近来有些空闲时间,正好最近也在开发HBase相关内容,借此整理一下学习和对HBase组件的架构的记录和个人感受,付出了老夫不少心血啊,主要介绍的就是HBase的架构设计以及我的拓展内容。内容如有不当或有其他理解
matirx70@163.comHBase架构设计
HBase master 架构介绍
hbase master采用主备架构,master与regionserver采用主从架构(即一个HMaster会控制多个regionserver),HBase由zookeeper、HMaster、HRegionServer三部分组成,底层数据存储在HDFS上(存储到HDFS中的是Hfile文件)。
【个人拓展:主备架构和主从架构】
1、主备架构和主从架构有什么区别?
主备架构:只有主库提供读写服务,备库冗余作故障转移用
hadoop中的namenode,一个是master(active),另一个master(standby)
也就是主机节点宕机了,另一台备用节点就会变为active,变为主,这是主备架构
主从架构: master , slave
就是我们namenode 下面挂着datanode ,他们之间的关系是主从,
在CDH的平台上也可以看到它。具体操作如下进入到 HBase ->实例,可以看到Master和Regionserver。
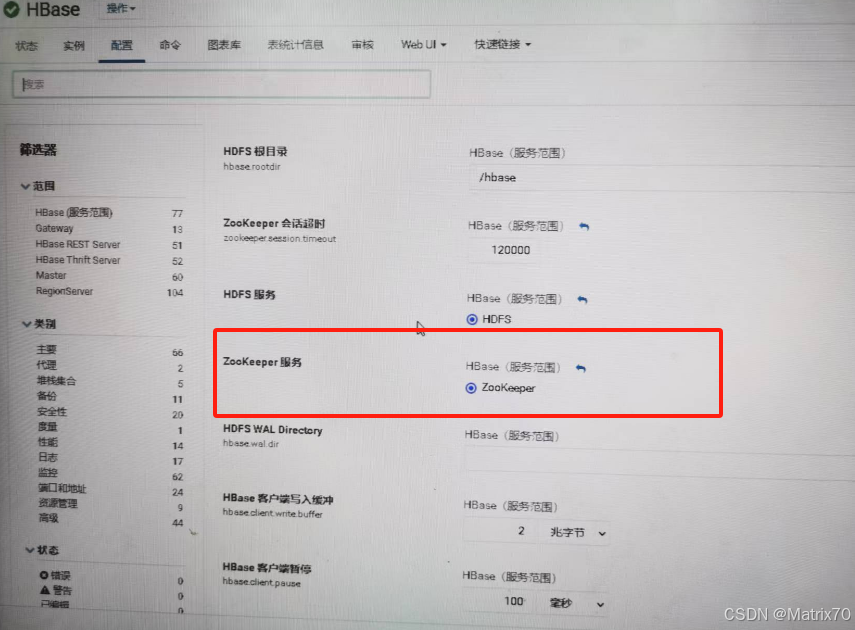
【我自己拍的图】
进入到配置中可以看到ZK,HBase要依赖ZK的,同时在下面有一个HBase的长连接的目录
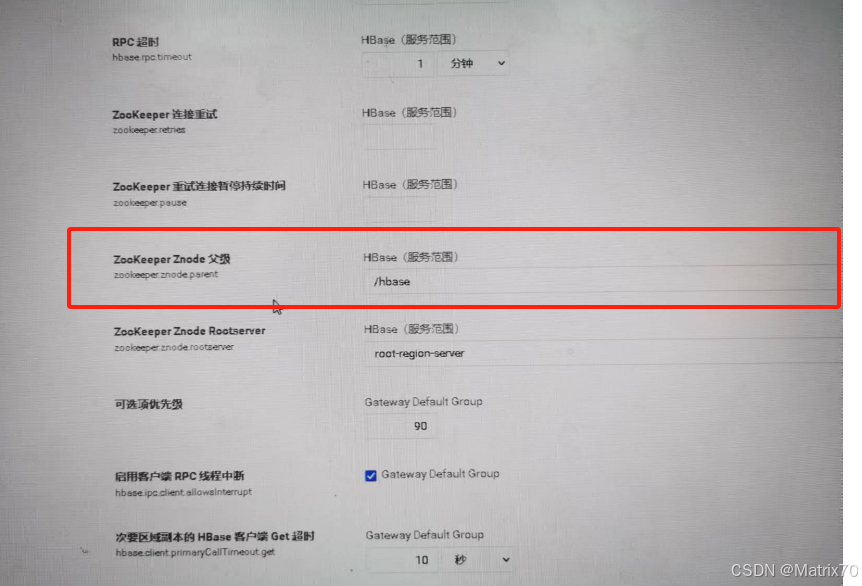
【我自己拍的图】
如何查看这个长连接目录?
