_to = "Value")
# 将Iris数据集转换为长格式,以便后续分组计算。新列命名为Variable和Value
# 计算每个Variable和Species组合的均值和标准差
summary_stats <- iris_long %>%
group_by(Variable, Species) %>%
summarise(
mean = mean(Value),
sd = sd(Value),
.groups = 'drop'
)
# 对每个测量变量和品种组合,计算均值和标准差,结果存储在summary_stats中
# 对每个变量组的不同品种之间进行ANOVA和Tukey检验,并生成显著性星号标记
significance_results <- data.frame() # 创建空数据框以存储显著性检验结果
variables <- unique(iris_long$Variable) # 获取所有变量名的唯一值
for (var in variables) {
# 子集数据
var_data <- iris_long %>% filter(Variable == var)
# 选择当前变量的数据子集
# ANOVA 和 Tukey 检验
anova_result <- aov(Value ~ Species, data = var_data)
tukey_result <- TukeyHSD(anova_result)
# 使用ANOVA检验变量在不同品种之间的差异,然后进行Tukey事后检验
# 提取 Tukey 检验结果
tukey_data <- as.data.frame(tukey_result$Species)
colnames(tukey_data)[colnames(tukey_data) == "p adj"] <- "p_value" # 重命名列
tukey_data <- tukey_data %>%
rownames_to_column(var = "comparison") %>%
mutate(significance = sapply(p_value, add_significance), Variable = var) %>%
select(Variable, comparison, significance)
# 提取Tukey检验结果并添加显著性星号
significance_results <- rbind(significance_results, tukey_data)
# 将每个变量的显著性结果添加到significance_results中
}
# 将显著性结果合并到 summary_stats 数据框
summary_stats <- summary_stats %>%
left_join(significance_results %>%
select(Variable, significance),
by = "Variable") %>%
mutate(y_position = mean + sd + 0.2) # 设置星号显示位置
# 将显著性星号标记添加到均值和标准差数据框中,y_position用于设置星号显示高度
# 导出到Excel
write_xlsx(list("Summary Statistics" = summary_stats,
"Significance Results" = significance_results),
"iris_species_significance.xlsx")
# 将统计汇总和显著性检验结果导出为Excel文件
# 绘制分组柱状图并添加显著性星号
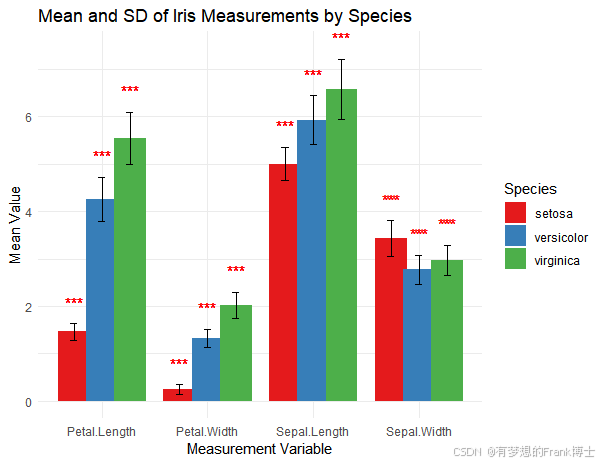
ggplot(summary_stats, aes(x = Variable, y = mean, fill = Species)) +
geom_bar(stat = "identity", position = position_dodge(width = 0.8)) +
geom_errorbar(aes(ymin = mean - sd, ymax = mean + sd),
width = 0.2, position = position_dodge(width = 0.8)) +
geom_text(aes(y = y_position, label = significance),
position = position_dodge(width = 0.8), vjust = -0.5, color = "red") +
labs(title = "Mean and SD of Iris Measurements by Species",
x = "Measurement Variable", y = "Mean Value") +
theme_minimal() +
scale_fill_brewer(palette = "Set1")
# 使用ggplot2绘制分组柱状图,添加误差条和显著性标记,并对图例和标签进行格式设置
总结
此代码为研究者提供了一个完整的数据分析和可视化流程,不仅对数据进行了均值、标准差的计算,还通过显著性星号展示了各品种间的差异。通过将显著性分析结果以星号标记在图中呈现,帮助读者更清晰地了解不同变量在鸢尾花品种之间的差异,从而更好地理解数据。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » R语言*号标识显著性差异判断组间差异是否具有统计意义

发表评论 取消回复