1、预训练模型
使用的模型基座为:qq8933/OpenLongCoT-Base-Gemma2-2B,描述如下:
This model is a fine-tuned version of google/gemma-2-2b-it on the OpenLongCoT dataset.
This model can read and output o1-like LongCoT which targeting work with LLaMA-O1 runtime frameworks.
gemma-2-2b-it描述如下:
Gemma is a family of lightweight, state-of-the-art open models from Google, built from the same research and technology used to create the Gemini models. They are text-to-text, decoder-only large language models, available in English, with open weights for both pre-trained variants and instruction-tuned variants. Gemma models are well-suited for a variety of text generation tasks, including question answering, summarization, and reasoning. Their relatively small size makes it possible to deploy them in environments with limited resources such as a laptop, desktop or your own cloud infrastructure, democratizing access to state of the art AI models and helping foster innovation for everyone.
训练参数如下:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- total_train_batch_size: 8
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 1.0
查看qq8933/OpenLongCoT-Pretrain数据集,数据量126K,单条数据如下:
<start_of_father_id>-1<end_of_father_id><start_of_local_id>0<end_of_local_id><start_of_thought><problem>The average speed for an hour drive is 66 miles per hour. If Felix wanted to drive twice as fast for 4 hours, how many miles will he cover? <end_of_thought> <start_of_father_id>0<end_of_father_id><start_of_local_id>1<end_of_local_id><start_of_thought>Since Felix wants to drive twice as fast, he will drive at 2*66=<<2*66=132>>132 miles per hour. <end_of_thought><start_of_rating><positive_rating><end_of_rating> <start_of_father_id>1<end_of_father_id><start_of_local_id>2<end_of_local_id><start_of_thought> If he drives for 4 hours, he will have driven for 4*132=<<4*132=528>>528 miles. <end_of_thought><start_of_rating><positive_rating><end_of_rating> <start_of_father_id>1<end_of_father_id><start_of_local_id>3<end_of_local_id><start_of_thought><critic> Felix wants to drive twice as fast as his original speed of 66 miles per hour. Multiplying 66 by 2 gives 132 miles per hour. This calculation is correct.<end_of_thought><start_of_rating><unknown_rating><end_of_rating> <start_of_father_id>1<end_of_father_id><start_of_local_id>4<end_of_local_id><start_of_thought><critic> If Felix drives at 132 miles per hour for 4 hours, the total distance he covers can be calculated by multiplying his speed by the time. 132 miles per hour * 4 hours = 528 miles. This calculation is correct.<end_of_thought><start_of_rating><unknown_rating><end_of_rating>
为方便理解,翻译成中文:
<start_of_father_id>-1<end_of_father_id><start_of_local_id>0<end_of_local_id><start_of_thought><problem>一小时车程的平均速度为 66 英里每小时。如果 Felix 想以两倍的速度开车 4 小时,他能行驶多少英里?<end_of_thought> <start_of_father_id>0<end_of_father_id><start_of_local_id>1<end_of_local_id><start_of_thought>由于 Felix 想以两倍的速度开车,因此他的行驶速度将为 2*66=<<2*66=132>>132 英里每小时。 <end_of_thought><start_of_rating><positive_rating><end_of_rating> <start_of_father_id>1<end_of_father_id><start_of_local_id>2<end_of_local_id><start_of_thought> 如果他开车 4 小时,他将行驶 4*132=<<4*132=528>>528 英里。 <end_of_thought><start_of_rating><positive_rating><end_of_rating> <start_of_father_id>1<end_of_father_id><start_of_local_id>3<end_of_local_id><start_of_thought><critic> 菲利克斯希望将他原来的 66 英里每小时的速度提高一倍。 将 66 乘以 2 得到 132 英里每小时。这个计算是正确的。<end_of_thought><start_of_rating><unknown_rating><end_of_rating> <start_of_father_id>1<end_of_father_id><start_of_local_id>4<end_of_local_id><start_of_thought><critic> 如果 Felix 以每小时 132 英里的速度行驶 4 个小时,那么他行驶的总距离可以通过将速度乘以时间来计算。每小时 132 英里 * 4 小时 = 528 英里。这个计算是正确的。<end_of_thought><start_of_rating><unknown_rating><end_of_rating>
