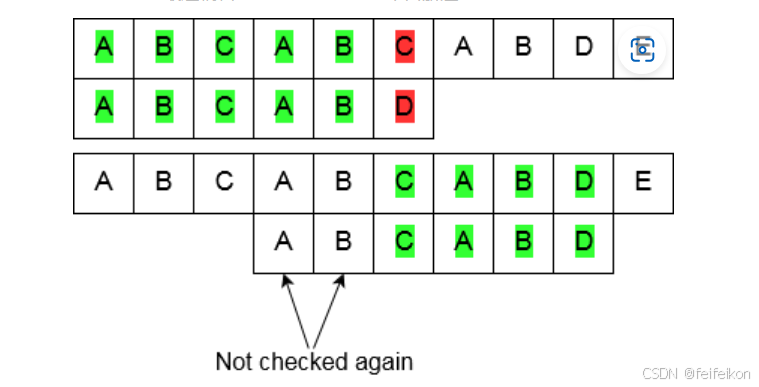

具体解释:
1. 真前缀和真后缀的定义
前缀:字符串的起始部分。例如,字符串 s = "aabcaa" 的前缀是 ""、"a"、"aa"、"aab"、"aabc"、"aabca"、"aabcaa"。
后缀:字符串的结尾部分。例如,字符串 s = "aabcaa" 的后缀是 ""、"a"、"aa"、"caa"、"bcaa"、"abcaa"、"aabcaa"。
真前缀:前缀中去掉整个字符串本身的部分。例如,字符串 s = "aabcaa" 的真前缀是 ""、"a"、"aa"、"aab"、"aabc"、"aabca"。
真后缀:后缀中去掉整个字符串本身的部分。例如,字符串 s = "aabcaa" 的真后缀是 ""、"a"、"aa"、"caa"、"bcaa"、"abcaa"。
2.什么是 border(边界)?
border 的定义:是非空的真前缀和真后缀的交集。
border 的例子:
对于字符串 s = "aabcaa",我们来看其 border:
"a":既是真前缀"a",也是真后缀"a"。"aa":既是真前缀"aa",也是真后缀"aa"。
不属于 border 的部分:
"aab"是真前缀,但不是真后缀,因此不是border。"caa"是真后缀,但不是真前缀,因此也不是border。
3.什么是 π 数组?
- 对于字符串的每个前缀
p[:i],π[i]表示前缀p[:i]的最长border的长度。
π 数组的构造
- 举例说明:对于模式串
p = "aabcaa":p[:1] = "a":最长border长度是0(无border)。:注意此时算的是真前缀和真后缀,a自己不算,因此没有borderp[:2] = "aa":最长border长度是1("a"是border)。p[:3] = "aab":最长border长度是0(无border)。p[:4] = "aabc":最长border长度是0(无border)。p[:5] = "aabca":最长border长度是1("a"是border)。p[:6] = "aabcaa":最长border长度是2("aa"是border)。
- 结果:π 数组为
[0, 1, 0, 0, 1, 2]。
4. 使用 π 数组快速匹配
π 数组的作用是,当在主串中匹配失败时,利用模式串已有的部分匹配信息,快速跳过不必要的比较。
核心思想
- 假设匹配到主串的某个位置时,模式串中某些前缀已经匹配了,此时若失配,可以直接跳过已匹配的部分,从下一个可能的匹配位置开始继续比较。
5. π 数组与 next 数组的关系
国内一些数据结构教材(如严蔚敏的)中,将 π 数组 定义为 next 数组,但存在以下差异:
next[i+1] = π[i] + 1。- π 数组整体右移一位,所有元素值加一。
6. KMP 算法的匹配过程
整体代码(构建 π 数组):
def calculateMaxMatchLengths(pattern):
maxMatchLengths = [0] * len(pattern) # 初始化 π 数组,长度与模式串相同
maxLength = 0 # 当前前缀的最长 border 长度
for i in range(1, len(pattern)): # 从第二个字符开始遍历模式串
# 当 pattern[maxLength] 与 pattern[i] 不匹配时,回退
while maxLength > 0 and pattern[maxLength] != pattern[i]:
maxLength = maxMatchLengths[maxLength - 1] # 回退到之前的最长 border
# 如果当前字符匹配,则扩展 border 长度
if pattern[maxLength] == pattern[i]:
maxLength += 1
maxMatchLengths[i] = maxLength # 记录当前前缀的最长 border 长度
return maxMatchLengths
1.预处理 π 数组
- 通过模式串计算 π 数组,记录模式串中每个前缀的最长
border长度。
2.匹配主串
- 利用 π 数组,在主串中寻找模式串的位置。
- 如果匹配失败,根据 π 数组跳过不必要的比较。
构造 π 数组(前缀函数)
1. 初始化 π 数组
maxMatchLengths = [0] * len(pattern)
- 初始化 π 数组(
maxMatchLengths),其长度与模式串pattern相同。 - π 数组的每个位置记录模式串前缀的最长 border 长度。
- 例如:对于模式串
pattern = "aabcaa",π 数组初始化为[0, 0, 0, 0, 0, 0]。
2. 初始化 maxLength
