温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
温馨提示:文末有 CSDN 平台官方提供的学长联系方式的名片!
作者简介:Java领域优质创作者、CSDN博客专家 、CSDN内容合伙人、掘金特邀作者、阿里云博客专家、51CTO特邀作者、多年架构师设计经验、多年校企合作经验,被多个学校常年聘为校外企业导师,指导学生毕业设计并参与学生毕业答辩指导,有较为丰富的相关经验。期待与各位高校教师、企业讲师以及同行交流合作
主要内容:Java项目、Python项目、前端项目、PHP、ASP.NET、人工智能与大数据、单片机开发、物联网设计与开发设计、简历模板、学习资料、面试题库、技术互助、就业指导等
业务范围:免费功能设计、开题报告、任务书、中期检查PPT、系统功能实现、代码编写、论文编写和辅导、论文降重、长期答辩答疑辅导、腾讯会议一对一专业讲解辅导答辩、模拟答辩演练、和理解代码逻辑思路等。
收藏点赞不迷路 关注作者有好处
文末获取源码
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助更多的人
介绍资料
Python+大模型农产品价格预测系统
摘要
随着信息技术和大数据的发展,农产品价格预测在市场分析和决策中起着越来越重要的作用。本文介绍了一个基于Python和大型机器学习模型的农产品价格预测系统。该系统通过爬虫技术从农业信息网站获取农产品价格数据,并利用多种大型机器学习模型(如线性回归模型、ARIMA模型、随机森林模型、Prophet模型等)进行价格预测。同时,利用Flask框架构建了一个Web端界面,用户可以通过该界面查询特定产品或多个产品的价格预测结果。该系统为农民、消费者和经销商提供了决策支持,有助于农业生产和农产品贸易的顺利进行。
