文章目录
1.文章概要
学习Python爬虫知识,实现简单的一个小案例,网易云音乐热歌榜歌曲
1.1 实现方法
本文使用Python中常用的requests库来实现的
1.2 实现代码
以下是本项目全部代码
# author by mofitte
# vx:mofitte
# date 2024年11月13日
import requests,re,os
filename = 'music\\'
if not os.path.exists(filename):
os.makedirs(filename)
url = "https://music.163.com/discover/toplist?id=3778678" # 网易云音乐热歌榜单页面
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36'}
response = requests.get(url, headers=headers)
# print(response.text)
html_data = re.findall('<li><a href="/song\?id=(\d+)">(.*?)</a>', response.text)
for song_id, song_name in html_data:
music_url = f'http://music.163.com/song/media/outer/url?id={song_id}.mp3'
# 对于音乐播放地址发送请求 获取二进制数据内容
music_content = requests.get(url=music_url, headers=headers).content
with open(filename + song_name + '.mp3', mode='wb') as f:
f.write(music_content)
print(song_id, song_name)
print('爬虫任务已完成')
1.3 最终效果
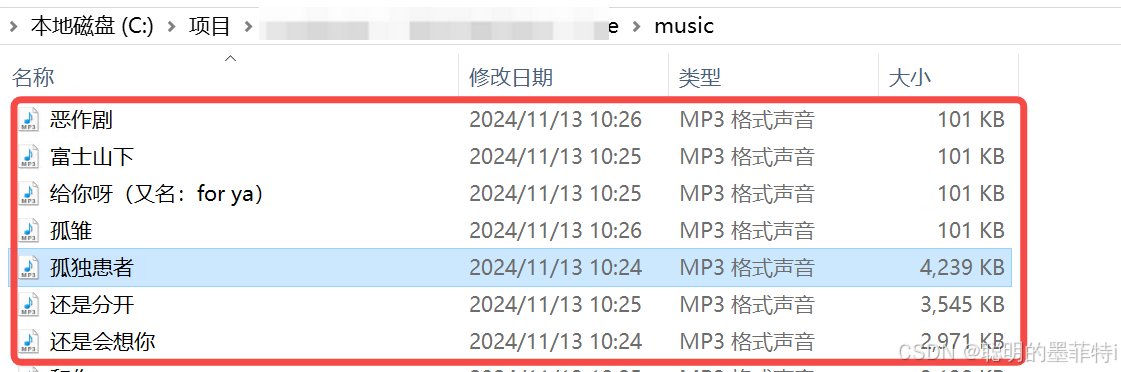
2.具体讲解
2.1 使用的Python库
1.requests:一个简单易用的 Python 库,用于发送 HTTP 请求;
2.os: Python 的一个内置库,提供了许多操作文件和目录的功能;
3.re:用于处理正则表达式,它提供了一系列功能强大的函数,用于字符串的搜索、替换、匹配等操作;
2.2 代码说明
2.2.1 创建目录保存文件
# author by mofitte
# vx:mofitte
# date 2024年11月13日
import requests,re,os
filename = 'music\\'
if not os.path.exists(filename):
os.makedirs(filename)
在PC上创建filename目录(这里我用的是Windows系统),用于保存后续爬取下来的音乐文件;
2.2.2 爬取网易云音乐热歌榜单歌曲
url = "https://music.163.com/discover/toplist?id=3778678" # 网易云音乐热歌榜单页面
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36'}
response = requests.get(url, headers=headers)
