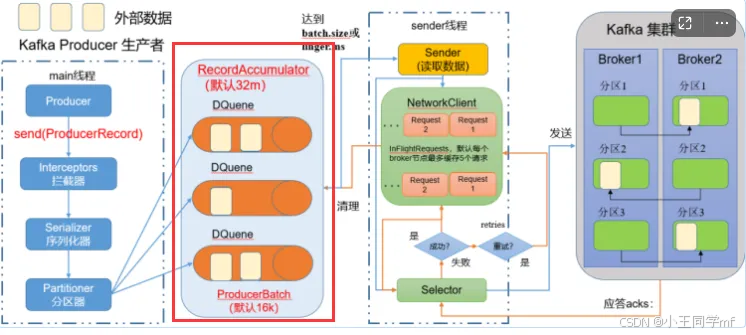
1、batch.size:批次大小,默认16k
2、linger.ms:等待时间,修改为5-100ms
3、compression.type:压缩snappy
4、 RecordAccumulator:缓冲区大小,修改为64m
package com.bigdata.producter;
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
/**
* 测试自定义分区器的使用
*/
public class CustomProducer07 {
public static void main(String[] args) {
// Properties 它是map的一种
Properties properties = new Properties();
// 设置连接kafka集群的ip和端口
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"bigdata01:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
/**
* 此处是提高效率的代码
*/
// batch.size:批次大小,默认 16K
properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 18000);
// linger.ms:等待时间,默认 0
properties.put(ProducerConfig.LINGER_MS_CONFIG, 1);
// RecordAccumulator:缓冲区大小,默认 32M:buffer.memory
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);
// compression.type:压缩,默认 none,可配置值 gzip、snappy、lz4 和 zstd
properties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,"snappy");
// 创建了一个消息生产者对象
KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
// 调用这个里面的send方法
// ctrl + p
/*ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>("first","告诉你个秘密");
kafkaProducer.send(producerRecord);*/
for (int i = 0; i < 5; i++) {
// 发送消息的时候,指定key值,但是没有分区号,会根据 hash(key) % 3 = [0,1,2]
ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>("first","c","告诉你个找bigdata的好办法:"+i);
// 回调-- 调用之前先商量好,回扣多少。
kafkaProducer.send(producerRecord, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
// 获取很多信息,exception == null 说明成功,不为null,说明失败
if(exception == null){
System.out.println("消息发送成功");
System.out.println(metadata.partition());// 三个分区,我什么每次都是2分区,粘性分区
System.out.println(metadata.offset());// 13 14 15 16 17
System.out.println(metadata.topic());
}else{
System.out.println("消息发送失败,失败原因:"+exception.getMessage());
}
}
});
}
kafkaProducer.close();
}
}测试:
①在 bigdata01 上开启 Kafka 消费者。
bin/kafka-console-consumer.sh --bootstrap-server hadoop11:9092 --topic first ②在 IDEA 中执行代码,观察 hadoop102 控制台中是否接收到消息。
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Kafka生产者如何提高吞吐量?

发表评论 取消回复