引言
农产品价格预测在现代农业领域中具有重大意义。它不仅有助于农民合理安排农作物的种植和销售,还能帮助消费者和经销商做出更明智的购买和库存决策。传统的价格预测方法往往依赖于经验判断和简单的统计分析,预测精度有限。随着大数据和机器学习技术的发展,利用历史数据进行价格预测成为可能。本文旨在构建一个基于Python和大型机器学习模型的农产品价格预测系统,以提高预测精度和实时性。
系统架构
数据获取与存储
系统使用Python的爬虫技术从农业信息网站(如惠农网)获取农产品价格数据,包括产品名称、日期和价格等关键信息。数据获取后,利用数据库进行存储,以便后续的数据分析和预测。
数据处理与分析
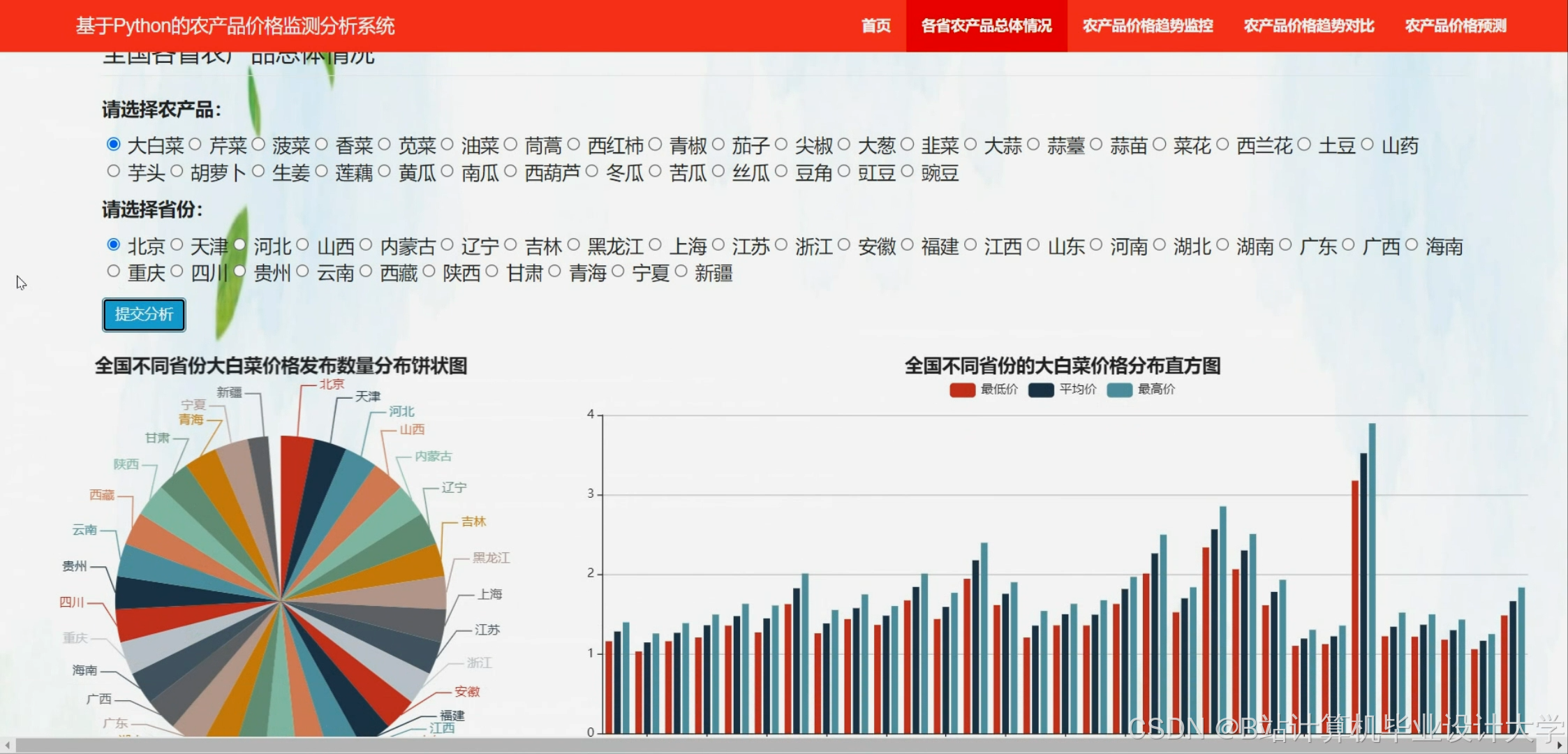
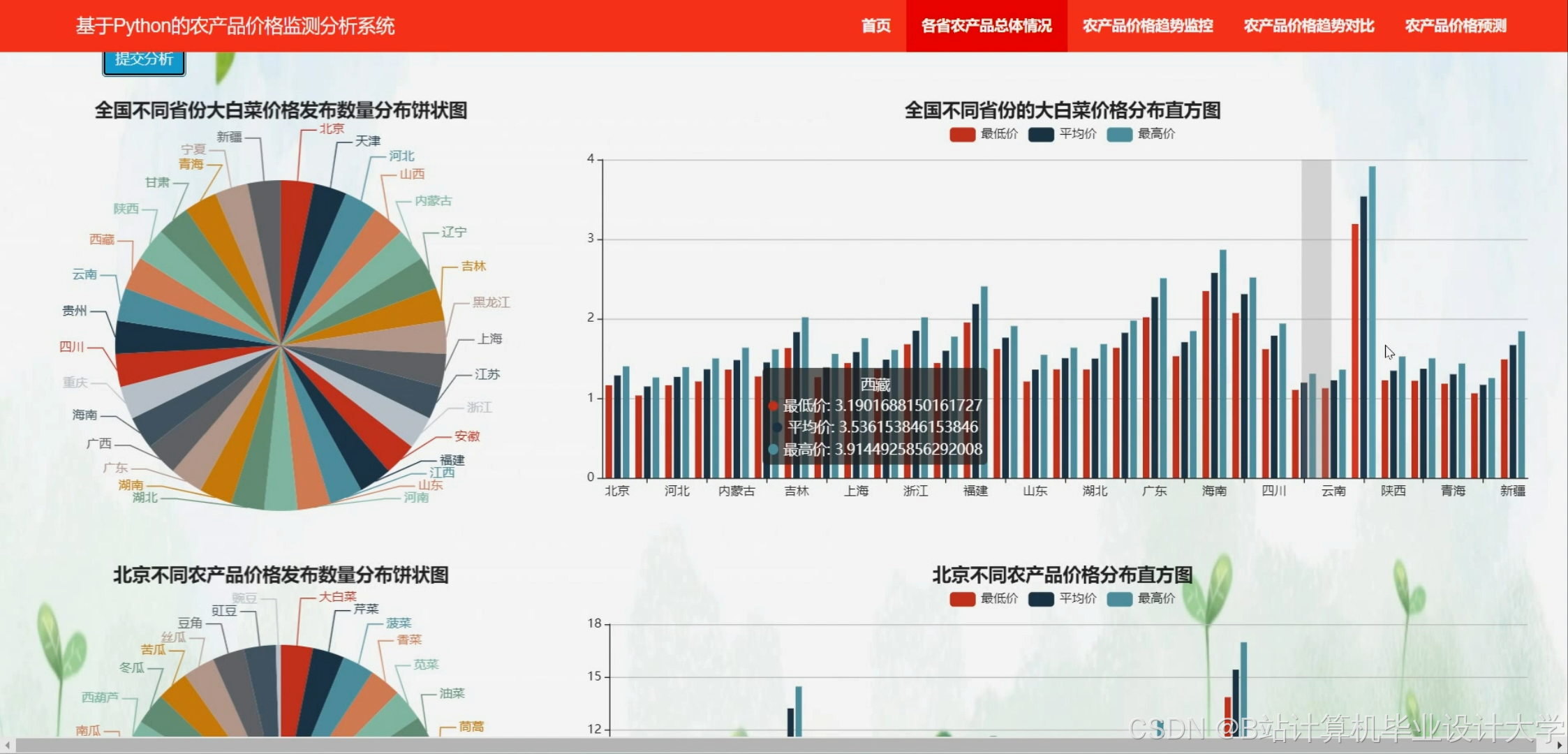
系统使用Pandas库对数据库中的数据进行处理,包括数据清洗、特征选择和归一化等步骤。数据清洗主要针对周期性特征、重复值、离群值以及节假日波动进行处理。特征选择则通过格兰杰因果关系检验等方法筛选出与农产品价格高度相关的影响因素。
模型构建与预测
系统构建了多种大型机器学习模型进行价格预测,包括线性回归模型、ARIMA模型、随机森林模型和Prophet模型等。每种模型都有其独特的优势,如线性回归模型简单易懂,ARIMA模型适用于时间序列数据,随机森林模型能有效捕捉价格变化趋势,Prophet模型则具有应对周期性特征、节假日效应和异常值的能力。