maxLength = 0 maxLength变量表示当前前缀的最长 border 长度。- 初始为
0,因为第一个字符的前缀没有非空 border。
3. 遍历模式串
for i in range(1, len(pattern)):
- 遍历模式串,从索引
1开始,因为第一个字符没有非空 border(π[0] 固定为0)。
4. 检查字符匹配并回退
while maxLength > 0 and pattern[maxLength] != pattern[i]: maxLength = maxMatchLengths[maxLength - 1]
- 目的:当
pattern[maxLength]和pattern[i]不匹配时,根据 π 数组的值回退,寻找下一个可能的 border。 - 逻辑:
- 如果当前最长 border 的下一个字符(
pattern[maxLength])与当前字符(pattern[i])不匹配,则回退到上一个可能的 border,即maxMatchLengths[maxLength - 1]。 - 为什么?:
- 当前的 border 不匹配时,可以通过 π 数组找到上一个可能的匹配位置,避免从头重新比较。
- 如果当前最长 border 的下一个字符(
5. 扩展 border
if pattern[maxLength] == pattern[i]: maxLength += 1
- 目的:如果当前字符匹配,说明 border 可以延长一位。
maxLength += 1表示当前前缀的最长 border 长度增加。
6. 更新 π 数组
maxMatchLengths[i] = maxLength
- 将当前前缀的最长 border 长度记录到 π 数组中。
运行示例
假设模式串为 pattern = "aabcaa",我们计算 π 数组:
1. 初始化
maxMatchLengths = [0, 0, 0, 0, 0, 0] maxLength = 0
2. 遍历计算
-
i = 1:
pattern[maxLength] = "a",pattern[1] = "a",匹配。maxLength += 1→maxLength = 1maxMatchLengths[1] = 1
i = 2:
pattern[maxLength] = "a",pattern[2] = "b",不匹配。- 回退:
maxLength = maxMatchLengths[maxLength - 1] = maxMatchLengths[0] = 0 maxLength = 0maxMatchLengths[2] = 0
i = 3:
pattern[maxLength] = "a",pattern[3] = "c",不匹配。maxLength = 0maxMatchLengths[3] = 0
i = 4:
pattern[maxLength] = pattern[0] = 'a'pattern[i] = pattern[4] = 'a'- 匹配,
maxLength += 1→maxLength = 1 maxMatchLengths[4] = 1
i = 5:
pattern[maxLength] = pattern[1] = 'a'pattern[i] = pattern[5] = 'a'- 匹配,
maxLength += 1→maxLength = 2 maxMatchLengths[5] = 2
i = 6:
pattern[maxLength] = pattern[2] = 'b'pattern[i] = pattern[6] = 'b'- 匹配,
maxLength += 1→maxLength = 3 maxMatchLengths[6] = 3
函数 search 搜索
1. 初始化
positions = []
maxMatchLengths = calculateMaxMatchLengths(pattern)
count = 0
positions:存储模式串匹配的起始位置。maxMatchLengths:调用calculateMaxMatchLengths函数计算 π 数组。count:记录当前模式串匹配了多少字符。
2. 遍历文本 text
for i in range(len(text)):
遍历文本 text 中的每个字符,逐个比较是否匹配模式串。
3. 回退逻辑
while count > 0 and pattern[count] != text[i]: count = maxMatchLengths[count - 1] - 如果当前字符不匹配,则利用 π 数组回退到上一个可能的匹配位置。
- 如果
count == 0,说明当前没有部分匹配,直接从头开始重新匹配。
4. 匹配逻辑
if pattern[count] == text[i]: count += 1