从数据来看,应该是做了简单的增量预训练微调。
2、主要函数分析
定义不同的提示词模板
hint = '<hint> Try generate a reasonable rationale solution that can got final answer {GT}</hint>'
# hint = ''
hint_for_critics = f"<hint> Point out the potential flaws in the current solution. </hint>"
hint_for_refine = f"<hint> Try to refine the current solution for higher quality. </hint>"
hint_for_conclusion = "<hint> Try to summarize the current solution and draw a conclusion. Final answer should bracket in \\box{answer} </hint>"
hint_for_divide_and_conquer = f"<hint> Try divide the problem into smaller easier sub-problems and solve them divide-and-conquer. </hint>"
compute_policy_head分析
# 策略生成的主要函数
@torch.no_grad()
def compute_policy_head(model, tokenizer, selected_node, num_candidates=3, meta="", envoirment=None):
local_id = get_max_node_id_in_tree(selected_node) + 1
hint_text = {
"<conclusion>": hint_for_critics,
"<problem>": hint_for_divide_and_conquer,
"<critic>": hint_for_critics,
"<refine>": hint_for_refine,
}.get(meta, hint.format(GT=envoirment.get_ground_truth(selected_node)))
inputs_string = policy_head_template(selected_node, local_id, meta, hint_text)
with set_left_truncate(tokenizer):
inputs = tokenizer(
inputs_string,
return_tensors="pt",
truncation=True,
padding='longest',
max_length=CUT_OFF_LEN
)
inputs = {k: v.to(accelerator.device) for k, v in inputs.items()}
outputs = accelerator.unwrap_model(model).generate(
input_ids=inputs['input_ids'],
attention_mask=inputs['attention_mask'],
max_new_tokens=GENERATE_MAX_NEW_TOKENS,
do_sample=True,
num_return_sequences=num_candidates,
return_dict_in_generate=True,
output_scores=True,
temperature=1.5,
output_logits=True,
stop_strings=policy_head_stopping_criteria,
tokenizer=tokenizer,
)
generated_sequences = outputs.sequences[:, inputs['input_ids'].size(1):]
generated_sequences_mask = generated_sequences != tokenizer.pad_token_id
generated_texts = tokenizer.batch_decode(generated_sequences, skip_special_tokens=True)
logits = torch.stack(outputs.logits, dim=1)
normalized_log_probs, normalized_entropy, varentropy = length_normed_log_probs(
generated_sequences, logits, attention_mask=generated_sequences_mask, return_entropy=True, return_varentropy=True
)
normalized_probs = torch.exp(normalized_log_probs)
generated_texts = [meta + clean_generated_text(text) for text in generated_texts]
for i, generated_text in enumerate(generated_texts):
if not generated_text.startswith(meta):
generated_texts[i] = meta + generated_text
return generated_texts, normalized_probs.tolist(), normalized_entropy.tolist(), varentropy.tolist(), [meta,] * num_candidates
def policy_head_template(selected_node, local_id, meta="", hint=""):
return (
path_to_string(selected_node)
+ f"{hint}\n<start_of_father_id>{selected_node.index if selected_node else -1}<end_of_father_id><start_of_local_id>{local_id}<end_of_local_id><start_of_thought>{meta}"
)
def path_to_string(node):
path = []
while node:
path.append(node)
node = node.parent
string = "\n".join(
[
f"<start_of_father_id>{node.parent.index if node.parent else -1}<end_of_father_id><start_of_local_id>{node.index}<end_of_local_id><start_of_thought>{node.state}<end_of_thought><start_of_rating>{value_to_rating_token(node.value)}<end_of_rating>"
for node in path[::-1]
]
)
return string这个函数的逻辑为,支持根据meta标签类型,做不同的生成任务,若meta不指定,则使用hint默认的提示词。最终返回多个候选答案,每个答案以meta开头。
注意构造prompt的时候,将selected_node的上文路径信息引入进来了。每个节点使用这种格式:<start_of_thought>{node.state}<end_of_thought><start_of_rating>{value_to_rating_token(node.value)}<end_of_rating>"
