LightGBM(Light Gradient Boosting Machine)是一种基于梯度提升决策树(GBDT)的框架,由微软提出。它具有高效的训练速度、低内存占用、支持并行和GPU加速等特点,非常适合大规模数据的训练任务,尤其在分类和回归任务中表现突出。LightGBM的核心原理可以从以下几个方面来理解:
LightGBM模型特点
(一)基于梯度提升的树模型
LightGBM是一个梯度提升决策树(GBDT, Gradient Boosting Decision Tree)算法的改进版本,利用多个决策树的集合来进行学习。GBDT的基本思想是通过迭代地构建一系列弱学习器(通常是决策树)来提升模型的整体性能,每一步都构建一个新的树以减少前一阶段的误差。通过累积的方式使得预测误差不断减少,最终得到一个准确的预测模型。
注:如果要了解 LightGBM 的具体实现原理,可以先看文章XGBoost模型,之后再来看本篇文章,这里我就不反复写啦。在本篇文章,涉及相对于XGBoost,LightGBM有哪些优秀的特点,便于大家选择合适的模型。大佬的话就当我在说废话吧hhhh
(二)叶子生长策略(Leaf-wise Growth)
传统的GBDT通常采用层级生长(Level-wise Growth)方式,即每一层的节点同时扩展,直到达到预设深度。而LightGBM采用叶子生长策略,即每次选择增益最大的叶子节点继续分裂。叶子生长能够显著降低训练时间,因为它更加有选择性,只扩展当前最有助于提升模型效果的节点。不过,这种策略会导致树结构不平衡,容易产生过拟合,因此需要使用正则化和控制树的最大深度来缓解。
-
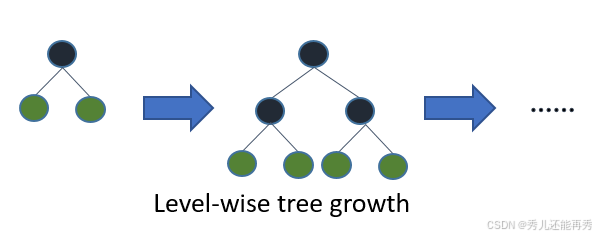
层级生长(Level-wise Growth): 传统GBDT通常采用层级生长策略,即每次在当前层中的所有节点上都进行分裂,保证所有叶子节点的深度相同。这种策略较为简单,但会浪费大量计算资源在效果有限的节点上,尤其在数据量较大时,效率较低。
-
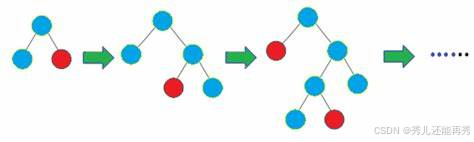
叶子生长(Leaf-wise Growth): LightGBM采用叶子生长策略,即在每一轮中,只选择增益最大的叶子节点进行分裂,而不是让所有节点都分裂。这种策略使得模型能够更好地聚焦于最具提升潜力的节点,从而加速模型训练,同时也在相同树深度下实现更好的性能。
示例图1(层级生长):
示例图2(叶子生长):
(三) 直方图算法(Histogram-based Algorithm)
LightGBM引入了直方图算法来加速特征分裂的过程。它将连续的特征值离散化成一定数量的bins(区间),每个bin代表一段连续的特征值范围。训练过程中,LightGBM会根据这些bins计算每个分裂点的增益值,从而减少了计算量并加快了分裂速度。此外,直方图算法在内存占用上也更高效,因为它只需要存储每个bin的统计信息,而非每个样本的特征值。
(四)GOSS单侧采样(Gradient-based One-Side Sampling)
在处理大规模数据时,LightGBM引入了基于梯度的单侧采样(GOSS)策略。GOSS的核心思想是对梯度绝对值较大的样本保留较高的比例,而对梯度较小的样本随机采样。因为梯度大的样本通常对模型的更新更为重要,因此这种策略能够保留更多关键信息,同时显著减少样本数量,加速训练过程。
(五)特征捆绑技术(EFB)
为了进一步提高效率,LightGBM提出了排他特征捆绑(EFB)技术。EFB通过将互斥的稀疏特征捆绑在一起,减少了特征的维数。互斥特征是指在一个样本中不会同时取非零值的特征,例如在一个文本分类任务中,某些词汇不会同时出现。将这些特征打包为一个特征列,从而减少计算量和内存占用。
(六)支持并行和分布式训练
LightGBM支持特征并行和数据并行。特征并行指的是多个工作节点分配到不同的特征上,减少在计算分裂点时的特征遍历时间。而数据并行则将数据划分到不同的机器中,每个机器上训练子集数据的模型,再将结果合并。这使得LightGBM能够高效处理大规模数据集,尤其在分布式环境中表现出色。
(七)高效的正则化