# 进入集群,简单看一下zk存在的地方
[root@worker-1 ~]# zookeeper-client
[zk: localhost:2181(CONNECTED) 0] ls /
[hive_zookeeper_namespace_hive, zookeeper, ngdata, hbase, solr]
[zk: localhost:2181(CONNECTED) 1] ls /hbase
[meta-region-server, rs, splitWAL, backup-masters, table-lock, flush-table-proc, master-maintenance, online-snapshot, acl, switch, master, running, tokenauth, draining, namespace, hbaseid, table]
[zk: localhost:2181(CONNECTED) 2] ls /hbase/master
[]
#f防伪标识:作者csdn: matrix70 ---> xidaolaoli HBase官方架构图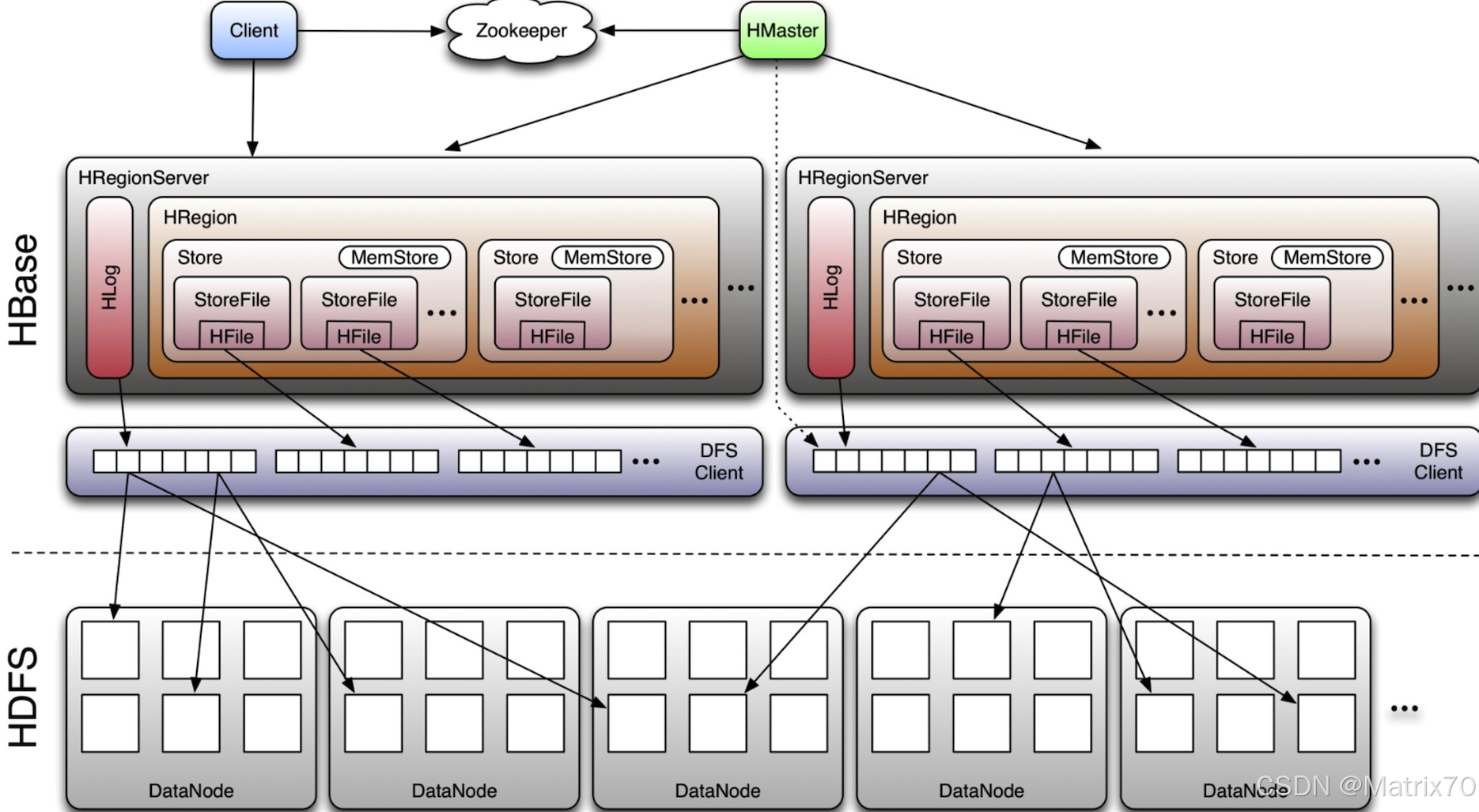
【HBase官方架构图】
【个人经验拓展架构图理解】
这个官方的架构图有歧义,在Memstore溢写时,溢写到StoreFile中,StoreFile中实际存储的是HFile文件,StoreFile实际存储在HDFS上,即图中StoreFile应放在HDFS中,而不应该划分到Region中,这就是有歧义的地方。后续我会给出一个新的架构图。
要记住这个Hlog是做什么的,一个regionserver下面只有一个Hlog,wal这里还有一个协处理器,可二次开发,但是要注意我们处理器是监控不了我们的TSV + bulkload的,基于HBase底层做二次开发的,要注意这一个点,协比如麒麟做一个二次开发。这是题外话了,我在这里简单扩展一下。
简述官方架构图功能:
Client客户端
Client客户端,它提供了访问HBase的接口,并且维护了对应的cache来加速HBase的访问。