再次验证了,基座模型就是预训练好的大模型。
compute_value_head
# 价值头生成函数
@torch.no_grad()
def compute_value_head(model, tokenizer, node):
text_for_value = value_head_template(node) + '<positive_rating>'
with set_left_truncate(tokenizer):
inputs = tokenizer(text_for_value, return_tensors="pt", truncation=True, padding='longest', max_length=CUT_OFF_LEN)
inputs = {k: v.to(accelerator.device) for k, v in inputs.items()}
outputs = model(**inputs, return_dict=True)
logits = outputs.logits
last_logits = logits[:, -2, :]
positive_token_id = tokenizer.convert_tokens_to_ids("<positive_rating>")
negative_token_id = tokenizer.convert_tokens_to_ids("<negative_rating>")
positive_logit = last_logits[:, positive_token_id]
negative_logit = last_logits[:, negative_token_id]
value_logits = torch.stack([positive_logit, negative_logit], dim=1)
probs, log_probs = robust_softmax(value_logits)
return log_probs[:, 0].item()这是一个很不错的设计,增加<positive_rating>构成prompt,然后从输出logits中根据positive_token_id和negative_token_id取对应的logits,最后利用softmax单独计算正负概率。从而能对价值做评估。
# 元策略生成函数
@torch.no_grad()
def meta_compute_policy_head(model, tokenizer, selected_node, num_candidates=3, meta_ratio=0.5, envoirment=None):
metas = sampling_meta_action(selected_node, num_candidates)
generated_texts, policy_probs, normalized_entropys, varentropys = [], [], [], []
for meta in metas:
texts, policy_probs, normalized_entropy, varentropy, _ = compute_policy_head(model, tokenizer,
selected_node, num_candidates=1, meta=meta, envoirment=envoirment
)
generated_texts.append(texts[0])
policy_probs.append(policy_probs[0])
normalized_entropys.append(normalized_entropy[0])
varentropys.append(varentropy[0])
return generated_texts, policy_probs, normalized_entropys, varentropys, metas主要内容:下一步要使用什么策略,概率是多少,生成的内容是什么。可选的meta这里使用sampling而来,具体没有弄明白,TODO
cal_meta_transition_probs函数分析
def cal_meta_transition_probs(node):
num_meta_actions = len(meta_action_types)
# 展开树结构,获取父节点索引、子节点索引和对应的值
parents, children, values = flatten_tree(node)
# 初始化转移概率矩阵
TransitionProbs = np.zeros((num_meta_actions, num_meta_actions))
# 使用 NumPy 的高级索引和累加来更新矩阵
if len(parents) > 0:
np.add.at(TransitionProbs, (parents, children), values)
return TransitionProbs>>> TransitionProbs = np.zeros((5,5))
>>> np.add.at(TransitionProbs, ([0,0,0,0,1],[1,2,3,4,3]), [0.1, 0.2, 0.1, 0.3,0.01])
>>> TransitionProbs
array([[0. , 0.1 , 0.2 , 0.1 , 0.3 ],
[0. , 0. , 0. , 0.01, 0. ],
[0. , 0. , 0. , 0. , 0. ],
[0. , 0. , 0. , 0. , 0. ],
[0. , 0. , 0. , 0. , 0. ]])
>>> TransitionProbs = np.zeros((5,5))
>>> np.add.at(TransitionProbs, ([0,0,0,0,1,1],[1,2,3,4,3,4]), [0.1, 0.2, 0.1, 0.3,0.01,0.02])
>>> TransitionProbs
array([[0. , 0.1 , 0.2 , 0.1 , 0.3 ],
[0. , 0. , 0. , 0.01, 0.02],
[0. , 0. , 0. , 0. , 0. ],
[0. , 0. , 0. , 0. , 0. ],
[0. , 0. , 0. , 0. , 0. ]])
sampling_meta_action函数分析
@lru_cache()
def sampling_meta_action(node, num=1, TransitionProbs=None):
if TransitionProbs is None:
root = get_root(node)
TransitionProbs = cal_meta_transition_probs(root)
# 计算转移概率的 softmax
transition_probs_softmax = np_softmax(TransitionProbs)
i = meta_action_type_to_index[node.meta]
p = transition_probs_softmax[i]
# 进行采样
meta_actions = np.random.choice(meta_action_types, size=num, p=p)
return meta_actions(1)将上一步测试的TransitionProbs放入np_softmax函数,可以看出,按行计算概率分布。
(2)取出node.meta即当前节点的meta类型,得到meta类型所在行下,对应的下一个action的meta概率分布,按概率采样num个输出
>>> def np_softmax(x):
... # 对矩阵的每一行进行 softmax 操作
... max_vals = np.max(x, axis=1, keepdims=True)
... e_x = np.exp(x - max_vals)
... sum_e_x = np.sum(e_x, axis=1, keepdims=True)
... return e_x / sum_e_x
...