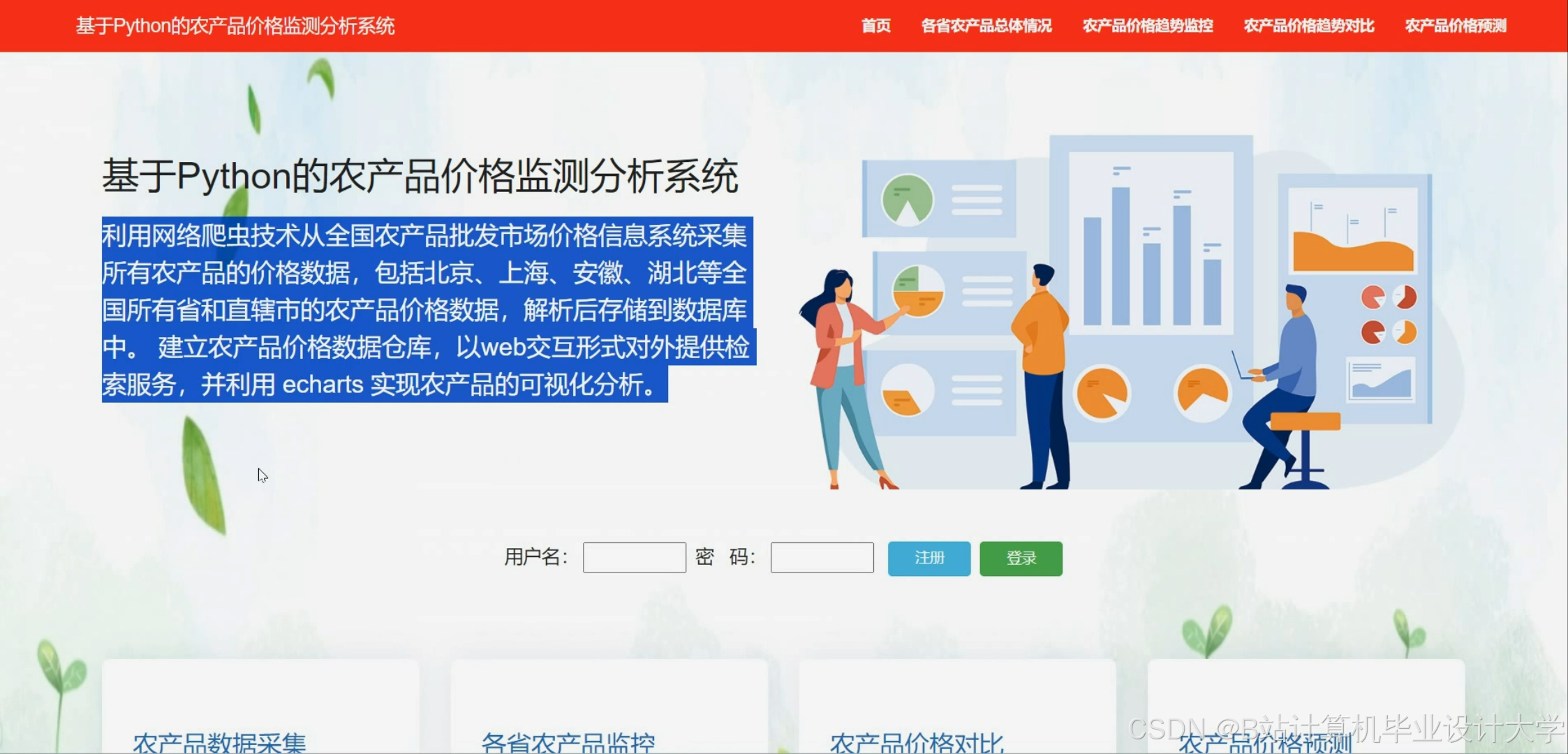
Web端界面
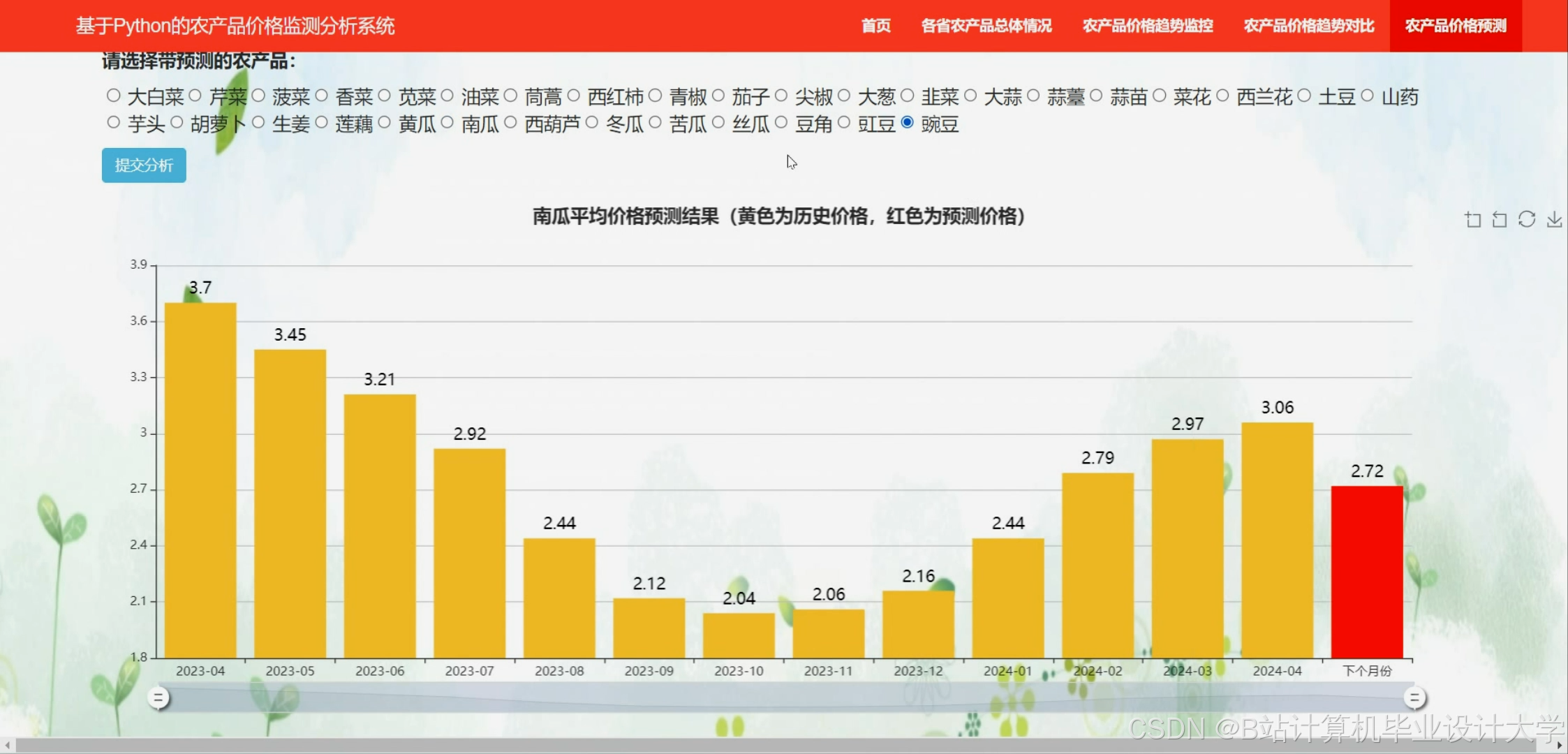
系统利用Flask框架构建了一个Web端界面,用户可以通过该界面查询特定产品或多个产品的价格预测结果。同时,系统还提供了可视化展示功能,包括历史价格趋势图、预测价格曲线等,帮助用户更直观地了解价格动态。
系统实现
数据获取
使用requests库编写爬虫脚本,定时从农业信息网站抓取农产品价格数据,并将数据存储到数据库中。
数据处理
利用Pandas库对数据库中的数据进行处理,包括缺失值填补、异常值处理、归一化等步骤。同时,使用格兰杰因果关系检验筛选出与农产品价格高度相关的影响因素。
模型训练与预测
- 线性回归模型:使用sklearn库中的LinearRegression模型进行训练和预测。
- ARIMA模型:使用statsmodels库中的ARIMA模型进行时间序列预测。
- 随机森林模型:使用sklearn库中的RandomForestRegressor模型进行训练和预测。
- Prophet模型:使用fbprophet库中的Prophet模型进行趋势预测,并加入节假日效应。
Web端界面开发
使用Flask框架构建Web应用,定义路由和视图函数,支持GET和POST请求方法。用户可以通过Web界面选择产品和时间范围,系统根据用户输入调用相应的预测函数,并将预测结果渲染到模板中展示给用户。