Zookeeper
存储HBase的元数据(meta表),无论是读还是写数据,都是去Zookeeper里边拿到meta元数据告诉给客户端去哪台机器读写数据
HRegionServer regionServer 服务器端
它是处理客户端的读写请求,负责与HDFS底层交互,是真正干活的节点。
总结大致的流程就是:client请求到Zookeeper,然后Zookeeper返回HRegionServer地址给client,client得到Zookeeper返回的地址去请求HRegionServer,溢写HRegionServer读写数据后返回给client。
HBase 架构组件介绍
HMaster
HBase引入zookeeper,避免HMaster单点问题,HMaster主要负责table和region的管理工作:
1 )管理用户的读写操作
2 )管理HRegionServer的负载均衡,调整region分布,这是region切分的时候要用的
3 )region split后,负责新region重分
4 )在HRegionServer停机后,负责失效的HRegionServer上region的迁移,如果这个HRS服服务挂了,那么Master会把RegionServer中的Region中的数据迁移到正常的HRS中
【个人扩展-->如何解决主备的单点问题?】
与Namenode的单点问题解决方式是同一个,Namenode中单点问题是通过zookeeper解决,即如果主节点挂掉,则zk中的临时节点就会消失,然后备用的节点重新注册一个临时节点,然后它就升级为主节点了。
HRegionServer
是HBase中最核心的模块,也是干活的模块,一般HRegionServer会选择和DataNode部署在同一个节点,实现短路读/数据本地化,HRS主要功能:
1 )维护Region,每个Region下面存着数据的,处理这些Region的IO请求
2 )Regionserver负责切分在运行过程中逐渐变大的Region 一个HRegionServer下面可以有多个Region
HRegion/Region
HBase使用rowkey将表水平切割成多个HRegion/Region.