>>> np_softmax(TransitionProbs)
array([[0.1729624 , 0.19115301, 0.21125675, 0.19115301, 0.23347482],
[0.19879722, 0.19879722, 0.19879722, 0.20079516, 0.20281319],
[0.2 , 0.2 , 0.2 , 0.2 , 0.2 ],
[0.2 , 0.2 , 0.2 , 0.2 , 0.2 ],
[0.2 , 0.2 , 0.2 , 0.2 , 0.2 ]])
TreeNode分析
(1)get_path_reward,获取当前节点链路上value的平均值=value总和/链路长度
(2)get_child_policy_prob,获取child的概率,这里self.policy为kv字典,value为logits
(3)get_child_policy_entropy,同上,value不同,todo
(4)get_child_policy_varentropy,同上,value不同
MCTS分析
(1)search(self, root_node)。仿真N次,根据最终成功或失败情况,更新各节点value。
def search(self, root_node):
if not root_node.children:
root_node.value = 0
for _ in tqdm(range(self.num_simulations)):
self.simulate(root_node)
max_reward, path_len = find_max_reward_path(root_node)
print(f'find max reward path: {max_reward} with {path_len} steps.')
if self.patient <= 0:
break
for leaf in self.identify_leaf(root_node):
if leaf.leaf_type == "successful":
self.rectify_values_from_leaf(leaf, 0)
else:
self.rectify_values_from_leaf(leaf, np.log(self.reward_epsilon))
return root_node- find_max_reward_path(node)。找到value最大的路径,注意这里修改了root_node,下一次即可从最大value的点进行模拟了。
def find_max_reward_path(node):
path = 0
reward = 0
while node:
reward += node.value
path += 1
if not node.children:
break
node = max(node.children, key=lambda x: x.value)
return math.exp(reward), path- simulate,需要num_simulations到达叶子节点,即num_simulations次生成策略。
- identify_leaf。找到所有的叶子节点。
- rectify_values_from_leaf。根据叶子节点是否解决问题的情况,更新当前节点链路上所有节点的true_value_from_tree(为什么非successful反而>0?)。
(2)simulate(self, node)。若node为叶子节点,则扩展子节点,否则对最佳子节点进行仿真,返回对应value,最后将value进行加权更新。
def simulate(self, node):
if node.is_leaf() or node.should_expand():
value = self.expand_node(node) * self.discount_factor
else:
best_child = self.select_action(node)
value = self.simulate(best_child) * self.discount_factor
node.visits += 1
node.value += (value - node.value) / node.visits
return node.value(3)expand_node(self, node)。
- 调用meta_compute_policy_head,根据Tree的转移状态矩阵,进行meta策略采样,结合上文生成可能的文本。这里没有看懂(长度归一化的对数概率、熵和熵的方差计算)
normalized_log_probs, normalized_entropy, varentropy = length_normed_log_probs(
generated_sequences, logits, attention_mask=generated_sequences_mask, return_entropy=True, return_varentropy=True
)- 迭代每个meta策略结果,构建TreeNode节点,作为子节点添加到node中。若当前节点已经解决了问题,则将节点的leaf_type设置为"successful"。
注意:这里每个节点的value是通过大模型生成的,取positive_rating和negative_rating对应的logits,计算概率,比较巧妙。见如下代码:
# 价值头生成函数
@torch.no_grad()
def compute_value_head(model, tokenizer, node):
text_for_value = value_head_template(node) + '<positive_rating>'
with set_left_truncate(tokenizer):
inputs = tokenizer(text_for_value, return_tensors="pt", truncation=True, padding='longest', max_length=CUT_OFF_LEN)
inputs = {k: v.to(accelerator.device) for k, v in inputs.items()}
outputs = model(**inputs, return_dict=True)
logits = outputs.logits
last_logits = logits[:, -2, :]
positive_token_id = tokenizer.convert_tokens_to_ids("<positive_rating>")
negative_token_id = tokenizer.convert_tokens_to_ids("<negative_rating>")
positive_logit = last_logits[:, positive_token_id]
negative_logit = last_logits[:, negative_token_id]
value_logits = torch.stack([positive_logit, negative_logit], dim=1)
probs, log_probs = robust_softmax(value_logits)
return log_probs[:, 0].item()- select_action(self, node)选择ucb值最高的子节点对应的value。大概就是根据访问次数,子节点概率等进行加权。
PrioritizedReplayBuffer
根据优先级对buffer中的数据进行采样,同时提供了持久化方法
RLSPTrainer
(1)self_play
(2)collect_experience。这里有几个部分:
-
tokenize_policy_predict。构造policy训练数据,输入为上文的prompt,输出为state文本内容。
-
value_head_template,构造value训练数据,输入为prompt(含state),输出为positive_rating得分。
-
advantage和priority,节点链路上的全局损失?compute_gae_from_node(node)
-
reward,当前节点的true value
def collect_experience(self, root_node):
"""Traverse the MCTS tree to collect experiences and store them in the replay buffer."""