# print(response.text)
html_data = re.findall('<li><a href="/song\?id=(\d+)">(.*?)</a>', response.text)
for song_id, song_name in html_data:
music_url = f'http://music.163.com/song/media/outer/url?id={song_id}.mp3'
# 对于音乐播放地址发送请求 获取二进制数据内容
music_content = requests.get(url=music_url, headers=headers).content
爬取音乐核心代码块url:这里我选择的是热歌榜单,你也可以直接替换为你想要爬取的榜单,直接运行也是可以的;headers:模拟浏览器行为访问上述url,这个没啥可说的;
response:获取响应,这里是get了url和headers
html_data:获取音乐数据,通过正则表达式匹配音乐id和音乐名称;
music_url:下载音乐路径,可以在浏览器打开试听音乐;
2.3 过程展示
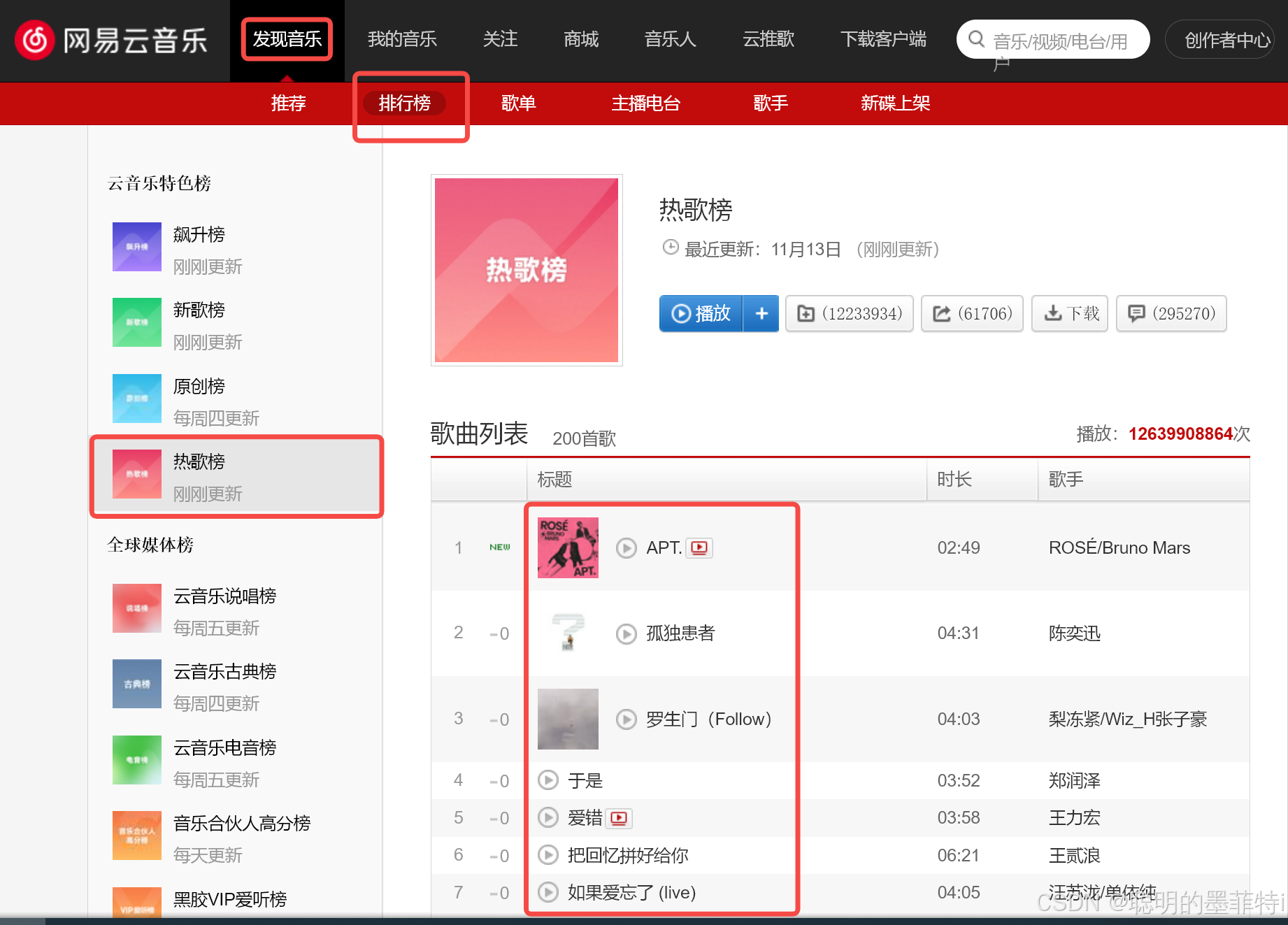
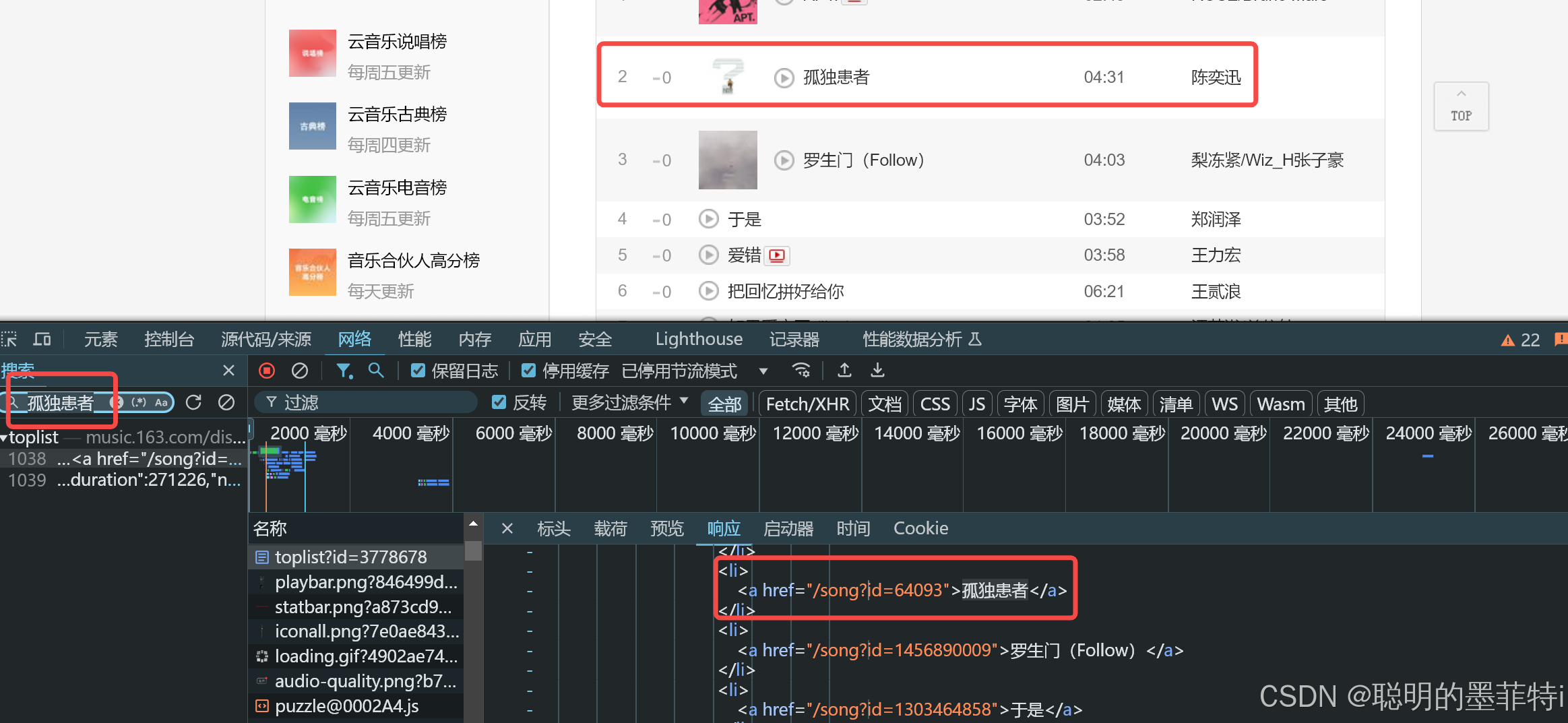

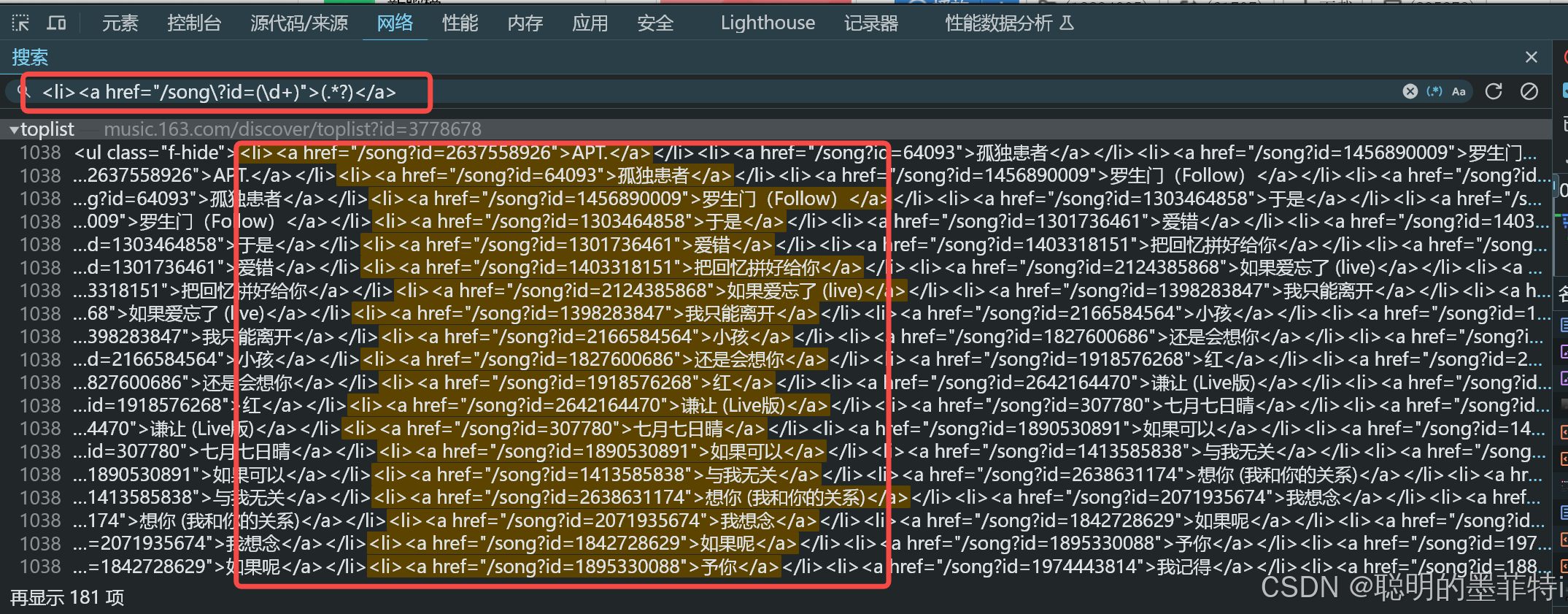
3 总结
本案例是采用了requests库来简单获取数据,下载音乐,过程还是相对简单的;更复杂的内容,可能需要其他技术来实现,继续学习。
看到这里了,我只希望能点个赞,谢谢
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » Python爬虫项目 | 一、网易云音乐热歌榜歌曲

发表评论 取消回复