系统测试与评估
测试数据集
使用从农业信息网站获取的实际农产品价格数据作为测试数据集,包括多种产品和不同时间范围的数据。
评估指标
使用均方误差(MSE)、均方根误差(RMSE)和平均绝对误差(MAE)等指标对模型的预测性能进行评估。
结果分析
实验结果表明,随机森林模型和Prophet模型在农产品价格预测中表现较好,能够有效捕捉价格变化趋势,为市场参与者提供决策支持。
结论与展望
本文介绍了一个基于Python和大型机器学习模型的农产品价格预测系统。该系统通过爬虫技术获取农产品价格数据,并利用多种大型机器学习模型进行价格预测。同时,利用Flask框架构建了一个Web端界面,用户可以通过该界面查询价格预测结果。实验结果表明,该系统在农产品价格预测中具有较高的精度和实时性,为农业生产和农产品贸易提供了有力支持。
未来,我们将继续优化和完善系统功能,提高预测精度和用户体验。同时,我们将探索更多的机器学习模型和算法,以适应不同市场和产品的需求。此外,我们还将考虑将系统扩展到其他领域,如股票价格预测、房地产价格预测等,以进一步拓展系统的应用范围和价值。
运行截图
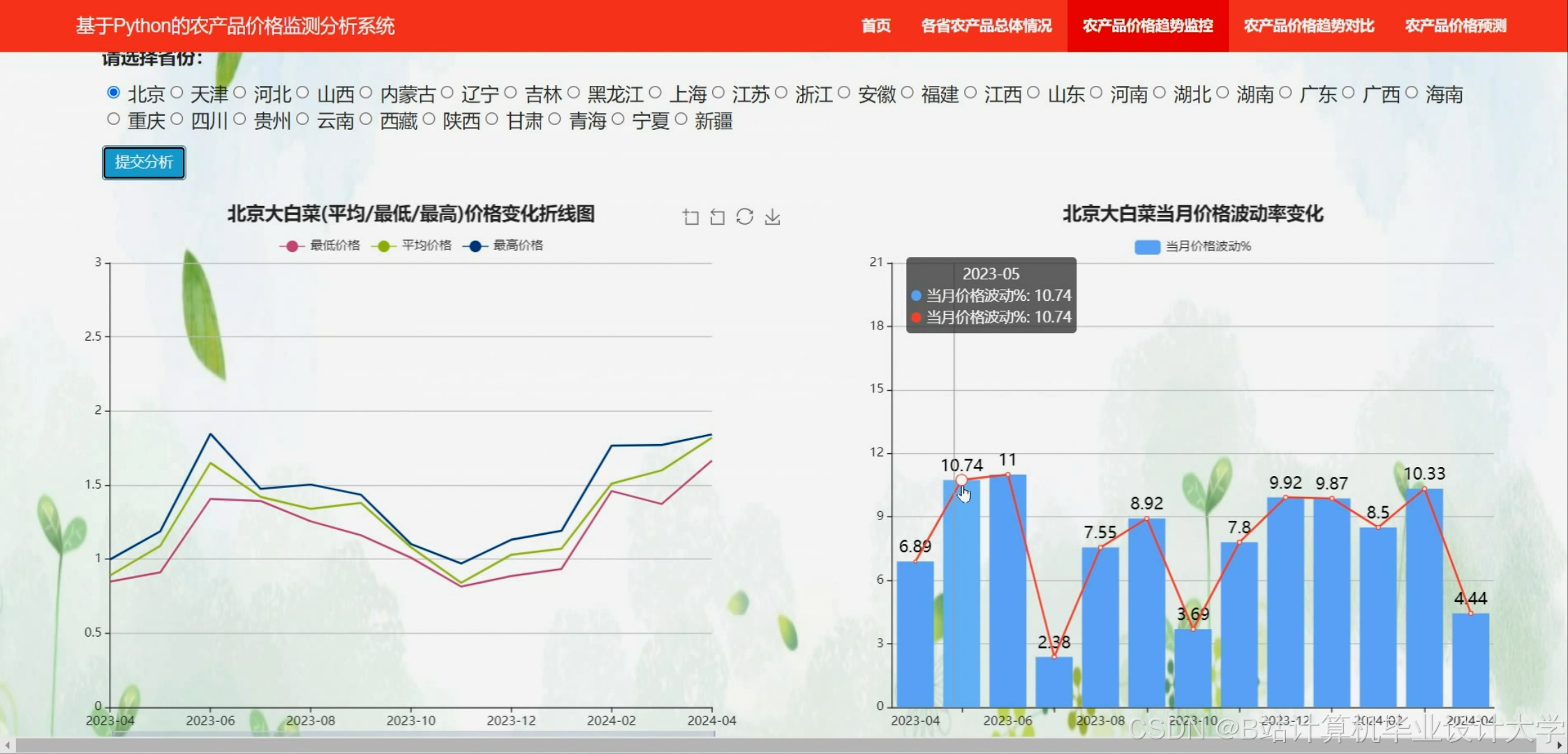
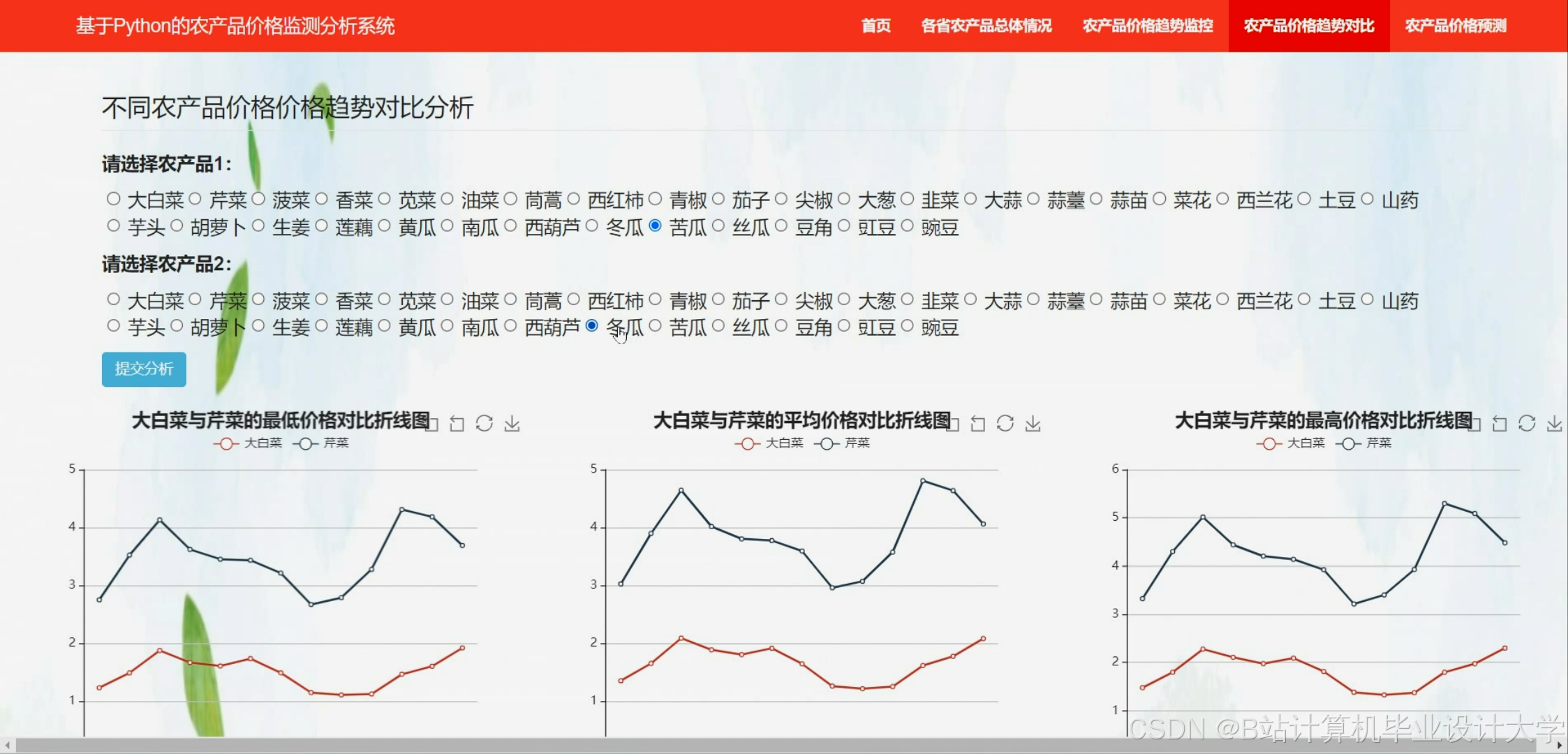
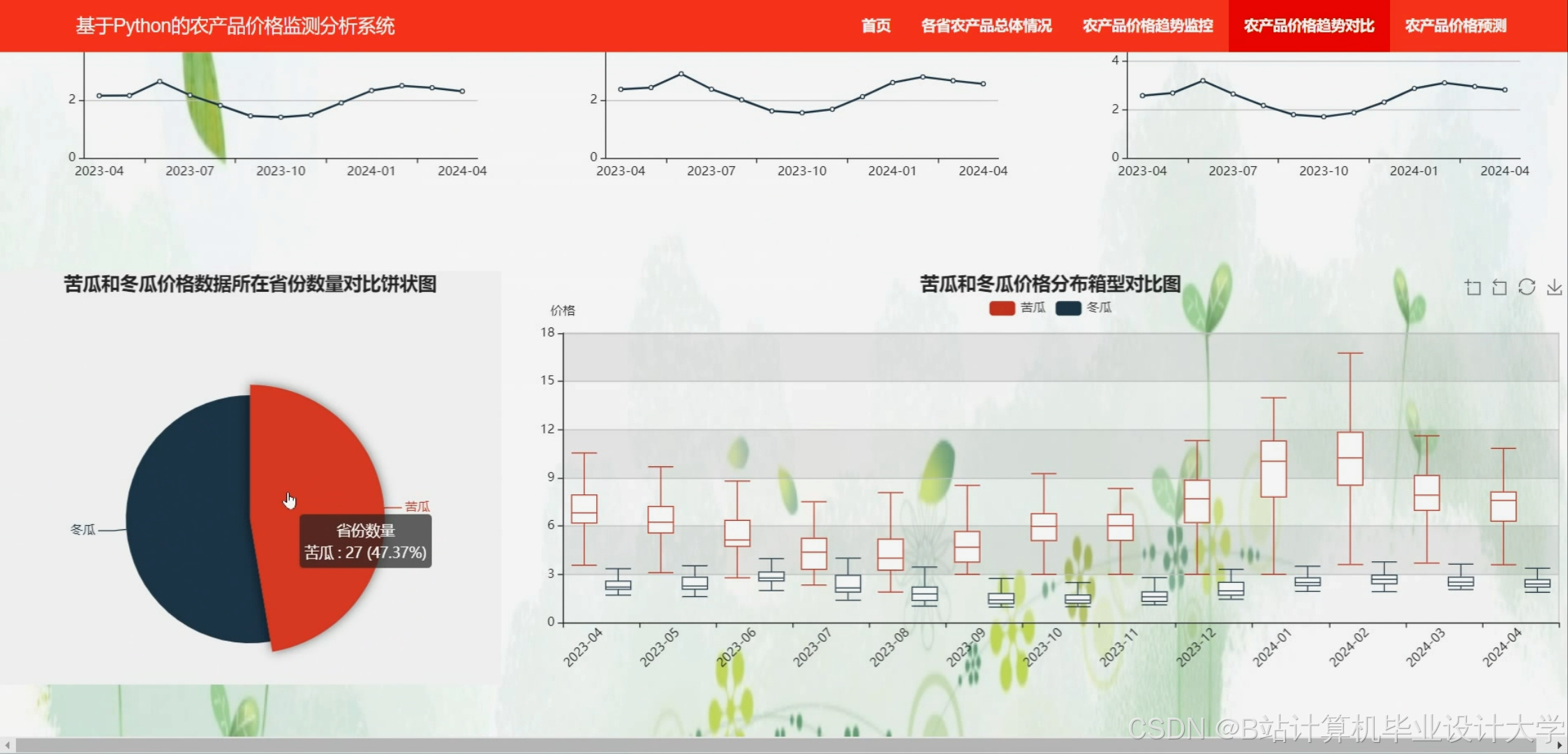
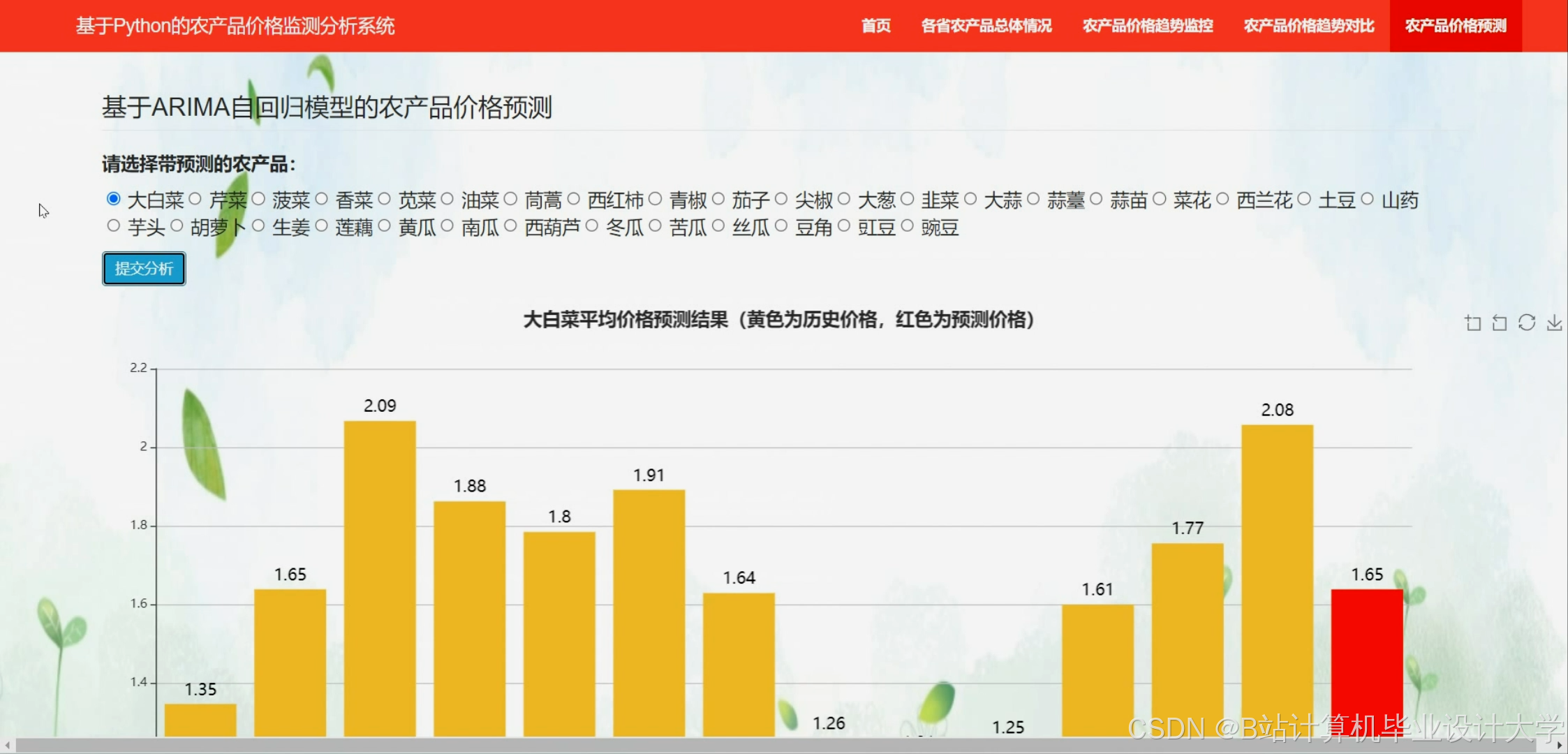