- 如果当前字符匹配,扩展匹配长度
count。
5. 完整匹配
if count == len(pattern):
positions.append(i - len(pattern) + 1)
count = maxMatchLengths[count - 1]
- 当
count == len(pattern)时,说明模式串完整匹配。 - 记录匹配的起始位置为
i - len(pattern) + 1。 - 利用 π 数组调整
count,以寻找下一个可能的匹配。
完整代码:
class Solution:
def creatneedle(self,mystr:str)->list:
mylist=[0]*len(mystr)
maxlength=0
for i in range(1,len(mystr)):
while maxlength>0 and mystr[i]!=mystr[maxlength]:
maxlength=mylist[maxlength-1]
if mystr[i]==mystr[maxlength]:
maxlength+=1
mylist[i]=maxlength
return mylist
def strStr(self, haystack: str, needle: str) -> int:
mylist = self.creatneedle(needle)
count = 0
for i in range(len(haystack)):
while count>0 and needle[count]!=haystack[i]:
count=mylist[count-1]
if needle[count]==haystack[i]:
count+=1
if count==len(needle):
return i-len(needle)+1
return -1
附灵神企业级理解:
作者:灵茶山艾府
链接:https://www.zhihu.com/question/21923021/answer/37475572
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
角色:
甲:abbaabbaaba
乙:abbaaba
乙对甲说:「帮忙找一下我在你的哪个位置。」
甲从头开始与乙一一比较,发现第 7 个字符不匹配。
要是在往常,甲会回退到自己的第 2 个字符,乙则回退到自己的开头,然后两人开始重新比较。[1]这样的事情在字符串王国中每天都在上演:不匹配,回退,不匹配,回退,……
但总有一些妖艳字符串要花自己不少的时间。
上了年纪的甲想做出一些改变。于是乎定了个小目标:发生不匹配,自身不回退。
甲发现,若要成功与乙匹配,必须要匹配 7 个长度的字符。所以就算自己回退到第 2 个字符,在后续的匹配流程中,肯定还会重新匹配到自己的第 7 个字符上。
当在甲的某个字符 c 上发生不匹配时,甲即使回退,最终还是会重新匹配到字符 c 上。
那干脆不回退,岂不美哉!
甲不回退,乙必须回退地尽可能少,并且乙回退位置的前面那段已经和甲匹配,这样甲才能不用回退。
如何找到乙回退的位置?
「不匹配发生时,前面匹配的那一小段 abbaab 于我俩是相同的」,甲想,「这样的话,用 abbaab 的头部去匹配 abbaab 的尾部,最长的那段就是答案。」
abbaab 的头部有 a, ab, abb, abba, abbaa(不包含最后一个字符。下文称之为「真前缀」)
abbaab 的尾部有 b, ab, aab, baab, bbaab(不包含第一个字符。下文称之为「真后缀」)
这样最长匹配是 ab。也就是说甲不回退时,乙需要回退到第三个字符去和甲继续匹配。「要计算的内容只和乙有关」,甲想,「那就假设乙在其所有位置上都发生了不匹配,乙在和我匹配前把其所有位置的最长匹配都算出来(算个长度就行),生成一张表,之后我俩发生不匹配时直接查这张表就行。」
据此,甲总结出了一条规则并告诉了乙:
所有要与甲匹配的字符串(称之为模式串),必须先自身匹配:对每个子字符串 [0...i],算出其「相匹配的真前缀与真后缀中,最长的字符串的长度」。
「小 case,我对自己还不了解吗」,乙眨了一下眼睛,「那我回退到第三个字符和你继续匹配吧~」
新的规则很快传遍了字符串王国。现在来看看如何高效地计算这条规则。这里有个很好的例子:abababzabababa。
列个表手算一下:(最大匹配数为子字符串 [0...i] 的最长匹配的长度)
子字符串 a b a b a b z a b a b a b a
最大匹配数 0 0 1 2 3 4 0 1 2 3 4 5 6 ?一直算到 6 都很容易。在往下算之前,先回顾下我们所做的工作:
对子字符串 abababzababab 来说,
真前缀有 a, ab, aba, abab, ababa, ababab, abababz, ...