# Collect training data from the tree
for node in traverse_tree(root_node):
if node == root_node:
continue
reward = node.true_value_from_tree if node.true_value_from_tree is not None else node.value
advantage = compute_gae_from_node(node)
policy_input = tokenize_policy_predict([node,], self.tokenizer)
advantage_tensor = torch.tensor([advantage], dtype=torch.float32).unsqueeze(0)
value_input = tokenize_value_predict(node, self.tokenizer)
value_target = torch.tensor([reward], dtype=torch.float32).unsqueeze(0)
# Store the experience with initial priority
experience = {
'advantage': advantage_tensor,
'value_target': value_target,
**policy_input,
**value_input,
}
# Use absolute advantage as initial priority
priority = abs(advantage_tensor.item())
self.replay_buffer.add(experience, priority)
def tokenize_policy_predict(nodes,tokenizer):
with set_left_truncate(tokenizer):
text_for_policys = [policy_head_template(node.parent, node.index) + node.state for node in nodes]
targets = [node.state for node in nodes]
# with set_left_padding(tokenizer):
inputs = tokenizer(text_for_policys, return_tensors="pt", truncation=True, padding='longest', max_length=CUT_OFF_LEN)
target = tokenizer(targets, return_tensors="pt", truncation=True, padding='longest', max_length=CUT_OFF_LEN)
ret = {'input_ids':inputs['input_ids'],'attention_mask':inputs['attention_mask'],'target':target['input_ids'],'target_attention_mask':target['attention_mask']}
return ret(3)compute_loss(self, model, inputs, return_outputs=False)
def compute_loss(self, model, inputs, return_outputs=False):
"""Compute the loss, incorporating importance-sampling weights."""
# Compute policy loss using PPO
new_policy_log_probs = forward_policy_predict(self.model, self.tokenizer, inputs)
with torch.no_grad():
old_policy_log_probs = forward_policy_predict(self.model.get_base_model(), self.tokenizer, inputs).detach()
target_mask = inputs['target_attention_mask']
advantage = inputs['advantage']
epsilon = 0.2 # PPO clip parameter
ratio = (new_policy_log_probs - old_policy_log_probs).exp() * target_mask[:,1:]
surr1 = ratio * advantage.unsqueeze(-1)
surr2 = torch.clamp(ratio, 1 - epsilon, 1 + epsilon) * advantage.unsqueeze(-1)
policy_loss = -torch.min(surr1, surr2).mean()
# Compute value loss
value_prediction = forward_value_predict(self.model, self.tokenizer, inputs)
value_target = inputs['value_target']
clamp_positive_rating_prob = torch.exp(torch.clamp(
value_target, math.log(1e-6), 0
))
clamp_negative_rating_prob = 1 - clamp_positive_rating_prob
target_probs = torch.concat(