下面是一段使用ARIMA(AutoRegressive Integrated Moving Average,自回归积分滑动平均)模型实现农产品价格预测的Python代码。这段代码使用了statsmodels库,这是一个流行的统计建模库,它提供了ARIMA模型的实现。
首先,你需要确保你的Python环境中安装了必要的库,包括pandas、numpy、statsmodels和matplotlib(用于可视化)。你可以使用pip来安装这些库:
pip install pandas numpy statsmodels matplotlib然后,你可以使用以下代码来加载数据、拟合ARIMA模型并进行预测:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.tsa.arima.model import ARIMA
from sklearn.metrics import mean_squared_error
# 假设你已经有一个包含农产品价格数据的CSV文件,文件名为'agricultural_prices.csv'
# 数据格式应为:日期(Date),价格(Price)
data = pd.read_csv('agricultural_prices.csv', parse_dates=['Date'], index_col='Date')
# 检查数据的前几行
print(data.head())
# 绘制价格时间序列图
plt.figure(figsize=(10, 6))
plt.plot(data['Price'], label='Agricultural Prices')
plt.title('Agricultural Prices Over Time')
plt.xlabel('Date')
plt.ylabel('Price')
plt.legend()
plt.show()
# 分割数据为训练集和测试集
# 这里我们使用前80%的数据作为训练集,后20%的数据作为测试集
train_size = int(len(data) * 0.8)
train, test = data[:train_size], data[train_size:]
# 拟合ARIMA模型
# ARIMA模型的参数(p, d, q)需要根据数据的特性进行选择和调优
# 这里我们使用p=1, d=1, q=1作为示例
model = ARIMA(train['Price'], order=(1, 1, 1))
model_fit = model.fit()
# 打印模型摘要
print(model_fit.summary())
# 进行预测
# 这里我们预测未来与测试集相同长度的数据点
forecast_steps = len(test)
forecast = model_fit.forecast(steps=forecast_steps)
forecast_index = pd.date_range(start=test.index[0], periods=forecast_steps, freq=test.index.freq)