真后缀有 b, ab, bab, abab, babab, ababab, zababab, ...
所以子字符串 abababzababab 的真前缀和真后缀最大匹配了 6 个(ababab),那次大匹配了多少呢?
容易看出次大匹配了 4 个(abab),更仔细地观察可以发现,次大匹配必定在最大匹配 ababab 中,所以次大匹配数就是 ababab 的最大匹配数!
直接去查算出的表,可以得出该值为 4。
第三大的匹配数同理,它既然比 4 要小,那真前缀和真后缀也只能在 abab 中找,即 abab 的最大匹配数,查表可得该值为 2。
再往下就没有更短的匹配了。
回顾完毕,来计算 ? 的值:既然末尾字母不是 z,那么就不能直接 6+1=7 了,我们回退到次大匹配 abab,刚好 abab 之后的 a 与末尾的 a 匹配,所以 ? 处的最大匹配数为 5。
上 Java 代码,它已经呼之欲出了:
// 构造模式串 pattern 的最大匹配数表
int[] calculateMaxMatchLengths(String pattern) {
int[] maxMatchLengths = new int[pattern.length()];
int maxLength = 0;
for (int i = 1; i < pattern.length(); i++) {
while (maxLength > 0 && pattern.charAt(maxLength) != pattern.charAt(i)) {
maxLength = maxMatchLengths[maxLength - 1]; // ①
}
if (pattern.charAt(maxLength) == pattern.charAt(i)) {
maxLength++; // ②
}
maxMatchLengths[i] = maxLength;
}
return maxMatchLengths;
}有了代码后,容易证明它的复杂度是线性的(即运算时间与模式串 pattern 的长度是线性关系):由 ② 可以看出 maxLength 在整个 for 循环中最多增加 pattern.length() - 1 次,所以让 maxLength 减少的 ① 在整个 for 循环中最多会执行 pattern.length() - 1 次,从而 calculateMaxMatchLengths 的复杂度是线性的。
KMP 匹配的过程和求最大匹配数的过程类似,从 count 值的增减容易看出它也是线性复杂度的:
// 在文本 text 中寻找模式串 pattern,返回所有匹配的位置开头
List<Integer> search(String text, String pattern) {
List<Integer> positions = new ArrayList<>();
int[] maxMatchLengths = calculateMaxMatchLengths(pattern);
int count = 0;
for (int i = 0; i < text.length(); i++) {
while (count > 0 && pattern.charAt(count) != text.charAt(i)) {
count = maxMatchLengths[count - 1];
}
if (pattern.charAt(count) == text.charAt(i)) {
count++;
}
if (count == pattern.length()) {
positions.add(i - pattern.length() + 1);
count = maxMatchLengths[count - 1];
}
}
return positions;
}最后总结下这个算法:
- 匹配失败时,总是能够让模式串回退到某个位置,使文本不用回退。
- 在字符串比较时,模式串提供的信息越多,计算复杂度越低。(有兴趣的可以了解一下 Trie 树,这是文本提供的信息越多,计算复杂度越低的一个例子。)
参考链接:(36 封私信 / 80 条消息) 如何更好地理解和掌握 KMP 算法? - 知乎
灵神题单:分享|如何科学刷题? - 力扣(LeetCode)
本站资源均来自互联网,仅供研究学习,禁止违法使用和商用,产生法律纠纷本站概不负责!如果侵犯了您的权益请与我们联系!
转载请注明出处: 免费源码网-免费的源码资源网站 » 灵神DAY3 KMP算法

发表评论 取消回复