【个人拓展理解-->HRegion】
从HMaster的角度,每个HRegion都记录了startkey和endkey(第一个Region的startkey为空,最后一个Region的endkey为空),由于rowkey是有序的,有序就会做一个索引,因此client端可以通过HMaster快速定位到某个rowkey在哪个HRegion中,不需要全表去扫描了,通过key-value的形式就干出来了。
【个人拓展理解-->Rowkey是如何水平切分HRegion 】
这一个可是精华,学习的时候理解了半天,当然,我还是会用图演示出来方便些,我愿称之为全网最NB的理解,请把NB打在评论区!!
废话不多说:如果建表时未进行预分region,startkey和endkey都为空,则区间为(负无穷,正无穷),随着数据增加,region分裂后会生成新的region,此时startkey和endkey会生成具体的值。

【演示Rowkey是如何水平切分HRegion的】

【演示Region分裂】
【个人拓展->Region是怎样产生的】
1)按照Rowkey预分Region
2)如果没有按照Rowkey预分Region,则当一个Region达到一定的值的时候,会自动进行Region分裂。具体到什么值,后面我会详细来说说,哈哈哈。
HStore/Store
每一个列族对应一个HStore/Store,一个HRegion/Region里包含一个或者多个HStore/Store,由此在设计cf时,尽量将同一系列的数据存在一个列族中,便于同一系列的数据都存在同一个region中。
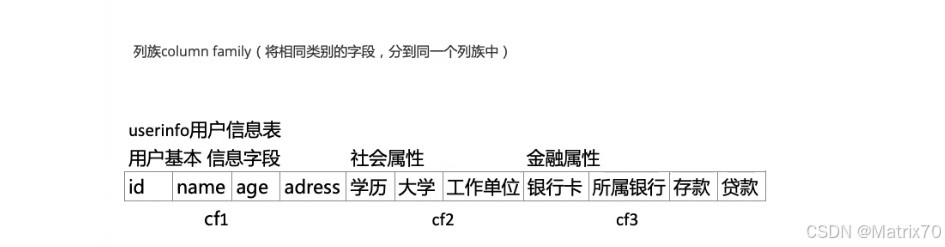
【列族设计】
Hlog
hbase WAL(write ahead log)(预写日志机制),在用户发起写请求时先向Hlog写一份,然后再将数据向memstore中写,Hlog数据是写磁盘,为了避免HRegionServer故障时memstore数据丢失,Hlog并不是无限去存储的,否则就冗余了,他也有阈值,会滚动更新,达到阈值,会提示memstore把数据溢写到HDFS上,等memstore的数据全部溢写到磁盘上,则Hlog的备份的数据会清空,而新数据的加入会对应冲抵掉较早的Hlog数据。
Memstore(阈值128M)
hbase写缓存,在用户发起写请求时先写入hlog,然后再写入memstore中,当memstore写入达到flush阈值时,将memstore中的数据写到hdfs上(hfile),每个列族对应一个memstore,即一个HStore/Store中只有一个memstore。
storefile
当memstore写数据达到设定的阈值之后,会将数据溢写到hdfs,即storefile,内部存储hfile。storefile会进行合并,否则可能出现小文件的问题,当storefile经过多次合并后变得已经达到指定规则的分裂阈值,则再进行region分裂。
HRS、DataNode、table、region、columnfamily、Hstore/store、memstore、storefile关系图,修正了部分
有空补充
参考资料:
1、hbase官网Apache HBase® Reference Guide
2、大神给我的讲解
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » HBase理论_HBase架构组件介绍

发表评论 取消回复