[clamp_positive_rating_prob.unsqueeze(-1), clamp_negative_rating_prob.unsqueeze(-1)], dim=1
)
value_loss = F.binary_cross_entropy_with_logits(
value_prediction, target_probs.to(self.accelerator.device)
)
# Combine losses
total_loss = policy_loss + value_loss
if total_loss == 0:
return total_loss
# Apply importance-sampling weights
weights = torch.tensor(inputs['weights'], dtype=torch.float32).to(total_loss.device)
total_loss = total_loss * weights
td_error = total_loss.sum(dim=-1).detach().abs().cpu().numpy()
total_loss = total_loss.mean()
print(f'Policy Loss: {policy_loss}, Value Loss: {value_loss}, Total Loss: {total_loss}')
if return_outputs:
return total_loss, td_error
else:
return total_loss
(1)new_policy_log_probs,这里计算的是在给定输入下,得到的输出logits概率(对目标输出id进行取值)。这个设计还是比较巧妙的
(2)对新旧policy概率进行拟合,得到policy_loss。ratio = (new_policy_log_probs - old_policy_log_probs).exp() * target_mask[:,1:]。policy_loss = -torch.min(surr1, surr2).mean()。
(3)计算value_loss。F.binary_cross_entropy_with_logits( value_prediction, target_probs.to(self.accelerator.device) )
(4)total_loss为两者之和。total_loss = policy_loss + value_loss
def forward_policy_predict(model,tokenizer,inputs):
inputs = {k: v.to(accelerator.device) for k, v in inputs.items()}
input_ids = inputs["input_ids"]
attention_mask = inputs["attention_mask"]
target_ids = inputs["target"]
target_mask = inputs["target_attention_mask"]
outputs = model(input_ids=input_ids, attention_mask=attention_mask, return_dict=True)
logits = outputs.logits[:,:-1,:][:, -target_ids[:,1:].shape[-1] :]
log_probs = F.log_softmax(logits, dim=-1)
seleted_log_probs = log_probs.gather(2, target_ids[:,1:].unsqueeze(-1)).squeeze(-1)
return seleted_log_probs(5)train(self, num_iterations, beta_start=0.4, beta_frames=100000, **kwargs)
-
self play一次,触达两次到叶子节点。
-
注意这里每次计算得到loss后,有一个更新操作,将误差更新到buffer中的样本,从而提升有错误部分的采样概率。self.update_priorities(indices, td_errors)
论文解读
llm在需要战略和逻辑推理的领域面临着显著的挑战。
此外,我们引入了一种动态剪枝策略,结合改进的上置信界(Srinivas等,2009)(UCB)公式,以优化高风险任务的有效决策的探索-开发平衡。
本研究推进了LLMs在复杂推理挑战中的应用。它为未来集成人工智能技术的创新奠定了基础,以提高llm驱动的应用程序的决策、推理的准确性和可靠性
为了更好地评估我们方法的有效性,我们选择LLaMA-3.1-8B-Instruct模型(Meta,2024b)作为SR-MCTS搜索的基础模型,不进行任何额外的训练。我们训练了一个Gemma2-2b-指示模型(谷歌,2024)作为PPRM,以便在搜索过程中提供奖励信号。
为了更好地评估我们方法的有效性,我们选择LLaMA-3.1-8B-Instruct模型(Meta,2024b)作为SR-MCTS搜索的基础模型,不进行任何额外的训练。我们训练了一个Gemma2-2b-指示模型(谷歌,2024)作为PPRM,以便在搜索过程中提供奖励信号。
我们怀疑原因是,在问题难度较低的基准上数学推理性能主要依赖于其固有的推理能力,而在更复杂的基准上,它的性能很大程度上依赖于其自我优化能力。
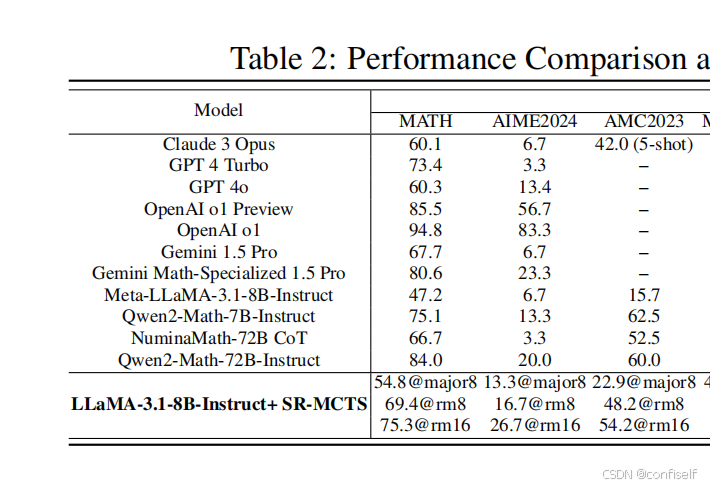
我们的方法不仅在数学推理问题上,而且在各种科学和工程问题上都表现出了显著的性能。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 大模型系列——LLAMA-O1 复刻代码解读

发表评论 取消回复