1. 数据同步

通过上图我们发现每个分区的数据都不一样,但是三个分区对外的数据却是一致的
这个时候如果第二个副本宕机了
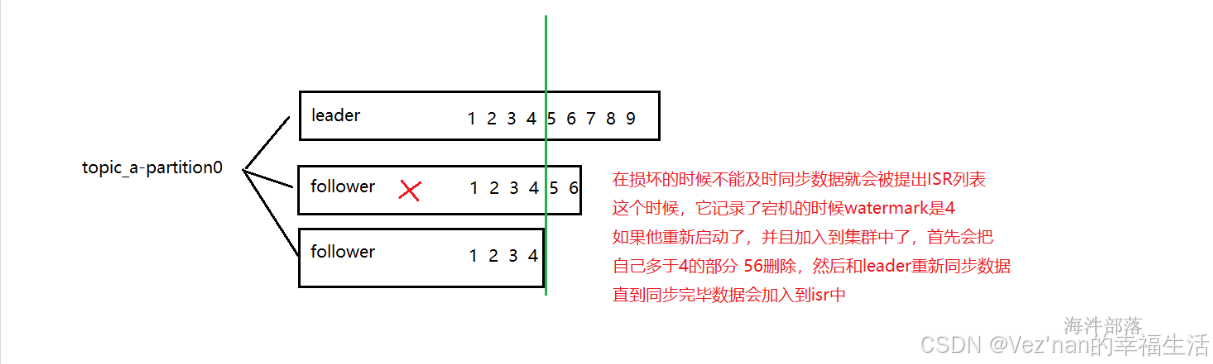
但是如果是leader副本宕机了会发生什么呢?
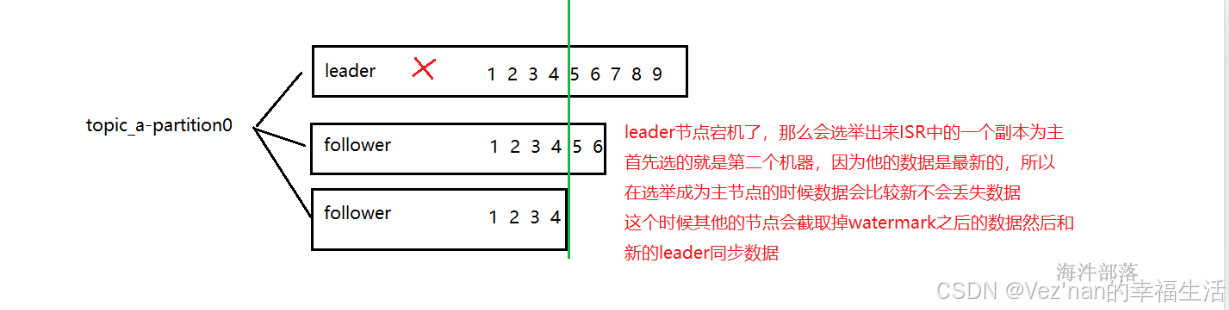
2. 数据均衡
在线上程序运行的时候,有的时候因为上面副本的损坏,从而系统会自动选举出来一个新的leader并且分配到不同的节点上,有的时候这个leader的节点分布的并不是特别均匀,这个时候就需要进行均衡一下,使得每个broker的节点压力均衡
这个时候需要以下三个参数进行控制
| 参数 | 解释 |
|---|---|
| auto.leader.rebalance.enable | 系统每隔300s会自动检查系统的leader分布是否均匀,如果不均匀会自动进行leader的切换 |
| leader.imbalance.per.broker.percentage | broker上的leader比例超过10%认为不均衡 |
| leader.imbalance.check.interval.seconds | 检查间隔300s默认值 |
auto.leader.rebalance.enable 这个开关开启会自动选举或者切换leader节点,并且分布在不同的节点上,但是有的时候这个开关开启会影响系统性能,因为线上环境切换leader是比较繁琐的
但是不开的话可能会出现启动kafka而没有leader分区的情况
一般我们会关闭这个开关并且选择手动切换均衡
kafka-leader-election.sh --bootstrap-server hadoop106:9092 --topic topic_a --partition 1 --election-type preferred优先在ISR中选举出来新的leader进行负载
并且我们也可以自己进行副本的位置进行设定
# 首先创建一个topic.json 输入如下内容
{"topics":[{"topic":"topic_a"}],"version":1}
# 整体代码命令如下
kafka-reassign-partitions.sh --bootstrap-server nn1:9092 --broker-list 0,1,2,3,4 --topics-to-move-json-file topic.json --generate使用这个均衡优化命令生成优化计划
{"version":1,"partitions":[{"topic":"topic_a","partition":0,"replicas":[3,4,0],"log_dirs":["any","any","any"]},{"topic":"topic_a","partition":1,"replicas":[4,0,1],"log_dirs":["any","any","any"]},{"topic":"topic_a","partition":2,"replicas":[0,1,2],"log_dirs":["any","any","any"]},{"topic":"topic_a","partition":3,"replicas":[1,2,3],"log_dirs":["any","any","any"]}]}修改其中副本的位置
并且设定ISR的优先顺序
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 【大数据学习 | kafka高级部分】kafka的数据同步和数据均衡

发表评论 取消回复