为了控制模型的复杂度和防止过拟合,LightGBM提供了多种正则化手段,包括L1、L2正则化以及对叶节点数和树深的控制。此外,通过设置最大深度、最小数据量等参数,可以防止树的过拟合问题,提升模型的泛化能力。
LightGBM 与 XGBoost 对比
(一)树的生长方式
-
XGBoost:
-
按层生长(Level-wise growth):XGBoost 使用传统的按层生长策略,即每次扩展树的所有层级,直到树的每一层都填充完。这种策略在每一层都尝试平衡树的深度,有时可能导致树的结构较为均匀,但并不一定是最优的。
-
-
LightGBM:
-
按叶生长(Leaf-wise growth):LightGBM 使用按叶子生长的策略。每次分裂时,它选择增益最大的叶子节点进行扩展。这使得树的深度较大,能够更快速地拟合训练数据,通常会提高模型的准确性。
-
优点:按叶子生长通常能带来更高的预测准确率,因为它更集中地拟合最难预测的部分。
-
缺点:按叶生长可能导致过拟合,尤其是当树的深度很大时,因此需要更多的正则化措施来避免过拟合。
-
(二)特征处理与数据格式
-
XGBoost:
-
XGBoost 对数据进行优化,可以处理稀疏数据集,并且可以处理不同的数据类型(连续、类别等)。XGBoost 对类别特征的处理相对简单,通常需要通过手动编码(如独热编码)将类别变量转化为数值型特征。
-
-
LightGBM:
-
LightGBM 自带对类别特征的处理机制,能够直接处理原始的类别特征,而不需要手动进行独热编码(One-Hot Encoding)。它通过特殊的类别特征分裂策略(如基于统计信息的分裂方法)来处理类别数据,减少了内存消耗和计算复杂度。
-
特征桶化(Bin):LightGBM 会通过将连续特征离散化成多个桶(bin)来加速训练过程,这个过程通过直方图的方式进行。
-
(三)训练过程中的优化
-
LightGBM:
-
直方图优化:LightGBM 使用直方图来优化数据存储和分裂点计算,将数据离散化成多个区间(桶)。这种方法在特征分裂时大大减少了计算的复杂度,因为只需要在桶的基础上进行分裂增益的计算,而不需要考虑每个样本。
-
单边梯度优化(GOSS):LightGBM 引入了 GOSS 技术,通过保留梯度较大的样本并随机采样梯度较小的样本,来减少计算量而不牺牲模型精度。
-
类别特征的高效处理:LightGBM 对类别特征的优化非常高效,减少了对内存的使用和计算时间。
-
(四)并行化与分布式训练
-
XGBoost:
-
XGBoost 支持数据并行和模型并行。数据并行是指将训练数据分配到多个机器或 CPU 核心上,模型并行则是在不同的树或不同的叶子节点上进行并行计算。
-
在分布式环境中,XGBoost 采用了一种类似于 MapReduce 的框架来处理分布式训练,但在处理非常大规模数据时,性能可能不如 LightGBM。
-
-
LightGBM:
-
LightGBM 支持高效的分布式训练。它对数据和任务进行了更精细的划分,可以在多机多卡环境下进行高效的并行训练。LightGBM 可以在多台机器上分布式训练,处理大规模数据时,通常会比 XGBoost 更加高效。
-
(五)使用场景对比
-
XGBoost:在许多传统机器学习任务中,XGBoost 的表现非常优秀,尤其在小数据集或中等规模的数据集上,经过精心调节参数后能获得非常高的准确性。
-
LightGBM:特别适合大规模数据集和高维稀疏数据,在内存使用和训练速度上有显著优势。LightGBM 在大规模机器学习和工业应用中往往表现得更为高效。
选择建议:
-
如果数据集比较小或者中等,且需要非常高的精度,XGBoost 是一个不错的选择。
-
如果数据集非常大,特别是具有大量特征和稀疏特征的情况,LightGBM 更为适用。
# 文章内容来源于各渠道整理。若对大噶有帮助的话,希望点个赞支持一下叭!
# 文章如有错误,欢迎大噶指正!
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 机器学习: LightGBM模型(优化版)——高效且强大的树形模型

发表评论 取消回复