forecast_series = pd.Series(forecast, index=forecast_index, name='Forecasted Price')
# 计算预测误差
test_values = test['Price'].values
mse = mean_squared_error(test_values, forecast)
print(f'Mean Squared Error: {mse}')
# 绘制实际值与预测值的对比图
plt.figure(figsize=(10, 6))
plt.plot(train['Price'], label='Training Data')
plt.plot(test['Price'], label='Actual Prices')
plt.plot(forecast_series, label='Forecasted Prices', color='red')
plt.title('ARIMA Model Forecast vs Actual Prices')
plt.xlabel('Date')
plt.ylabel('Price')
plt.legend()
plt.show()在这段代码中:
- 我们首先加载了农产品价格数据,并绘制了时间序列图以查看数据的趋势。
- 然后,我们将数据分割为训练集和测试集。
- 接着,我们拟合了一个ARIMA模型,其中
order=(1, 1, 1)表示自回归项、差分次数和移动平均项的参数分别为1。这些参数的选择通常需要根据数据的自相关函数(ACF)和偏自相关函数(PACF)图来确定,或者通过网格搜索等方法进行调优。 - 我们使用拟合好的模型对测试集的数据进行了预测,并计算了预测误差(均方误差MSE)。
- 最后,我们绘制了实际值与预测值的对比图,以直观地查看模型的预测性能。
请注意,这段代码中的ARIMA模型参数(p, d, q)是示例值,你可能需要根据你的实际数据进行调优以获得更好的预测结果。
推荐项目
上万套Java、Python、大数据、机器学习、深度学习等高级选题(源码+lw+部署文档+讲解等)
项目案例

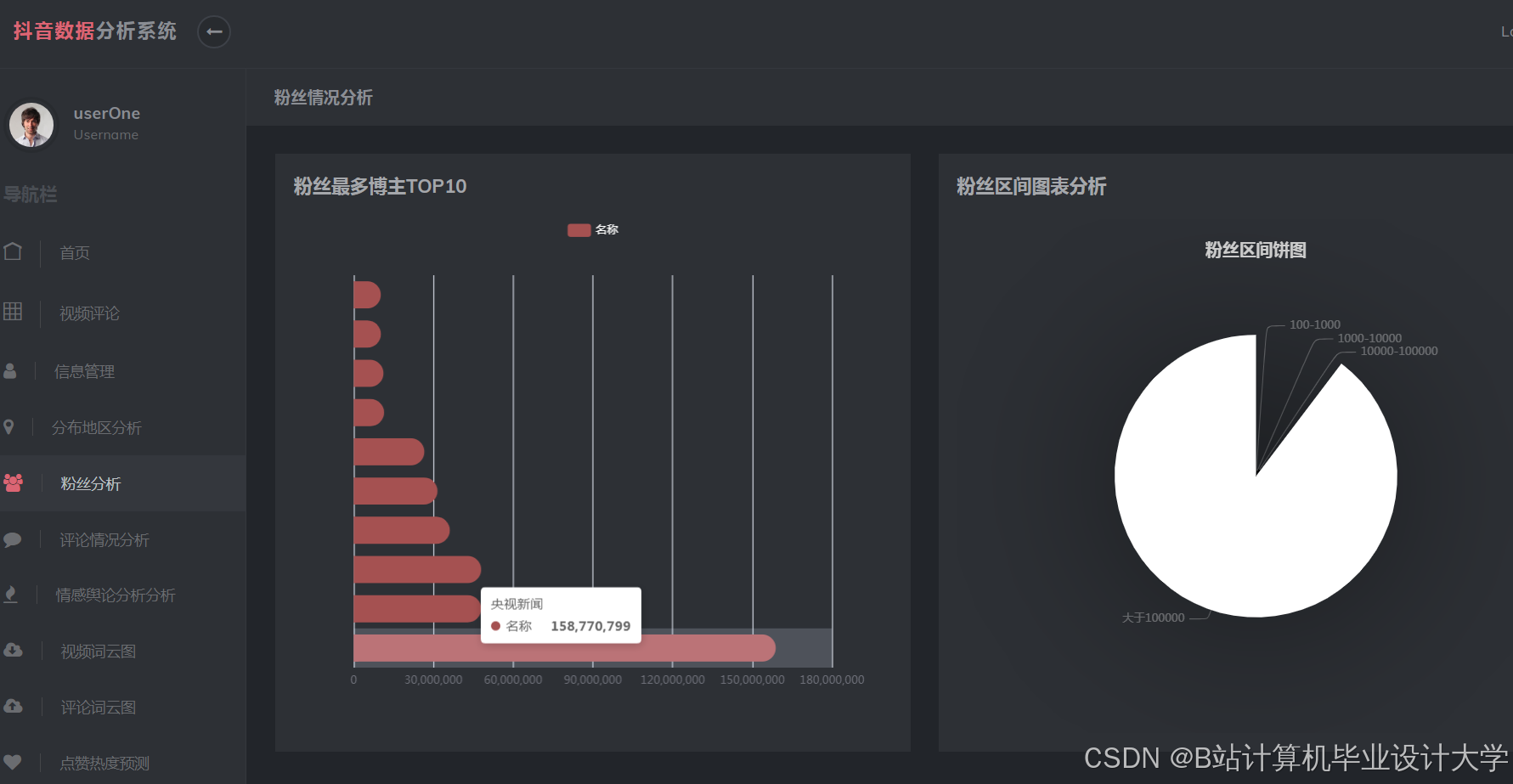
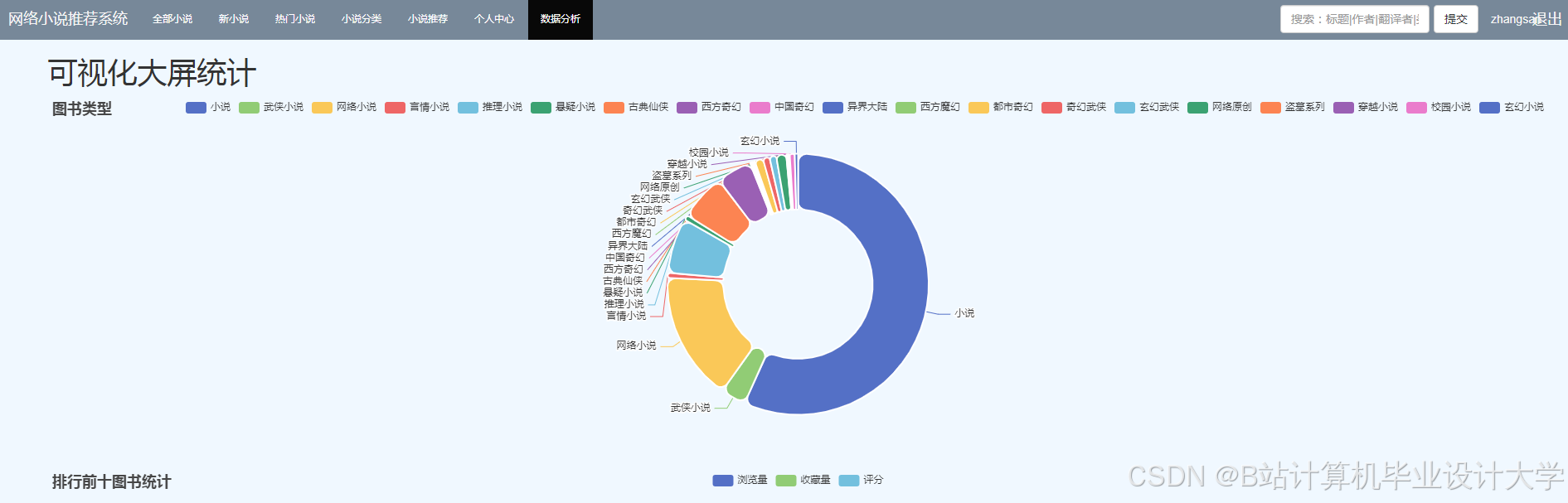
优势
1-项目均为博主学习开发自研,适合新手入门和学习使用
2-所有源码均一手开发,不是模版!不容易跟班里人重复!

感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目代码以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!
源码获取方式
由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。
点赞、收藏、关注,不迷路,下方查看获取联系方式
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 计算机毕业设计Python+大模型农产品价格预测 ARIMA自回归模型 农产品可视化 农产品爬虫 机器学习 深度学习 大数据毕业设计 Django Flask

发表评论 取消回复